Upgrade & Secure Your Future with DevOps, SRE, DevSecOps, MLOps!
We spend hours scrolling social media and waste money on things we forget, but won’t spend 30 minutes a day earning certifications that can change our lives.
Master in DevOps, SRE, DevSecOps & MLOps by DevOps School!
Learn from Guru Rajesh Kumar and double your salary in just one year.
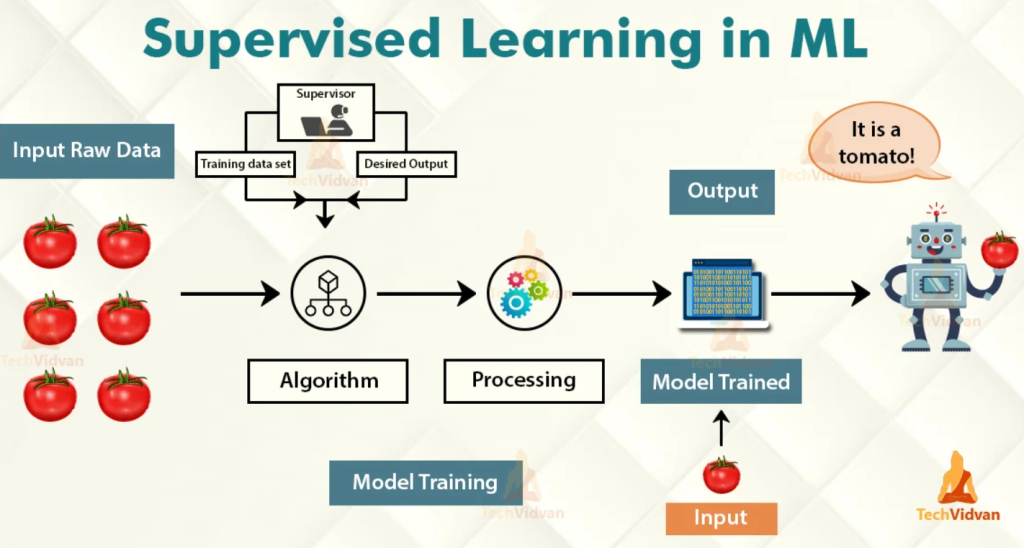
What is Supervised Learning?
Supervised learning is a type of machine learning where algorithms are trained on labeled data. This means that the data used to train the algorithm is already tagged with correct answers or classifications. Think of it as a student learning with a teacher who provides correct answers.
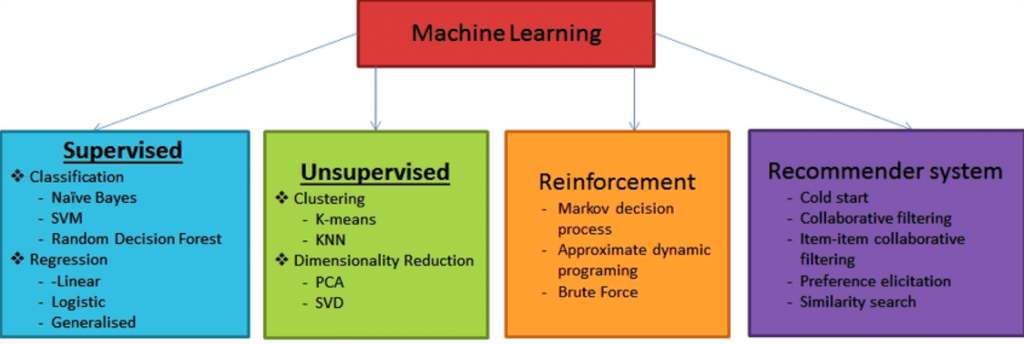
How does it work?
- Data Preparation: The first step involves gathering and preparing a dataset. This data should be representative of the problem you want to solve. For example, if you want to build a model to predict house prices, your dataset would include features like square footage, number of bedrooms, location, and the corresponding sale price.
- Model Selection: Choose a suitable algorithm based on the nature of your problem. Common algorithms include:
- Linear Regression: Predicts numerical values (e.g., house prices, stock prices)
- Logistic Regression: Classifies data into categories (e.g., spam or not spam, fraud or not fraud)
- Decision Trees: Creates a tree-like model of decisions and their possible consequences
- Random Forest: An ensemble method that combines multiple decision trees
- Support Vector Machines (SVM): Finds the best hyperplane to separate data points
- Model Training: The algorithm is trained on the labeled data. It learns to identify patterns and relationships between the input features and the output labels.
- Model Evaluation: The trained model is tested on a new dataset to assess its performance. Metrics like accuracy, precision, recall, and F1-score are used to evaluate the model’s effectiveness.
- Model Deployment: Once satisfied with the model’s performance, it can be deployed to make predictions on new, unseen data.
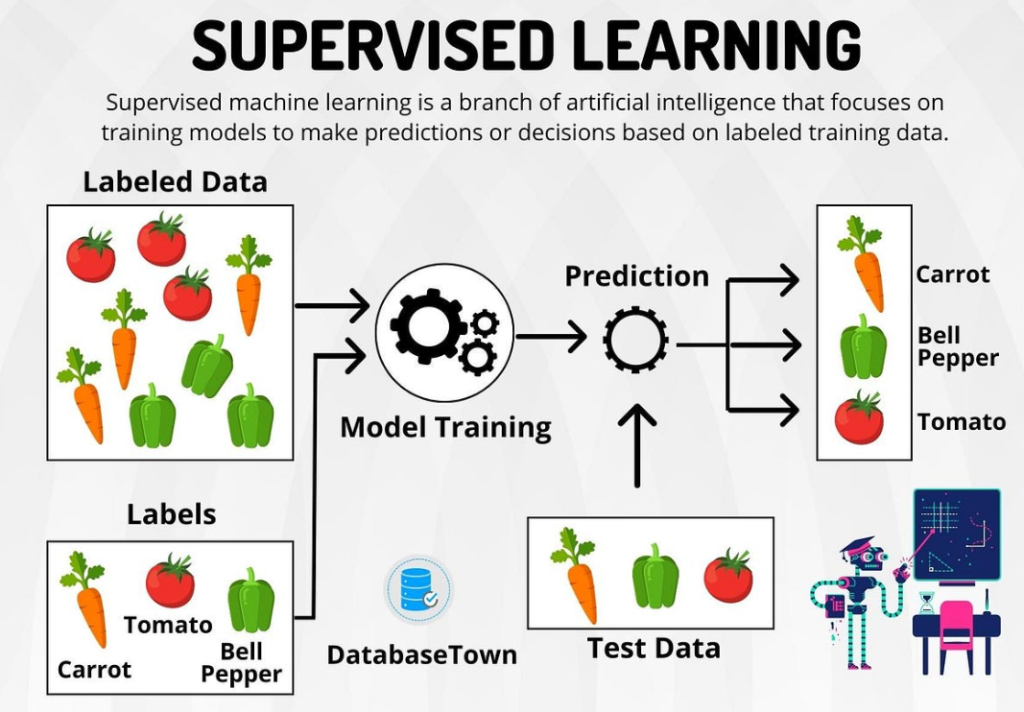
Types of Supervised Learning Problems
- Regression: Predicting a continuous numerical value (e.g., house prices, stock prices).
- Classification: Categorizing data into predefined classes (e.g., spam or not spam, fraud or not fraud).
Real-world Applications
Supervised learning has a wide range of applications across various industries:
- Image recognition: Identifying objects in images (e.g., facial recognition, self-driving cars).
- Spam filtering: Classifying emails as spam or not spam.
- Fraud detection: Identifying fraudulent transactions.
- Medical diagnosis: Predicting diseases based on patient data.
- Customer churn prediction: Identifying customers likely to leave a company.
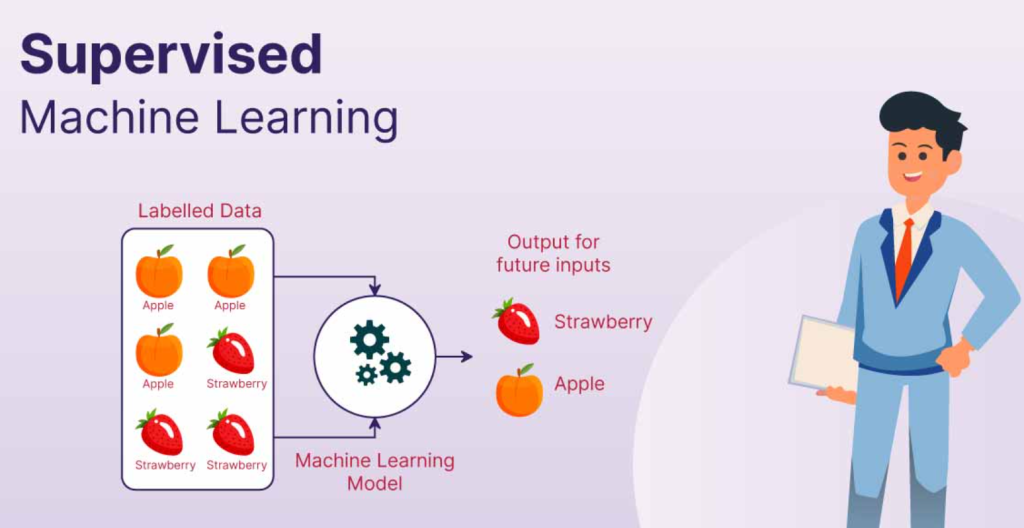
Conclusion
Supervised learning is a powerful technique for building predictive models. By providing labeled data, you can train algorithms to make accurate predictions on new data. While it requires careful data preparation and model selection, the potential benefits are immense.