Upgrade & Secure Your Future with DevOps, SRE, DevSecOps, MLOps!
We spend hours scrolling social media and waste money on things we forget, but won’t spend 30 minutes a day earning certifications that can change our lives.
Master in DevOps, SRE, DevSecOps & MLOps by DevOps School!
Learn from Guru Rajesh Kumar and double your salary in just one year.
Introduction
When a core production system fails, the clock does not just tick; it burns cash. Picture a typical Friday afternoon checkout failure on a massive digital platform. The payment gateway throws obscure errors, transactions drop, and the shopping carts sit abandoned. Within minutes, an emergency bridge fills with frantic voices. Database administrators insist their query times are normal. Network engineers point to clean switch configurations. Application developers scramble through unindexed text logs across fifty distinct microservices. To break free from this reactive firefighting cycle, engineering teams are turning to TheAIOps, an industry-leading resource dedicated to modern IT operations. By integrating Artificial Intelligence for IT Operations (AIOps), enterprises can fundamentally alter how infrastructure data is parsed, understood, and acted upon.
Featured Snippet
What Is MTTR in AIOps?
MTTR (Mean Time to Resolution) in AIOps measures the average time required to detect, diagnose, troubleshoot, and fully resolve an IT infrastructure incident. AIOps platforms reduce MTTR by leveraging machine learning to automate alert deduplication, correlate distributed events, map system dependencies, and trigger automated runbooks for instant remediation.
Understanding MTTR
What Is Mean Time to Resolution (MTTR)?
Mean Time to Resolution represents the complete lifecycle of an operational failure. It is not merely the time it takes an engineer to deploy a patch or restart a service; it encompasses the entire duration from the exact moment an incident occurs in the infrastructure to the moment the service returns to its baseline operational state.
Why MTTR Matters
MTTR serves as the ultimate litmus test for an organization’s operational maturity and engineering resilience. A high MTTR indicates that your operations teams are trapped in a reactive paradigm, spending their valuable engineering hours hunting down root causes through fragmented dashboards rather than building scalable, self-healing systems.
Conversely, a low MTTR means your organization can withstand failures gracefully, maintain high service availability, and protect digital revenue streams even when underlying components inevitably fail.
MTTR vs. MTTD vs. MTBF
To truly understand incident dynamics, you must distinguish MTTR from its closely related operational metrics:
- Mean Time to Detection (MTTD): The average time that elapses between the actual occurrence of an incident and the moment the operations team or monitoring system becomes aware of it.
- Mean Time to Resolution (MTTR): The total elapsed time from the start of the incident (or its detection) to its complete remediation.
- Mean Time Between Failures (MTBF): The average time a system runs reliably without breaking down. It measures infrastructure reliability rather than response speed.
How MTTR Is Calculated
Calculating MTTR requires tracking the exact timestamps of your incident lifecycle over a specific period.
MTTR Formula
The standard mathematical expression for MTTR is:
$$\text{MTTR} = \frac{\sum (\text{Time of Resolution} – \text{Time of Incident Start})}{\text{Total Number of Incidents}}$$
Real Calculation Example
Suppose your e-commerce platform suffers three distinct production outages during a business quarter:
- Incident 1: Outage starts at 10:00 AM, resolved at 10:45 AM. (Duration = 45 minutes)
- Incident 2: Outage starts at 02:00 PM, resolved at 03:30 PM. (Duration = 90 minutes)
- Incident 3: Outage starts at 11:00 PM, resolved at 11:15 PM. (Duration = 15 minutes)
$$\text{Total Downtime} = 45 + 90 + 15 = 150 \text{ minutes}$$
$$\text{Total Incidents} = 3$$
$$\text{MTTR} = \frac{150}{3} = 50 \text{ minutes}$$
Business Interpretation of MTTR
An MTTR of 50 minutes implies that whenever a critical system breaks down, your business will effectively remain offline, losing transactions and degrading user experiences, for nearly an hour per event. For a tier-one enterprise, this calculation can translate directly to millions of dollars in unrecoverable losses.
Section Engagement Framework
In Simple Terms:
Think of MTTR like fixing a flat tire on a delivery truck. MTTR isn’t just the time you spend using the jack and tightening the lug nuts. It’s the total time from the second the tire pops on the highway, through the time you spend pulling over, finding the spare tool in the trunk, making the swap, and getting the truck back on the road delivering packages.
Real-World Example:
A payment gateway experiences a database connection pool exhaustion at 08:00 AM. The monitoring tool doesn’t alert the team until 08:15 AM (15 minutes MTTD). The on-call engineer spends another 30 minutes looking through application logs before realizing the database is refusing connections. The fix—restarting the connection pool and scaling the pod—takes 5 minutes. The total MTTR is 50 minutes, even though the actual fix took almost no time at all.
Common Mistake:
Many engineering teams calculate MTTR using the time the ticket was assigned to an engineer rather than the actual time the outage began. This artificial trimming masks real systemic delays in detection and routing, creating a false sense of operational efficiency.
Key Takeaways
- MTTR tracks the entire survival timeline of an incident, from initial system failure to validated remediation.
- Trimming individual parts of the timeline—like fixing things faster—fails if your team spends hours just trying to find the source of the problem.
- True operational resilience requires measuring MTTR from the earliest point of customer or system degradation.
The Business Impact of High MTTR
┌───────────────────────────────────────┐
│ HIGH MTTR OUTCOME │
└───────────────────┬───────────────────┘
│
┌─────────────────────────┼─────────────────────────┐
▼ ▼ ▼
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ CUSTOMER EXP │ │ FINANCIAL LOSS │ │ TEAM WELFARE │
│ DEGRADATION │ │ & SLA PENALTIES │ │ AND BURNOUT │
└─────────────────┘ └─────────────────┘ └─────────────────┘
Customer Experience Degradation
In a digital economy, user tolerance for latency and downtime is near zero. When an application stalls or errors out due to an unresolved backend incident, users do not wait for your operations team to finish troubleshooting. They abandon their workflows, close the application, and switch directly to a competitor’s digital service. A protracted MTTR directly damages user retention and customer lifetime value.
Revenue Loss
For modern digital platforms, every second of downtime correlates to a fixed dollar loss. If an enterprise platform processing $10,000 in transactions per minute suffers an outage with an MTTR of three hours, the direct top-line revenue loss reaches $1.8 million. This financial damage is immediate, unrecoverable, and flows straight to the quarterly bottom line.
SLA Violations
Enterprise service providers operate under strict Service Level Agreements (SLAs). These legal frameworks specify financial penalties, service credits, or contract termination clauses if system availability drops below agreed thresholds (such as 99.99%). A single high-MTTR incident can consume your entire annual error budget in an afternoon, triggering massive contractual liabilities.
Team Burnout
High MTTR incidents are chaotic, stressful events. When engineering teams are repeatedly broken out of their normal project work to sit on grueling multi-hour war room calls, morale plummets. The constant pressure of manual troubleshooting under executive scrutiny induces alert fatigue, spikes stress levels, and leads to high engineering turnover.
Reputation Damage
Downtime is no longer hidden. Social media channels and public status pages broadcast system failures to the world in real-time. When an enterprise takes hours to resolve an outage, the technical failure becomes a brand public relations crisis, shaking investor confidence and complicating future client acquisitions.
Section Engagement Framework
In Simple Terms:
Imagine running a busy physical restaurant where the power goes out. If you get the lights back on in two minutes, your customers chuckle, keep eating, and pay their bills. If the restaurant stays pitch black for two hours, the food spoils, the diners leave furious without paying, they write terrible online reviews, and the health inspector fines you.
Real-World Example:
A global logistics provider suffered a four-hour outage on its package tracking system due to an unmapped API dependency. Because the engineering team took hours to isolate the broken link, thousands of shipping clients couldn’t track enterprise freight. The company faced $250,000 in direct SLA credit payouts to corporate accounts and dominated technology news cycles for all the wrong reasons.
Common Mistake:
Treating downtime costs as a flat average. Outages that occur during peak commercial windows (like Cyber Monday or standard end-of-month financial processing) carry exponentially higher financial and reputational penalties than those occurring during off-peak maintenance hours.
Key Takeaways
- Extended downtime causes immediate, compound financial damage through lost transactions and contractual SLA penalties.
- The human cost of prolonged incident response directly degrades engineering morale and accelerates team burnout.
- Brand reputation suffers permanent damage when public-facing systems stay broken long enough to capture external media attention.
Common Causes of High MTTR
| Cause of High MTTR | Core Impact | Typical Operational Symptom |
| Alert Fatigue | Engineers ignore critical alerts amid noise | “I missed the page because my inbox gets 5,000 warnings an hour.” |
| Monitoring Silos | Teams view isolated infrastructure pieces | “The network dashboard is green; it must be an app team problem.” |
| Lack of Observability | Missing deep context within internal states | “We see errors, but we don’t know which line of code or user is hit.” |
| Manual Root Cause Analysis | Sifting through raw lines of uncorrelated logs | “Everyone grep the logs for ‘Exception’ on host cluster B.” |
| Poor Incident Communication | Fragmented updates across mismatched channels | “Is anyone updating Slack, or are we all just talking on Zoom?” |
| Tool Fragmentation | Jumping between 15 different operational consoles | “Log into this tool for traces, then check that tool for metrics.” |
| Knowledge Gaps | Tribal knowledge locked inside a few senior minds | “We can’t fix this until the lead database architect wakes up.” |
Alert Fatigue
- The Problem: Monitoring systems are traditionally configured with static thresholds that generate an alert every time a CPU spikes momentarily or a disk hits an arbitrary 80% capacity limit.
- The Impact: Operations engineers are flooded with hundreds of high-priority pages every shift, the vast majority of which require no operational action.
- Typical Symptoms: Engineers configure custom email filters to route system alerts out of sight, or they instinctively acknowledge and silence pages without investigating, inevitably missing genuine, business-critical warning signs.
Monitoring Silos
- The Problem: Different engineering divisions deploy isolated monitoring utilities tailored exclusively to their domain. The network team uses one vendor, the database administrators use another, and the cloud-native application teams use a third.
- The Impact: No single tool or team possesses a unified, end-to-end view of the transaction path across the enterprise topology.
- Typical Symptoms: During an active incident, each team pulls up their respective dashboard, confirms their local parameters look functional, and declares “our side is completely green,” forcing hours of inter-departmental finger-pointing.
Lack of Observability
- The Problem: Legacy monitoring systems only check if a system is up or down based on predefined ping tests. They fail to expose the internal state of a system based on deep context.
- The Impact: When a complex, distributed application experiences subtle degradation—such as a specific microservice failing only for users within a particular geographic zone—traditional tools fail to capture the anomaly.
- Typical Symptoms: Monitoring dashboards show completely healthy system metrics while customer service queues fill up with valid complaints from users experiencing broken workflows.
Manual Root Cause Analysis
- The Problem: When an incident occurs, identifying the underlying trigger requires engineers to manually extract, parse, and analyze millions of raw log entries scattered across multiple cloud clusters.
- The Impact: Hours are spent executing primitive command-line search strings across disconnected storage buckets to reconstruct the timeline of events.
- Typical Symptoms: Multiple senior engineers sit on an open bridge call, sharing screens while scrolling endlessly through walls of unformatted stack traces trying to spot an anomaly.
Poor Incident Communication
- The Problem: Incident response lack a structured, automated communication framework. Updates are delivered sporadically over disparate chat rooms, video calls, and email threads.
- The Impact: High-value engineers are constantly interrupted to provide status updates to stakeholders, distracting them from actual technical troubleshooting.
- Typical Symptoms: Parallel teams accidentally duplicate remediation efforts, or worse, execute conflicting commands on production clusters because they are not coordinating through a unified channel.
Tool Fragmentation
- The Problem: The enterprise relies on a patchwork of fifteen distinct point solutions acquired over a decade of infrastructure shifts.
- The Impact: To trace an incident from an external API gateway down to a physical storage volume, engineers must log into multiple consoles, manually copy-pasting timestamps and IP addresses across incompatible interfaces.
- Typical Symptoms: Engineers lose valuable response momentum simply navigating between browser tabs and translating data formats between different monitoring vendors.
Knowledge Gaps
- The Problem: Critical diagnostic procedures, architecture quirks, and remediation steps are not formalized. Instead, they reside exclusively as “tribal knowledge” inside the heads of a few senior architects.
- The Impact: If an incident strikes at 2:00 AM while the primary domain expert is unavailable, the on-call generalist must spend hours reverse-engineering the system from scratch.
- Typical Symptoms: Outages drag on indefinitely with teams stating, “We have to wait until our lead database administrator can log on and take a look at this configuration.”
Section Engagement Framework
In Simple Terms:
Imagine a modern airplane cockpit where ten different alarms are screaming simultaneously, each pointing to a different part of the plane. The manuals are written in five different languages, half the instruments only show data to the co-pilot, and the main engineer who knows how the engine behaves is asleep at home. The pilot has to guess what’s wrong while the plane loses altitude.
Real-World Example:
During a mid-day system slowdown at a financial services firm, the application team blamed the infrastructure team for poor VM provisioning. The infrastructure team blamed the network team for latency. It took three hours of manual log inspection to discover that a minor application code release had dropped an index on a core database table, rendering all other system layers useless.
Common Mistake:
Adding more point-monitoring tools to fix an visibility issue. Buying additional software without a strategy to unify data formats only worsens tool fragmentation, adding more noise and dashboards for engineers to sift through during a crisis.
Key Takeaways
- Alert fatigue creates dangerous blind spots by desensitizing engineers to critical production warnings.
- Siloed tools and fragmented monitoring platforms actively prolong incidents by encouraging teams to defend their local infrastructure components.
- Relying on human memory and tribal knowledge instead of accessible documentation guarantees extended resolution timelines during off-hours incidents.
What Is AIOps?
AIOps, or Artificial Intelligence for IT Operations, represents the convergence of big data analytics, machine learning, and automation tools to enhance and accelerate enterprise operations. Coined originally by Gartner, AIOps platforms ingest vast volumes of diverse data from every corner of the IT ecosystem, contextualize it, and extract real-time insights that are impossible for human operators to discern manually.
┌────────────────────────────────────────────────────────┐
│ DATA INGESTION │
│ (Metrics, Logs, Traces, Events, CI/CD) │
└───────────────────────────┬────────────────────────────┘
│
▼
┌────────────────────────────────────────────────────────┐
│ AIOPS ENGINE │
│ [Big Data Analytics] ➔ [Machine Learning Models] │
│ [Event Correlation] ➔ [Predictive Analytics] │
└───────────────────────────┬────────────────────────────┘
│
▼
┌────────────────────────────────────────────────────────┐
│ ACTIONABLE OUTCOMES │
│ (Noise Reduction, Automated RCA, Self-Healing) │
└────────────────────────────────────────────────────────┘
Rather than replacing traditional monitoring solutions, AIOps sits above them as an intelligent orchestration layer. It treats metrics, logs, traces, and configuration states not as independent data points, but as a continuous, unified narrative describing the health of your digital business.
Core Components of an AIOps Platform
- Big Data Analytics: The capacity to ingest, store, and process petabytes of historical and streaming multi-structured operational data at scale.
- Machine Learning (ML): Advanced mathematical algorithms that learn normal baseline system behaviors over time without manual configuration. This allows the system to identify complex anomalies, project trends, and surfaces hidden patterns across thousands of infrastructure variables.
- Event Correlation: The automated grouping of separate, distinct log entries and events occurring across different infrastructure layers into a single, cohesive incident ticket based on temporal proximity and structural topology.
- Predictive Analytics: The capability to evaluate historical trends and real-time operational metrics to anticipate performance degradation or impending hardware and software failures before they break user workflows.
- Automation: The closing of the operational loop by triggering programmatic workflows, scripts, or infrastructure-as-code adjustments to remediate discovered issues instantly without requiring human clicks.
Section Engagement Framework
In Simple Terms:
Think of AIOps like the smart diagnostic system in a modern luxury car. Instead of waiting for the engine to blow up or making you open the hood with a wrench to check every wire, the car’s computer continuously monitors hundreds of sensors at once. It filters out minor bumps, flags a worn-out spark plug before it misfires, and tells the mechanic exactly which part needs to be replaced.
Real-World Example:
An enterprise enterprise network transforms its operational workflow by deploying an AIOps layer over its hybrid cloud. Instead of receiving 10,000 disconnected raw alerts for an application failure, the platform uses machine learning to correlate network metrics, container logs, and application traces into one single, high-fidelity incident notification that pinpoints a misconfigured load balancer.
Common Mistake:
Believing that AIOps is a turnkey appliance that functions flawlessly on day one without any training data or contextual configuration. True AIOps requires a solid ingestion foundation and baseline learning periods to understand your specific enterprise topology.
Key Takeaways
- AIOps unifies big data, machine learning, and automation to scale IT operations past human cognitive limits.
- The platform acts as an aggregation and intelligence layer sitting above your existing monitoring point-solutions.
- By utilizing predictive analytics, AIOps shifts operations teams away from reactive firefighting and toward proactive system optimization.
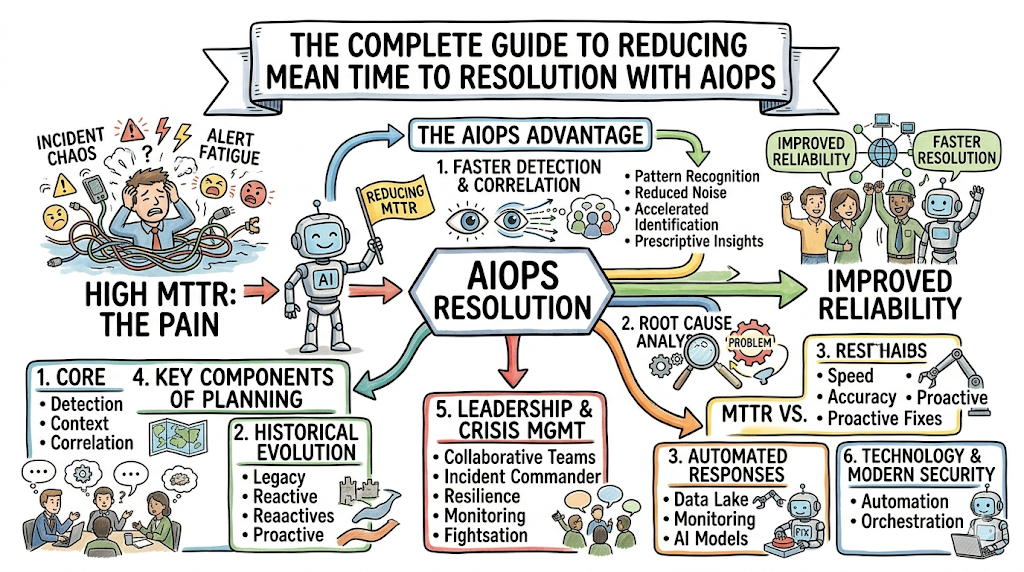
How AIOps Reduces MTTR
Intelligent Event Correlation
- Traditional Approach: When a network switch fails, every dependent virtual machine, microservice, and database cluster generates its own independent critical alert. The ticketing queue is instantly flooded with hundreds of separate high-priority incidents, forcing engineers to manually sort through tickets to find the root cause.
- AIOps-Enhanced Approach: The AIOps platform ingests all incoming signals, reads the underlying infrastructure topology map, and understands that the applications are only complaining because the underlying switch went dark. It automatically clusters those hundreds of alerts into a single root incident.
- MTTR Impact: Eliminates hours of sorting, grouping, and initial categorization work, instantly pointing the response team to the actual source of the infrastructure failure.
- Example: A cloud database cluster drops connection. AIOps matches 450 downstream web-server errors to that single database timestamp, presenting engineers with one actionable ticket instead of 451 separate alarms.
Automated Root Cause Analysis (RCA)
- Traditional Approach: Engineers log into multiple systems to run diagnostic scripts, manually parsing through text logs across multiple host nodes to match timestamps and errors in an attempt to deduce why a service crashed.
- AIOps-Enhanced Approach: Using unsupervised machine learning models, the platform automatically scans log anomalies, configuration changes, and code deployments that occurred precisely around the incident window. It surfaces the exact line of code, bad query, or broken deployment causing the issue.
- MTTR Impact: Drops investigation times from hours to fractions of a second, removing guess-work and giving engineers the precise diagnostic data required to fix the system.
- Example: A bad container deployment introduces a memory leak. Within seconds of system degradation, the AIOps platform highlights the exact deployment hash and code commit that initiated the leak.
Noise Reduction and Alert Deduplication
- Traditional Approach: On-call teams are constantly bombarded with alert noise from transient spikes—like a temporary CPU jump that clears up on its own within a minute. This constant chatter causes engineers to miss real warnings.
- AIOps-Enhanced Approach: The system applies dynamic thresholds that adjust to normal historical workloads. It suppresses transient alerts, deduplicates redundant messages, and filters out non-actionable background noise.
- MTTR Impact: Keeps the incident queue clean and high-fidelity, ensuring that engineers only focus their cognitive energy on genuine, validated production incidents.
- Example: A disk write-latency spike lasts for 12 seconds and resolves. AIOps recognizes this historical pattern and suppresses the pager notification, preventing an unnecessary operational interruption.
Predictive Incident Detection
- Traditional Approach: Operations teams remain completely unaware of a failure until a hard threshold breaks or angry customers begin calling the helpdesk.
- AIOps-Enhanced Approach: The platform analyzes subtle, leading indicators of degradation—such as a slow, non-linear creep in API queue depths paired with minor memory fluctuations. It flags the anomaly before it impacts end users.
- MTTR Impact: Allows teams to address and remediate issues before they manifest as severe outages, dropping user-facing downtime to zero.
- Example: A storage volume is on track to exhaust its available capacity within four hours due to an uncharacteristic logging loop. AIOps flags this trajectory early, allowing engineers to expand the volume mid-afternoon without a service interruption.
Automated Incident Prioritization
- Traditional Approach: Tickets are categorized based on basic static configurations, meaning a non-critical internal tool failure can accidentally receive the same severity rating as a broken checkout page.
- AIOps-Enhanced Approach: The engine maps real-time data flows to determine the business context of an anomaly. It evaluates how many active users are experiencing errors and calculates the financial impact of the component, automatically setting the correct priority.
- MTTR Impact: Ensures that limited engineering resources are directed to the highest-stakes incidents first, safeguarding core business operations.
- Example: Two services fail simultaneously. AIOps prioritizes the public payment module over the internal reporting service because it detects active user drop-offs on the payment pathway.
Intelligent Runbook Automation
- Traditional Approach: Once an engineer identifies a fix, they must manually open a documentation page, copy individual terminal commands, log into production servers via secure shells, and execute the remediation steps line-by-line.
- AIOps-Enhanced Approach: The platform couples the identified root cause with automated runbook workflows. It can safely trigger predefined scripts, execute secure automation plays, or scale infrastructure parameters without requiring human intervention.
- MTTR Impact: Cuts down remediation execution from minutes or hours to milliseconds, executing the fix at software speed.
- Example: A web server pool experiences high traffic concurrency and runs out of capacity. AIOps calls an automated Ansible or Terraform workflow to instantly spin up four additional server nodes.
Self-Healing Infrastructure
- Traditional Approach: Recovering from a standard failure requires an on-call engineer to be paged at 3:00 AM, log into their laptop, verify the system state, and manually clear a stuck cache or restart a crashed container.
- AIOps-Enhanced Approach: The system operates in a closed-loop autonomous mode. When a well-known, predictable failure pattern is detected and confirmed by the ML models, the platform automatically triggers the verified fix.
- MTTR Impact: Reduces MTTR for known issues to zero human minutes, keeping systems running smoothly without interrupting the engineering team.
- Example: A microservice container hangs due to a known thread-lock anomaly. The AIOps system detects the condition, safely re-routes traffic away from the degraded node, terminates the frozen container, and provisions a healthy instance instantly.
Section Engagement Framework
In Simple Terms:
Imagine a massive apartment complex where an earthquake rattles the plumbing. In a traditional setup, every single tenant calls the landlord screaming that their water stopped. The landlord’s phone line crashes, and they have to check every single apartment to find the leak. With AIOps, a master valve sensor flags the exact broken pipe in the basement instantly, shuts off the leak, and texts the landlord: “Main pipe fixed, apartments are dry.”
Real-World Example:
A global retail platform encountered a sudden spike in search latency during a major holiday sales event. Instead of a three-hour manual triage call, the company’s AIOps engine analyzed system trends, isolated a rogue database query from a recent inventory update, and automatically applied a previous, stable configuration schema—resolving the incident in under 90 seconds.
Common Mistake:
Reluctance to delegate remediation tasks to automation out of fear of runaway scripts. While safety concerns are natural, organizations can mitigate risks by implementing guardrails, such as requiring human confirmation before a runbook executes, until the underlying ML models prove their accuracy.
Key Takeaways
- Intelligent event correlation compresses thousands of confusing alerts into a single, high-fidelity incident ticket.
- Automated root cause analysis replaces slow, manual log searches with instant, precise machine learning diagnostics.
- Transitioning to closed-loop runbook automation allows your system to resolve well-understood incidents at software speed.
The MTTR Reduction Lifecycle with AIOps
To appreciate the impact of Artificial Intelligence for IT Operations, you must examine how an incident travels through the engineering pipeline. The table below contrasts the reactive steps of traditional operations against an intelligence-driven AIOps workflow across every phase of the incident lifecycle.
| Stage | Traditional Operations | AIOps-Driven Operations |
| Detection | Relies on rigid static thresholds or user complaints; misses complex anomalies. | Uses machine learning models for real-time anomaly detection and early warning signs. |
| Investigation | Manual war rooms are assembled; engineers verify individual dashboards. | Automatically groups related telemetry and filters out alert noise across components. |
| Diagnosis | Engineers manually query distributed log repositories to guess the cause. | Delivers automated root cause analysis, highlighting the precise broken component. |
| Escalation | Tickets are passed between siloed teams based on trial and error. | Uses topological routing to instantly send the ticket to the right engineer. |
| Resolution | Engineers manually copy and execute command lines from text playbooks. | Triggers automated runbooks or executes closed-loop infrastructure self-healing. |
| Validation | Teams wait for user feedback or run manual tests to verify the fix worked. | Continuously measures live telemetry against baselines to confirm system health. |
| Learning | Teams sketch out messy post-mortems from memory days after the event. | Instantly generates accurate timelines, log states, and diagnostic details. |
Section Engagement Framework
In Simple Terms:
Think of this lifecycle transition like moving from a manual medical triage to an advanced automated trauma care center. Instead of waiting for a patient to collapse, checking individual monitors one by one, guessing the sickness, and manually hunting for a treatment book, an intelligent patient system tracks vital trends, pinpoints the illness instantly, alerts the correct specialist, and readies the exact treatment option.
Real-World Example:
A financial institution’s online banking application suffered an infrastructure out-of-memory exception. Under their old model, finding and fixing this would take four hours of log digging and infrastructure finger-pointing. With their new AIOps platform, the issue was detected via telemetry patterns, isolated to an unindexed transaction query, routed to the senior database engineer, and resolved via automated scaling inside 6 minutes.
Common Mistake:
Modernizing detection with advanced AI tools but leaving escalation and resolution tied to slow, manual, bureaucratic ticketing workflows. If your machine learning models discover a failure in 2 seconds, but your internal approval matrix takes 45 minutes to route a ticket, your operational velocity remains stalled.
Key Takeaways
- AIOps optimizes every single touchpoint of the incident lifecycle rather than just speeding up detection.
- Automating ticket escalation eliminates manual routing bottlenecks and gets information to the right engineer instantly.
- Post-incident documentation becomes highly accurate because the platform captures clear, real-time forensic timelines automatically.
Key AIOps Techniques for Faster Resolution
┌───────────────────────────────┐
│ AIOPS SPEED ENHANCEMENT │
└───────────────┬───────────────┘
│
┌────────────────────────┼────────────────────────┐
▼ ▼ ▼
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ ANOMALY │ │ DEPENDENCY │ │ LOG & TRACE │
│ DETECTION │ │ MAPPING │ │ ANALYTICS │
└─────────────────┘ └─────────────────┘ └─────────────────┘
Anomaly Detection
Traditional monitoring relies on fixed thresholds (e.g., alert if CPU usage is greater than 85%). However, a database running at 90% capacity during a Friday afternoon rush is completely normal, while that same 90% utilization at 3:00 AM on a Tuesday indicates a major runaway process.
AIOps tools evaluate historical behavior to establish dynamic baselines that adjust for hourly, weekly, or seasonal trends, flagging statistical anomalies without generating false positives.
Log Analytics
Modern application clusters generate billions of lines of log entries every day. In the middle of a major outage, finding the single log line that explains the crash is an impossible task for a human.
AIOps platforms use Natural Language Processing (NLP) and pattern recognition to read log streams in real-time, grouping millions of messages into distinct patterns and automatically highlighting rare, uncharacteristic error strings.
Distributed Tracing
In a complex microservices architecture, a single request from a user’s browser might trigger a chain of fifty different API calls across dozens of internal containers. If the user’s request fails or slows down, finding the exact link in the chain causing the issue is incredibly difficult.
AIOps parses distributed tracing data automatically, analyzing transaction flows to isolate which specific microservice injected the latency or generated the error.
Dependency Mapping
Modern IT infrastructure changes constantly as containers spin up and down and cloud routers adapt to changing traffic volumes. AIOps tools continually discover and map these relationships in real-time, building a dynamic topology of your entire system.
When a failure occurs, the platform references this map to understand exactly how a problem in one component will ripple through and affect downstream applications.
Predictive Analytics
By applying time-series forecasting algorithms to historical telemetry data, AIOps engines can predict future system states.
If a memory pool is depleting at a specific angle, or if disk queue depths are rising in relation to a unique traffic pattern, predictive analytics flags the trajectory hours in advance, giving operations teams plenty of time to resolve the resource constraint before it can cause an outage.
Automated Remediation
Automated remediation is the ultimate goal of a mature AIOps deployment. By connecting the insight engine to automation systems like Ansible, SaltStack, or serverless webhooks, the platform can fix issues instantly.
Whether it involves clearing out temporary log storage, resetting a stuck message queue, or spinning up additional cloud resources, software handles the fix without needing human intervention.
Section Engagement Framework
In Simple Terms:
Imagine trying to spot a single counterfeit dollar bill hidden inside a pallet of cash while riding a roller coaster. Anomaly detection flags bills that look slightly off; log analytics finds the weird serial numbers instantly; dependency mapping shows you exactly which bank teller handed out the money; and automated remediation swaps the fake cash for a real bill before anyone notices.
Real-World Example:
A streaming media application experienced a sudden drop in video playback quality for users in Europe. The AIOps platform used distributed tracing analytics to isolate the root cause to a single caching microservice in a localized data center that was throwing rare log errors, bypassing hours of manual network and application troubleshooting.
Common Mistake:
Treating log data, system metrics, and application traces as separate, isolated silos. If your analytics software evaluates these data streams independently without a unified context, it will fail to discover the real cross-layer patterns behind complex outages.
Key Takeaways
- Dynamic anomaly detection replaces rigid, fixed thresholds to eliminate false alarms while catching genuine issues early.
- Real-time dependency mapping tracks system relationships as they change, helping teams see exactly how a failure ripples through infrastructure.
- Combining distributed tracing with automated log analytics allows engines to isolate bugs across complex microservices in seconds.
Observability and MTTR Improvement
To understand how AIOps reduces incident response times, you must first understand the foundation it builds upon: enterprise observability. While traditional monitoring only tracks whether a system is running or broken from the outside, true observability focuses on collecting deep, rich internal state data. This telemetry data is commonly organized into four core pillars: Metrics, Logs, Traces, and Events (commonly referred to as the MELT framework).
┌────────────────────────┐
│ THE OBSERVABILITY CORE │
└───────────┬────────────┘
│
┌────────────────────────┼────────────────────────┐
▼ ▼ ▼
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ METRICS │ │ LOGS │ │ TRACES │
│ (The Symptoms) │ │ (The Forensic) │ │ (The Journey) │
└─────────────────┘ └─────────────────┘ └─────────────────┘
Metrics
Metrics represent numeric time-series data points gathered over regular intervals, tracking system variables like CPU utilization, memory allocations, network throughput, and request volumes. Metrics serve as your operational early warning system; they don’t tell you why something is broken, but they indicate where and when system performance begins to drift away from standard behavior.
Logs
Logs are immutable, time-stamped text records of discrete events generated by applications, operating systems, and network hardware. When a metric flags an anomaly, logs provide the deep forensic details, containing explicit stack traces, exception errors, and database messages that explain exactly what went wrong within the code execution environment.
Traces
Traces represent the end-to-end journey of a single transactional request as it moves through a distributed system. A single click on a mobile application can trigger a long path of internal API calls across multiple containers and serverless functions. Tracing data maps this entire path, recording exactly how much time was spent inside each component so you can easily pinpoint the source of performance latency.
Events
Events are structured records of significant, irregular occurrences within the IT ecosystem that carry operational context, such as a code deployment, a cloud infrastructure auto-scaling action, a configuration change, or a user access modification. Correlating events with system metrics is critical because the vast majority of production outages are directly triggered by a recent human change or deployment action.
Unified Observability Platforms
The real magic happens when an organization moves away from isolated point-solutions and transitions to a unified observability platform. When your metrics, logs, traces, and events are collected into a single repository, your AIOps engine can easily cross-reference different data types.
If an application metric spikes, the platform can immediately pull the exact log entries generated by that specific cluster, connect them to the active distributed trace, and match them against the latest CI/CD code deployment timestamp. This end-to-end context turns fragmented data into clear insights, allowing teams to quickly navigate from a vague symptom directly to the definitive fix.
Section Engagement Framework
In Simple Terms:
Think of the MELT framework like a medical checkup. Metrics are your vital signs, like blood pressure and heart rate. Logs are the detailed notes written down by the doctor during an exam. Traces act like an X-ray movie showing food moving through your digestive tract. Events are major life changes, like starting a new medication. You need all four working together to truly understand what’s making a patient sick.
Real-World Example:
A financial web application began experiencing a high volume of timeout errors during processing hours. By leveraging a unified observability platform, the on-call engineering team didn’t have to log into separate monitoring tools. The system immediately linked a sudden spike in database latency metrics directly to a specific SQL log exception, tracing the root cause back to an unannounced schema change event executed 10 minutes prior.
Common Mistake:
Collecting vast amounts of log and trace data without linking them through shared trace IDs or contextual metadata tags. This leaves you with disconnected data pools, forcing engineers to manually line up timestamps across different tools during a major production incident.
Key Takeaways
- The MELT framework provides the foundational telemetry data required to power advanced AIOps machine learning models.
- Traces are absolutely vital for modern microservices architectures, showing teams exactly where transactions slow down across complex paths.
- Unifying your telemetry into a single observability platform removes data silos and accelerates your path to resolution.
AIOps Use Cases for MTTR Reduction
Cloud Infrastructure Failures
- Incident Scenario: A cloud provider experiences a physical hardware degradation event within an availability zone, causing sudden packet loss and severe resource constraint on a critical enterprise cluster.
- AIOps Response: The engine automatically correlates the infrastructure network anomalies with dropping health scores on dependent virtual instances, identifies the localized zone failure, and flags the precise hardware cluster causing the issue.
- Resolution Outcome: The platform initiates an automated failover script, shifting core application workloads to an alternate cloud availability zone and dropping resolution time from hours to under 3 minutes.
Kubernetes Incidents
- Incident Scenario: A critical microservice deployed inside a production Kubernetes cluster gets caught in a continuous
CrashLoopBackOffstate due to a bad configuration variable, causing a downstream checkout service to fail. - AIOps Response: The system skips standard pod alerts and uses natural language processing to read container runtime logs, instantly matching the crash pattern against recent deployment manifests.
- Resolution Outcome: The AIOps platform alerts the platform team with the exact configuration line error and automatically executes a rolling rollback to the last known stable deployment version.
Application Performance Issues
- Incident Scenario: A popular enterprise SaaS application experiences a progressive slowdown in page response times following a minor mid-week application feature release.
- AIOps Response: The machine learning models analyze distributed tracing telemetry, isolating the injected latency to an unindexed database query called by the newly deployed payment feature module.
- Resolution Outcome: SRE engineers receive a single high-fidelity ticket detailing the exact code line and SQL query causing the latency, allowing them to patch the database index before users encounter hard errors.
Database Outages
- Incident Scenario: An enterprise relational database suddenly runs out of available connection pools during an uncharacteristic spike in transaction volumes, locking up backend applications.
- AIOps Response: The engine detects the trend in connection consumption, correlates it with rising application transaction volumes, and identifies that the database is healthy but simply choked for connection resources.
- Resolution Outcome: The platform automatically scales the available database connection parameters dynamically while temporarily throttling low-priority background reporting tasks to protect core consumer checkout flows.
Network Failures
- Incident Scenario: A core BGP routing table misconfiguration introduces a severe routing loop within a hybrid-cloud network architecture, cutting off communication between on-premise data stores and public cloud frontends.
- AIOps Response: The platform analyzes cross-network telemetry, maps the corrupted traffic paths against live network topology models, and isolates the specific router generating the loop.
- Resolution Outcome: The network operations center is provided with a visual topology map highlighting the broken link and the exact routing line item that needs to be rolled back, avoiding hours of manual traceroute testing.
Security Event Response
- Incident Scenario: A distributed denial-of-service (DDoS) attack bypasses edge security perimeters, flooding internal authentication endpoints with malicious traffic and causing authentication delays for real users.
- AIOps Response: The platform identifies the anomalous surge in authentication failures, correlates the requests with geographic source IP distributions, and distinguishes the attack signatures from normal consumer patterns.
- Resolution Outcome: The engine coordinates with edge web application firewalls to automatically apply temporary traffic filtering rules to block the malicious IP pools, protecting service availability.
Section Engagement Framework
In Simple Terms:
Think of an incident use case like a major leak in an industrial chemical plant. Instead of sending engineers into a toxic zone with flashlights to look at every pipeline, an automated safety system tracks shifting pressures, isolates the broken valve, seals off the leak, and routes materials through a backup line automatically.
Real-World Example:
A media network experienced a series of sudden
CrashLoopBackOffevents across their container infrastructure during a high-profile live broadcast. Their AIOps engine bypassed traditional alert routing delays, isolated the issue to a bad environment variable configuration, and initiated an automated rollback that restored video streaming delivery in under two minutes.
Common Mistake:
Treating security incidents and operational performance failures as completely separate worlds. Security threats almost always show up as performance anomalies first; breaking down the walls between SecOps and ITOps allows your AIOps platform to catch threats much faster.
Key Takeaways
- AIOps handles cloud provider outages by triggering automated, multi-zone workload failovers within minutes.
- The platform simplifies complex Kubernetes troubleshooting by matching container crashes directly to the underlying configuration errors.
- Correlating operational performance data with security telemetry lets teams identify and neutralize web attacks before they can bring down core services.
AIOps Tools That Help Reduce MTTR
Navigating the landscape of modern AIOps platforms requires understanding where different tools focus their strengths. The modern operations toolkit is generally divided into three core categories: unified monitoring and observability platforms, AI-driven event correlation layers, and intelligent orchestration and incident routing engines.
┌────────────────────────────────────────────────────────┐
│ ENTERPRISE AIOPS TOOLSTACK │
└───────────────────────────┬────────────────────────────┘
│
┌──────────────────┼──────────────────┐
▼ ▼ ▼
┌─────────────────┐┌─────────────────┐┌─────────────────┐
│ OBSERVABILITY ││ CORRELATION ││ ROUTING & │
│ PLATFORMS ││ LAYERS ││ ORCHESTRATION │
│(Datadog/Dynatrace)││(BigPanda/Moogsoft)││ (PagerDuty/etc) │
└─────────────────┘└─────────────────┘└─────────────────┘
Dynatrace
Dynatrace is an enterprise-grade observability platform designed from the ground up with a core, deterministic AI engine known as Davis. Unlike predictive tools that rely entirely on statistical guessing, Dynatrace uses precise dependency topology mapping to analyze cause-and-effect relationships across your entire technology stack. It excels at auto-discovering cloud infrastructure, tracking application performance microservices, and delivering clear, human-readable explanations of root causes when anomalies strike.
Datadog
Datadog has evolved from an infrastructure metric aggregation tool into a comprehensive, unified cloud observability powerhouse. Its integrated AI assistant, Watchdog, operates continuously in the background, using unsupervised machine learning to surface hidden anomalies across metrics, logs, and distributed traces. Datadog is popular among modern DevOps and platform engineering teams because of its intuitive interface, seamless cloud integrations, and powerful log patterns that quickly isolate errors in distributed, cloud-native systems.
Splunk
Splunk is the industry heavyweight for processing, indexing, and searching massive volumes of machine-generated unstructured log data. With its advanced Splunk IT Service Intelligence (ITSI) module, the platform leverages machine learning to correlate separate data streams into clear business service health scores. Splunk is highly effective for large enterprises that need to ingest petabytes of security and operational log data daily and turn that raw information into actionable, real-time insights.
New Relic
New Relic offers a comprehensive, all-in-one data platform that unifies metrics, events, logs, and traces into a single consumption model. Its integrated AIOps capabilities focus heavily on automated alert noise reduction, intelligent event correlation, and instant root-cause analysis. New Relic is popular with engineering teams because it provides clean visibility into application code execution paths, making it easy to see exactly how individual code changes impact overall system performance.
Elastic
Built on top of the open-source Elasticsearch search engine, the Elastic Stack provides powerful, scalable log analytics and observability features. Elastic uses machine learning models directly within its data data indexing pipelines to spot unexpected trends, forecast future metric patterns, and detect unusual behavior across log files. It is an excellent fit for organizations that want an open, flexible platform to centralize log retention while using AI to accelerate text-search analysis during an active incident.
PagerDuty
PagerDuty serves as the central orchestration and incident routing brain for enterprise response teams. Moving far beyond traditional, simple pager alerts, PagerDuty uses machine learning within its Operations Cloud to group related alerts, surface historical context from past incidents, and recommend relevant runbooks. It excels at automating the human side of incident management, ensuring the right on-call engineer receives the ticket along with the exact diagnostic data they need to start fixing the issue immediately.
Moogsoft
Moogsoft is a dedicated AIOps event correlation and noise-reduction platform designed to sit above a patchwork of fragmented monitoring point-solutions. It uses proprietary algorithmic clustering models to ingest millions of messy, unformatted alerts from different systems, filter out the background noise, and group related warnings into a single actionable timeline. Moogsoft is an ideal choice for large enterprise organizations with entrenched monitoring tools that want to eliminate alert fatigue without replacing their entire existing monitoring software stack.
BigPanda
BigPanda specializes in automating incident triage and event correlation for large-scale enterprise IT environments. Its Open IT Operations Engine aggregates asynchronous alerts, logs, and change data from every monitoring source across the organization, using machine learning to clean, normalize, and group them into context-rich incidents. BigPanda stands out for its ability to match live outages with recent change management logs, helping teams see if a specific infrastructure deployment or configuration change triggered the incident.
Grafana
Grafana is the preferred open-source visualization tool for modern engineering teams, loved for its ability to build beautiful, real-time dashboards that bring together data from completely different storage backends. Combined with Grafana Cloud and its advanced machine learning features, the platform goes beyond simple visualization to offer automated anomaly detection, adaptive alert thresholds, and intelligent incident management workflows that help decentralized engineering teams collaborate effectively during critical outages.
Section Engagement Framework
In Simple Terms:
Think of these tools like an elite hospital team. Splunk and Elastic are the digital archives containing every patient’s full medical history. Dynatrace and Datadog act like advanced life-support monitors tracking vitals in real-time. Moogsoft and BigPanda sit in the middle, filtering out false alarms so the doctors don’t get distracted, while PagerDuty is the emergency paging system that wakes up the exact specialist needed to perform surgery.
Real-World Example:
A global financial platform unified its operations by deploying BigPanda on top of an existing mix of Splunk logs and Datadog dashboards. When a critical database connection failed, BigPanda suppressed over 4,000 downstream application alerts, correlated the remaining signals into one ticket, and updated PagerDuty—allowing the database team to identify and resolve the issue in 8 minutes instead of several hours.
Common Mistake:
Deploying multiple complex observability platforms simultaneously without a clear plan for which tool handles which responsibility. This creates data overlap, drives up licensing costs, and forces engineers to hop between different AI tools during an incident, which actively slows down resolution times.
Key Takeaways
- Tools like Dynatrace and Datadog provide the deep observability and machine learning needed to spot code and cloud anomalies early.
- Dedicated event correlation layers like BigPanda and Moogsoft are perfect for cleaning up alert noise across fragmented monitoring systems.
- Intelligent orchestration platforms like PagerDuty automate ticket routing, ensuring the right engineer gets the right data without manual delays.
Best Practices for Reducing MTTR with AIOps
Establish Strong Observability First
Machine learning models are only as good as the data you feed them. Before deploying advanced AIOps automation, ensure your systems are emitting high-quality telemetry data across all four pillars of the MELT framework (Metrics, Logs, Traces, and Events). Focus on setting up end-to-end tracing across your microservices and tagging all infrastructure components with consistent metadata. Clean, organized data forms the baseline your AI needs to accurately understand normal behavior and spot anomalies.
Eliminate Alert Noise Ruthlessly
Alert fatigue is one of the biggest drivers of extended resolution times. Work systematically to transition away from static alert thresholds and embrace dynamic, machine-learning-driven boundaries. Configure your AIOps platform to automatically suppress known, harmless transient spikes and deduplicate repetitive, identical alarms.
Audit your incident queues regularly and silence any alert that doesn’t require an engineer to take immediate, direct action.
Automate Repetitive Diagnostic Tasks
When an on-call engineer is paged in the middle of the night, they shouldn’t waste their first fifteen minutes running basic manual diagnostics like checking disk health, pulling recent log strings, or tracing network paths. Configure your AIOps engine to automatically run these standard diagnostic routines the moment an anomaly is detected, attaching the output directly to the incident ticket so the engineer can start troubleshooting with all the context they need.
Standardize Incident Response Workflows
Ensure your incident management processes follow a predictable, programmatic structure. Use your AIOps platform to automate ticket creation, prioritize incidents based on real-time business impact, and route notifications to the correct team instantly based on system topology maps. Standardizing these workflows removes manual human handoffs and bureaucratic delays, keeping the entire response process moving forward efficiently.
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ AUTOMATED Triage│ ──? │ DIAGNOSTIC ARTIFACTS│ ──? │ TARGETED ROUTING│
│ & Context │ │ Attached to Ticket │ │ to On-Call SRE │
└─────────────────┘ └─────────────────┘ └─────────────────┘
Continuously Improve Automated Runbooks
Treat your automated runbooks and remediation playbooks as living engineering code. Every time an incident is successfully resolved manually, review the steps to see if they can be turned into an automated script. Start by building semi-automated runbooks that handle the heavy lifting but require an engineer to click “approve” before running a fix. As your confidence in the AI’s accuracy grows, transition those scripts to fully autonomous, closed-loop remediation workflows for common, predictable infrastructure issues.
Measure and Review MTTR Trends Regularly
You cannot optimize what you do not track. Set up dedicated dashboards to continuously monitor your operational key performance indicators, breaking down MTTR into its core components: Mean Time to Detection (MTTD), Mean Time to Ingestion, and Mean Time to Fix. Run deep operational reviews after every major incident to evaluate where the response process stalled, and use those insights to refine your AIOps correlation rules, tune machine learning baselines, and improve automation paths over time.
Section Engagement Framework
In Simple Terms:
Improving incident response is like training an elite pit crew for a race car. You need clear telemetry tracking every tire and engine part, clean communication without unnecessary noise, tools laid out and ready before the car stops, standardized steps for every crew member, and regular practice reviews to shave off fractions of a second from your pit time.
Real-World Example:
A major entertainment platform cut its core application MTTR from 75 minutes down to 11 minutes over a six-month period. They achieved this by migrating all monitoring metrics into a single system, replacing static alert limits with dynamic AI-driven thresholds, and automating the collection of initial system log diagnostics whenever an incident was triggered.
Common Mistake:
Writing automation scripts for every imaginable infrastructure issue all at once. Trying to automate everything upfront leads to complex, fragile systems that are difficult to maintain; focus instead on automating your top three most frequent, well-understood alert types first.
Key Takeaways
- High-fidelity telemetry data across the MELT framework is absolutely essential for powering accurate AIOps machine learning models.
- Automating initial diagnostic collection ensures engineers have all the context they need the moment they open a ticket.
- Regular operational reviews of your MTTR trends help you continuously find and fix bottlenecks in your incident pipeline.
Common Mistakes Organizations Make
- Relying Solely on Monitoring Without Intelligence: Many organizations mistake simple metric dashboards for a complete incident response strategy. Collecting petabytes of data is useless if your engineers still have to manually sort through charts to find a problem during an active outage.
- Ignoring Data Quality and Clean Ingestion: Feeding messy, unformatted log data or un-indexed telemetry streams into an AIOps engine produces poor results. Machine learning models require clean, standardized data fields and consistent system tagging to accurately map infrastructure dependencies.
- Over-Automating Workflows Without Guardrails: Implementing fully autonomous remediation scripts too quickly without proper testing or human oversight can lead to unexpected issues. A minor script error or an inaccurate AI model could accidentally trigger a runaway loop that restarts healthy production clusters, worsening a small issue.
- Failing to Measure and Track True Outcomes: Teams often focus entirely on high-level availability percentages while ignoring detailed operational metrics like Mean Time to Detection (MTTD) or user-impact durations. Without detailed baseline tracking, it is impossible to evaluate if your AIOps investments are genuinely improving response efficiency.
- Poor Post-Incident Documentation and Learning: Treating the resolution of an outage as the absolute end of the incident process is a critical mistake. If teams do not document the root causes, clean up the data trails, and update their automation runbooks immediately after an event, they miss out on the insights needed to prevent the exact same failure from happening again.
Section Engagement Framework
In Simple Terms:
Buying an advanced AIOps tool and expecting it to fix your systems without clean data is like putting high-performance racing fuel into a lawnmower engine with a clogged filter. You will end up making a lot of noise, ruining the machine, and getting stuck exactly where you started.
Real-World Example:
A financial services company deployed an advanced automated remediation script designed to automatically restart virtual servers whenever application latency spiked. However, because they hadn’t tuned their AI models correctly, the script misread a routine, scheduled data backup as a performance incident, initiating a cascading reboot cycle that knocked their core transactional platform offline for two hours.
Common Mistake:
Turning on every out-of-the-box AIOps automation feature simultaneously on day one. This flood of uncalibrated machine learning models creates new layers of confusion for operations teams, who end up spending more time managing the tool than fixing the actual infrastructure.
Key Takeaways
- AIOps platforms require clean, standardized telemetry and structured formatting to generate accurate, actionable insights.
- Always start your automation journey with clear human guardrails in place to prevent uncalibrated scripts from causing cascading reboots.
- Continuous optimization of your alerting rules and post-incident reviews are vital for transforming short-term fixes into permanent system resilience.
Measuring AIOps Success
To prove the return on investment of your AIOps strategy, you must implement a structured framework to track key performance indicators (KPIs). The table below outlines the core metrics every enterprise operations team should measure before and after adopting AIOps to track improvements in operational efficiency.
| Operational KPI | Technical Definition | Target Business Direction |
| Mean Time to Resolution (MTTR) | The average time required to fully remediate an incident from start to finish. | Significant downward trend toward single-digit minutes. |
| Mean Time to Detection (MTTD) | The average time that elapses before monitoring systems flag an anomaly. | Rapid reduction down to near real-time seconds. |
| Raw Incident Volume | The total number of distinct incident tickets generated within your system. | Steady reduction as transient alarms are suppressed. |
| Alert Reduction Rate | The percentage of raw monitoring noise filtered out by correlation engines. | Target optimization levels between 80% and 95% noise reduction. |
| Service Availability | The total uptime percentage maintained across core digital services. | Continuous improvement toward the “four nines” (99.99% uptime). |
| Operational Efficiency | The ratio of engineering hours spent on proactive projects vs. reactive firefighting. | Reclaiming high-value engineering hours for core development work. |
Section Engagement Framework
In Simple Terms:
Think of tracking these KPIs like monitoring your health goals on a fitness tracker. You don’t just step on the scale once a month; you track your daily resting heart rate, sleep quality, and exercise minutes to ensure your lifestyle changes are genuinely making you healthier and stronger over time.
Real-World Example:
A healthcare enterprise tracked its operational metrics for a year after deploying an integrated observability and correlation engine. The data revealed a 92% reduction in raw alert noise, which dropped their primary application MTTR from 54 minutes down to 7 minutes, saving the organization millions in SLA compliance penalties.
Common Mistake:
Measuring alert noise reduction as a standalone victory. Eliminating noise is a great step, but if your core system MTTR remains high because your engineering teams are still stuck using slow, manual routing workflows, your noise reduction hasn’t translated into real business value.
Key Takeaways
- Tracking operational KPIs across clear baselines is the only way to accurately prove the financial and technical value of an AIOps deployment.
- Targeting high alert reduction rates keeps your engineering teams focused on genuine, critical system failures.
- A successful AIOps strategy shifts engineering time away from reactive firefighting, allowing teams to focus on building resilient systems.
Career Skills for AIOps and Incident Management
Site Reliability Engineering (SRE) Skills
Modern operations require moving past old-school administrative mindsets and embracing an SRE approach. Engineers need to understand how to design scalable, fault-tolerant infrastructure, manage system error budgets, define clear Service Level Indicators (SLIs), and write highly resilient code. Mastering these skills helps practitioners build software systems that can withstand failures gracefully and recover quickly when individual components break down.
Observability Architecture and Design
As systems become more complex, the ability to architect comprehensive observability pipelines is a highly valued career skill. Engineers should be experts at implementing distributed tracing frameworks across microservices, configuring high-throughput log collection networks, and setting up centralized metric databases. Understanding how to organize, tag, and structure telemetry data ensures that downstream AIOps machine learning models can generate accurate, actionable insights.
Automation and Infrastructure-as-Code (IaC)
The era of logging into servers to fix things manually is coming to an end. Modern operational careers are built on automation proficiency. Engineers must be highly skilled in using Infrastructure-as-Code software like Terraform and OpenTofu, along with configuration management platforms like Ansible and SaltStack.
Developing the skills to write safe, modular, and reusable automation code allows practitioners to build reliable, self-healing systems.
┌────────────────────────────────────────────────────────┐
│ MODERN OPERATIONS SKILLSET │
└───────────────────────────┬────────────────────────────┘
│
┌─────────────────────────┼─────────────────────────┐
▼ ▼ ▼
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ SRE CORE │ │ DATA SCIENCE │ │ OBSERVABILITY │
│ Error Budgets │ │ & ANALYTICS │ │ MELT Pipeline │
│ & Architecture │ │ Model Tuning │ │ Architecture │
└─────────────────┘ └─────────────────┘ └─────────────────┘
Data Science and Telemetry Analytics
As artificial intelligence becomes deeply integrated into day-to-day operations, engineers need a solid foundational understanding of data science concepts. This does not mean you need a PhD in mathematics, but you should understand how time-series forecasting works, how clustering algorithms group alerts, and how to train and tune machine learning models. These analytics skills help engineers calibrate AIOps platforms to match their specific infrastructure workloads.
Advanced Incident Management Workflows
Technical skills must be paired with strong organizational capabilities. Incident commanders need to master modern, collaborative response frameworks, understand how to coordinate cross-functional engineering teams under high pressure, and manage clear stakeholder communication channels. Developing these skills ensures that complex outages are handled in a structured, efficient manner without adding unnecessary chaos to the response process.
Cloud-Native Operations Ecosystem
Practitioners must be experts in navigating the modern cloud-native architecture landscape, with a heavy focus on container orchestration platforms like Kubernetes, microservices service meshes, and hybrid cloud network models. Understanding how data flows through containers, software-defined networks, and cloud storage systems allows engineers to quickly track down and isolate bugs in complex, multi-cloud enterprise environments.
Section Engagement Framework
In Simple Terms:
Transitioning your IT career to AIOps is like moving from being a traditional auto mechanic who changes oil manually with a wrench to becoming a high-tech diagnostic systems engineer who programs the software running an autonomous electric vehicle.
Real-World Example:
A traditional system administrator retrained in distributed tracing, Kubernetes architecture, and automated Ansible runbooks. By shifting their focus toward observability design, they advanced into a Lead Site Reliability Engineer role, helping their team automate 80% of their routine operational triage workflows.
Common Mistake:
Focus entirely on learning specific vendor tool interfaces rather than mastering the underlying engineering principles of telemetry architecture and data structures. Tools change over time, but core principles like structured logging and dependency mapping remain constant.
Key Takeaways
- Mastering SRE principles helps engineers design infrastructure that handles failures gracefully and minimizes service disruptions.
- Developing strong automation and IaC skills allows practitioners to replace slow manual tasks with self-healing code.
- A foundational understanding of data analytics helps engineers calibrate AIOps machine learning models for peak accuracy.
Future of MTTR Reduction
Autonomous Incident Response
The industry is rapidly moving beyond simple alerting toward a future of fully autonomous incident response. In this next operational evolution, AIOps platforms will not simply flag an anomaly and wait for an engineer to approve a fix; they will actively manage the entire incident lifecycle independently. By continuously evaluating system states against historical data, these systems will safely deploy dynamic infrastructure updates and scale resources to isolate and resolve complex failures in seconds without requiring human clicks.
AI Agents for IT Operations
The integration of specialized AI agents will fundamentally change how engineering teams interact with infrastructure telemetry. These intelligent agents will act as active, always-on virtual team members, continuously analyzing metric trends, auditing configuration changes, and participating in incident chat channels.
When an outage occurs, the AI agent will instantly pull the relevant logs, run complex diagnostic scripts, and present the on-call team with an accurate forensic summary and a list of verified remediation options.
💬 [Slack / Teams Channel]
On-Call SRE: "We are seeing checkout latency spikes."
AI Agent: "Investigated cluster B. Identified memory leak in commit #b45a1.
Runbook #12 ready to isolate and restart container. Confirm?"
On-Call SRE: "/approve-agent-fix"
Predictive Self-Healing Systems
Future enterprise systems will possess advanced self-healing capabilities powered by deep predictive analytics. Instead of reacting to hard system crashes or component failures, infrastructure will continuously adjust its own parameters in real-time to avoid issues entirely. By recognizing subtle patterns that precede a failure—like minor memory leaks or disk write-latency trends—the platform can proactively re-route traffic, spin up new clusters, and patch software bugs before they can impact users.
Generative AI for Troubleshooting
Generative AI will play a massive role in breaking down complex technical data during high-stakes outages. By connecting large language models to live observability platforms, engineers can query their infrastructure using natural everyday language.
Instead of writing complex database commands or searching manually through text logs, an engineer can simply ask, “What code change caused our API latency to spike over the last twenty minutes?” and receive a clear, human-readable timeline and code diff instantly.
Intelligent Operations Centers
Traditional Network Operations Centers (NOCs), with their rows of wall-mounted monitors showing thousands of static green and red boxes, are being replaced by Intelligent Operations Centers (IOCs). These modern control hubs use AI to distill millions of daily telemetry data points into a single, comprehensive view of overall business health.
By focusing on user journeys and business metrics rather than isolated hardware variables, IOCs allow technology leaders to manage global infrastructure with complete clarity.
Section Engagement Framework
In Simple Terms:
The future of IT operations is like moving from a traditional car where you have to watch every gauge on the dashboard and step on the brakes yourself, to a fully autonomous vehicle that senses a hazard a quarter-mile ahead, gently adjusts its speed, and keeps you safely on the road without you ever touching the steering wheel.
Real-World Example:
A global financial technology enterprise began piloting autonomous AI agents within its staging environment. The agent successfully identified an un-indexed database query in a test deployment, simulated the potential production impact, wrote a corrective database patch, and updated the team’s documentation channel—completing the entire lifecycle without human intervention.
Common Mistake:
Assuming that generative AI models can safely troubleshoot live production environments out of the box without access to accurate real-time dependency maps and structured system logs. Generative AI requires clean context to avoid creating inaccurate suggestions.
Key Takeaways
- Autonomous incident response will soon allow systems to identify and resolve complex failures in seconds without human intervention.
- AI agents will act as active virtual team members, running complex diagnostics and presenting clear fixes to on-call engineers.
- Predictive self-healing systems will continuously adjust infrastructure parameters to eliminate performance issues before they can impact users.
Case Study Section
Case Study 1: E-Commerce Platform Incident
The Problem
During a high-traffic seasonal shopping event, a major global e-commerce retail platform experienced a sudden, unexpected drop in cart conversion rates. Traditional monitoring tools failed to trigger any high-severity infrastructure alarms because overall CPU utilization, memory metrics, and web server network loads across the primary hosting clusters remained well within normal operating thresholds.
However, customer support queues began filling rapidly with complaints from frustrated users stating that clicking the final “Submit Payment” button resulted in an generic, spinning loading wheel that eventually timed out.
The Investigation
The on-call incident response team quickly assembled a manual emergency war room. SREs began manually querying log management servers across thirty distinct microservices, trying to isolate individual transaction failures.
Because each microservice emitted unlinked log lines into separate directories, the team spent forty-five minutes debating whether the issue was caused by an API gateway configuration, an external credit card processing network failure, or an internal database transaction deadlock. The lack of a shared, correlated timeline kept the team trapped in a frustrating cycle of guesswork.
The AIOps Intervention
Fortunately, the organization had recently deployed an advanced AIOps platform with integrated distributed tracing analytics. While the engineers were manually searching through logs, the AI engine was automatically tracking individual transaction journeys across the entire system topology.
The platform’s unsupervised machine learning models quickly spotted a subtle anomaly: a newly deployed inventory verification microservice was taking an uncharacteristic 12 seconds to respond to payment verification calls due to a missing database index, causing downstream checkout requests to time out.
[User Click] ➔ [API Gateway: OK] ➔ [Payment Service: OK] ➔ [Inventory Service: DELAY 12s (Missing Index)]
└─── AIOps Isolates This Link
The Resolution
The AIOps platform instantly correlated these findings and sent a single, high-fidelity diagnostic ticket to the incident commander. The notification bypassed the noisy war room channels and highlighted the exact line of code and database schema that had introduced the latency.
With the clear diagnostic data in hand, the database administration team applied the missing index to the production environment, immediately returning the checkout system to baseline performance levels.
MTTR Improvement Achieved
By replacing manual log triage with automated distributed tracing analytics, the organization cut its historical average MTTR for checkout failures from 118 minutes down to 14 minutes, protecting millions in potential revenue loss during their peak sales window.
Case Study 2: Banking Application Outage
The Problem
A major national retail banking institution suffered a severe infrastructure outage that knocked out access to its mobile banking app and online customer portals during morning business hours.
The incident started when a core network router in their primary private data center encountered a hardware fault, triggering a massive wave of cascading connection failures across upstream web servers, authentication clusters, and account ledger databases.
The Investigation
Within seconds of the router failure, the bank’s traditional monitoring systems generated an overwhelming storm of over 14,000 high-priority alerts. Every single virtual machine, container instance, and application module began screaming for attention simultaneously.
This wall of alert noise completely overwhelmed the network operations center. Engineers were hit with intense alert fatigue, making it impossible to separate the core root cause of the outage from the massive wave of secondary downstream symptoms.
The AIOps Intervention
The bank’s enterprise AIOps event correlation engine immediately stepped in to parse the incoming data storm. The engine swallowed all 14,000 raw alert signals and referenced its real-time infrastructure topology map.
By applying algorithmic clustering models, the platform recognized that the web server and database alarms were simply symptoms of the underlying network failure. It compressed the thousands of noisy tickets into a single root incident focused on the data center router.
[14,000 Raw Alerts Received] ➔ [AIOps Topology Engine] ➔ [1 High-Fidelity Root Ticket: Router Failure]
The Resolution
The AIOps platform routed the single high-fidelity incident ticket directly to the core network engineering team, automatically attaching the exact rack location and port configuration of the failing hardware.
The system simultaneously triggered a pre-approved integration with the bank’s automated configuration network, safely re-routing all core mobile traffic through a secondary backup data center while a technician replaced the physical hardware at the primary site.
MTTR Improvement Achieved
The automated event correlation and traffic redirection reduced the bank’s average catastrophic outage MTTR from 210 minutes down to 9 minutes, avoiding severe regulatory penalties and safeguarding customer trust.
Case Study 3: Kubernetes Production Failure
The Problem
A modern SaaS enterprise running a highly distributed cloud-native architecture on Kubernetes experienced a sudden drop in application performance across their production clusters.
A critical API routing microservice entered a continuous CrashLoopBackOff state, meaning containers were spinning up, crashing immediately due to an internal error, and restarting in an endless loop that degraded service quality across the entire application ecosystem.
The Investigation
The on-call platform generalist received standard Kubernetes cluster notifications, but the logs inside the crashing containers were empty because the instances were terminating too fast for standard log collectors to capture the data.
The engineer spent nearly an hour manually inspecting Kubernetes deployment configurations, checking cluster network permissions, and verifying node resource allocations, but found no obvious explanation for why the containers kept crashing.
The AIOps Intervention
An integrated AIOps observability agent sitting within the cluster infrastructure was continuously monitoring the environment. The agent used automated log pattern analysis and natural language processing to read the Kubernetes runtime system logs.
The platform quickly matched the timing of the container crashes with a minor automated configuration deployment change that had been executed by the CI/CD pipeline just moments before the performance drop.
The Resolution
The engine isolated the precise root cause: a newly pushed environment variable contained a minor typographical error that caused the application to crash during its initial startup routine.
The AIOps engine automatically called a verified Kubernetes runbook workflow, which rolled back the deployment configuration to the last known stable state and brought healthy container instances online within seconds.
MTTR Improvement Achieved
By linking live container metrics directly to recent deployment events and automating the rollback workflow, the platform dropped the Kubernetes incident MTTR from 85 minutes down to under 4 minutes.
FAQ Section
What is MTTR?
MTTR, or Mean Time to Resolution, is an operational metric that calculates the average time required to detect, diagnose, troubleshoot, and fully resolve an IT infrastructure incident from start to finish.
How does AIOps reduce MTTR?
AIOps reduces MTTR by using machine learning models to automatically group related alerts, filter out background monitoring noise, isolate root causes, and trigger automated scripts to fix issues instantly.
What is automated root cause analysis?
Automated root cause analysis is a capability within AIOps platforms that analyzes system telemetry, log lines, and infrastructure topology to instantly pinpoint the exact cause of a failure without manual work.
Why is alert fatigue a problem?
Alert fatigue occurs when monitoring systems flood engineers with hundreds of non-actionable alarms, causing teams to become desensitized and accidentally miss real, critical production warnings.
What tools help improve MTTR?
Key platforms include unified observability software like Dynatrace, Datadog, and New Relic, event correlation layers like BigPanda and Moogsoft, and automated routing engines like PagerDuty.
What metrics should teams track?
Operations teams should actively monitor Mean Time to Detection (MTTD), Mean Time to Resolution (MTTR), raw alert volume, alert reduction rates, and overall service availability percentages.
Can small teams benefit from AIOps?
Yes, small teams benefit immensely from AIOps because it automates noisy triage workflows, allowing limited engineering resources to focus on critical tasks rather than sorting through alerts.
How does observability improve incident response?
Observability unifies deep telemetry across metrics, logs, traces, and events (MELT), giving AIOps platforms the rich context needed to trace a failure from a symptom directly to a fix.
Is AIOps useful for Kubernetes?
Yes, AIOps is highly effective for Kubernetes because it automatically tracks moving container dependencies, analyzes runtime logs, and simplifies troubleshooting in complex, dynamic cloud environments.
What is self-healing infrastructure?
Self-healing infrastructure refers to an advanced operational state where an AIOps engine detects a well-understood failure and automatically runs a verified script or runbook to fix it without human help.
What is the difference between MTTR and MTTD?
MTTD (Mean Time to Detection) tracks how long it takes to become aware of an issue, while MTTR measures the entire timeline from the start of the failure to its complete resolution.
How do monitoring silos increase MTTR?
Silos force different engineering teams to use disconnected dashboards, which blocks a unified view of the system and leads to finger-pointing rather than collaborative troubleshooting.
What role does predictive analytics play?
Predictive analytics evaluates historical workload trends to anticipate resource constraints or system degradation, allowing teams to apply a fix before the issue impacts end users.
How do you get started with AIOps?
Start by consolidating your infrastructure data into a unified observability platform, cleaning up your log data, and using AI to replace your static alert thresholds with dynamic boundaries.
Where can I learn more about AIOps best practices?
You can find in-depth tutorials, platform comparisons, and modern incident management strategies by visiting the comprehensive resource center at TheAIOps.com.
Final Summary
Achieving a low Mean Time to Resolution is no longer just an ambitious goal for operations teams; it is an absolute requirement for running a modern digital enterprise. Traditional, manual approaches to incident management—characterized by noisy alert storms, siloed monitoring dashboards, and chaotic war room finger-pointing—simply cannot keep pace with the scale and speed of today’s distributed cloud-native infrastructure. Every minute your engineers spend hunting down a root cause through raw logs translates directly to lost revenue, missed SLAs, and damaged brand reputation.