Upgrade & Secure Your Future with DevOps, SRE, DevSecOps, MLOps!
We spend hours scrolling social media and waste money on things we forget, but won’t spend 30 minutes a day earning certifications that can change our lives.
Master in DevOps, SRE, DevSecOps & MLOps by DevOps School!
Learn from Guru Rajesh Kumar and double your salary in just one year.
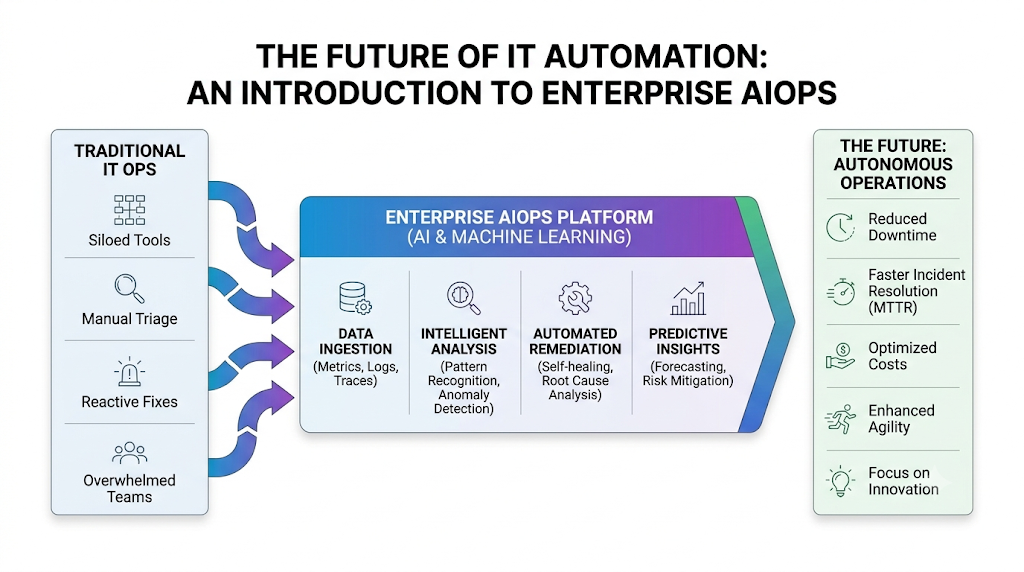
Introduction
Modern enterprise IT environments are expanding at a breakneck pace. Microservices architectures, hybrid cloud deployments, and continuous delivery models generate volumes of telemetry data that exceed human capacity to analyze. When systems break, finding the root cause amid thousands of disconnected alerts becomes a monumental task. For large-scale organizations, traditional infrastructure monitoring tools are no longer sufficient. Operational blind spots lead to prolonged outages, high mean time to resolution (MTTR), and burnt-out engineering teams. This reality makes Scaling AIOps in Large Enterprises a core strategic imperative rather than an optional tech upgrade. To explore deeper industry frameworks, technical blueprints, and continuous updates on artificial intelligence within operations management, visit TheAIOps.com. This guide breaks down the core architectures, challenges, and actionable strategies needed to scale AIOps horizontally. You will learn how to design an enterprise-grade data foundation, unify your distributed operations groups, and establish governance patterns that sustain intelligent IT automation.
3. Understanding Enterprise AIOps
Enterprise AIOps (Artificial Intelligence for IT Operations) refers to the deployment of machine learning, big data architectures, and advanced analytics pipelines to automate incident detection, correlation, and resolution across an organization’s entire technology stack. At its core, it converts raw telemetry into structured, contextual insight.
Core Principles of AIOps
- Data Aggregation: Centralizing disparate streams of metrics, open-source logs, traces, and API events into a unified system.
- Algorithmic Analysis: Applying statistical models and anomaly detection algorithms to separate normal operating variance from actual system failures.
- Contextual Correlation: Grouping related alerts based on topological relationships, infrastructure dependencies, and time windows.
- Automated Action: Triggering self-healing workflows, diagnostic scripts, or ticketing updates without manual intervention.
[Metrics, Logs, Traces] ──> [Algorithmic Analysis] ──> [Contextual Correlation] ──> [Automated Action]
Enterprises invest heavily in enterprise AIOps because manual incident management cannot keep pace with modern digital transformation initiatives. As business units migrate to cloud-native platforms, infrastructure changes happen in milliseconds. AIOps bridges this visibility gap by transforming raw observability data into definitive operational intelligence, ensuring that digital services remain highly resilient.
4. Why Scaling AIOps Is Different from Initial Adoption
Transitioning from a localized AIOps proof-of-concept (POC) to a large-scale AIOps deployment changes the nature of the challenge from a technical configuration exercise to a complex architectural and cultural shift.
Organizational Complexity
In a localized deployment, a single engineering team manages its own data sources and model training. At scale, an AIOps platform must serve diverse stakeholder groups—ranging from traditional Network Operations Center (NOC) analysts to modern Site Reliability Engineering (SRE) squads, cloud infrastructure architects, and compliance officers. Each team requires unique views, access controls, and contextual groupings.
Data Volume Growth
When scaling horizontally, data ingestion grows exponentially. An enterprise stack processing billions of events per day across multi-cloud environments can easily saturate analytical pipelines. Managing ingestion costs, storage tiers, and model processing latency requires specialized data-routing architectures.
Distributed Governance
A local script can run with simple access keys. An enterprise automation loop requires explicit safety guardrails. Without standardized governance frameworks, cross-team deployments encounter friction regarding access rights, compliance audits, and architectural consistency.
5. Common Challenges When Scaling AIOps
Data Silos
Large enterprises are naturally divided into business segments that use separate tools. The database administrators use one monitoring system, the cloud team uses another, and application engineers rely on completely distinct tracing tools. Because these data pools do not interact, the machine learning models cannot build an end-to-end map of infrastructure dependencies.
Example: During a major checkout outage at a global retailer, the database team sees normal CPU levels on their dashboard, while the frontend application team logs a spike in timeout errors. Because their monitoring data streams are siloed, the AIOps platform cannot correlate the backend storage connection pool exhaustion with the frontend failure.
Alert Overload
Unscaled AIOps systems often default to aggressive threshold configurations. When hundreds of applications dump uncurated telemetry into an unconfigured ML engine, the platform outputs an overwhelming volume of false-positive anomalies, leading directly to alert fatigue.
Tool Sprawl
The average Fortune 500 company runs over twenty distinct monitoring and analytics tools. This sprawl fragments visibility and creates integration nightmares when building a cohesive AIOps implementation strategy.
Integration Complexity
Connecting legacy mainframes, on-premises virtualization hosts, and modern serverless clusters to a central AIOps platform requires a complex mix of custom APIs, open-source collectors, and proprietary agents. Maintaining these connections through regular system updates consumes significant engineering time.
Skills Gaps
Traditional IT operations engineers excel at manual troubleshooting and systems administration, but AIOps demands comfort with data science concepts, statistical models, and infrastructure-as-code automation workflows.
Change Management Resistance
Engineers are naturally skeptical of automated remediation. If an enterprise tries to scale automated actions too quickly, teams frequently disable the automation out of fear that a misconfigured script might worsen a live production incident.
6. Best Practices for Scaling AIOps in Large Enterprises
Establish a Clear AIOps Strategy
Do not treat AIOps as a drop-in software utility. Define clear operational milestones that map directly to business metrics, such as reducing major incident frequency or lowering operational overhead. Document which platforms will be integrated first, who owns model maintenance, and how success will be audited.
Build a Strong Data Foundation
Clean, standardized data is critical for accurate machine learning models. Implement a strict schema for all logs, metrics, and traces across the enterprise. Use telemetry pipelines to clean, filter, and tag inbound data before it hits your analytical storage layers.
Standardize Monitoring and Observability
Consolidate fragmented toolsets around an enterprise observability framework. Mandate that all deployed services export core telemetry using open standards like OpenTelemetry. This ensures a predictable, uniform stream of telemetry data for your machine learning models to ingest.
Prioritize High-Impact Use Cases
Avoid attempting to automate everything at once. Begin your scaling efforts by targeting high-volume, low-risk operational patterns that consume significant engineering time.
| Use Case Category | High-Impact Enterprise Focus | Direct Operational Benefit |
|---|---|---|
| Noise Reduction | Intelligent alert clustering and deduplication | Drops actionable alert volume by 60-80% |
| Root Cause Analysis | Automatic topological dependency mapping | slashes diagnostic time during major incidents |
| Capacity Management | Predictive cloud-compute and storage auto-scaling | Lowers cloud infrastructure spending by 20-30% |
Implement Intelligent Automation Gradually
Build user trust by introducing automation in progressive stages. Start by configuring the system to gather diagnostics when an issue occurs and attach that data to a human-reviewed ticket. Once that stage works consistently, transition to automated remediation within non-production environments before moving into production.
Develop Governance Frameworks
Establish an AIOps Center of Excellence (CoE) to set access policies, manage model drift, and audit automated routines. This group ensures that all automations comply with internal safety, data privacy, and regulatory controls.
Promote Cross-Team Collaboration
Bridge the gap between data scientists and operations engineers. Set up cross-functional workshops where system administrators can help refine ML alerting logic, ensuring models reflect real-world infrastructure behavior.
Continuously Measure Outcomes
Track clear business indicators alongside technical telemetry. If alert volumes drop but system availability stagnates, re-evaluate how your correlation engines prioritize severity levels.
7. Building an Enterprise AIOps Architecture
Scaling horizontally requires a modular architectural framework capable of decoupled data processing.
The operational data pipeline flows through six distinct functional layers:
- Data Ingestion Layer: Uses scalable streaming platforms to capture high-velocity metrics, system logs, application traces, and configuration changes from across your multi-cloud estate.
- Observability Platform: Acts as the high-performance storage layer, organizing raw telemetry into real-time time-series indices and searchable cold-storage tiers.
- Machine Learning Engine: Runs unsupervised anomaly detection, log clustering, and pattern matching models across incoming telemetry streams to surface hidden system trends.
- Event Correlation System: Analyzes infrastructure topology maps to group isolated alerts into singular, context-rich incident incidents.
- Automation Framework: Triggers runbooks, provisions resources, or interacts with webhooks to resolve verified system anomalies automatically.
- Reporting and Dashboards: Provides tailored executive views and engineering interfaces to track operational health and platform accuracy.
Key Metrics for Measuring AIOps Success
To justify a large-scale AIOps deployment, organizations must track specific key performance indicators (KPIs) focused on operational efficiency and system stability.
- Mean Time to Detection (MTTD): Measures how long it takes the AIOps platform to register an anomaly after an issue starts. A successful rollout typically drops MTTD from hours to minutes.
- Mean Time to Resolution (MTTR): The time required to fix a production failure. AIOps reduces this metric by providing instant root-cause analysis and automated runbook execution.
- Alert Reduction Rate: The percentage of duplicate or low-priority alerts filtered out by your correlation engine. High-performing deployments routinely achieve a reduction of 75% or greater.
- Automation Coverage: The ratio of system incidents resolved or mitigated by automated workflows compared to those requiring human engineering intervention.
- Service Availability: Total uptime across critical digital services, often tracked via Service Level Objectives (SLOs).
- Operational Cost Savings: The measurable financial return achieved by optimizing cloud resources, preventing major SLA penalties, and reducing manual troubleshooting hours.
Real-World Enterprise Use Cases
Global Financial Services
A tier-one bank scaled its AIOps framework across ten core banking applications processing millions of daily transactions. By correlating payment gateway metrics with database connection pools, the bank eliminated manual triage bridges during peak market hours, lowering its critical incident MTTR by 65%.
Telecommunications Networks
A global telecom operator implemented an AIOps implementation strategy across thousands of cell towers and core data centers. The platform analyzes real-time signal telemetry and hardware alerts, predicting equipment failures up to 12 hours before they cause customer drops. This allows field engineers to perform preventive maintenance during off-peak windows.
Healthcare Systems
A regional healthcare network deployed an AIOps platform to monitor patient-portal APIs and EHR electronic health record databases. The system detects micro-spikes in database locking times, automatically scaling container resources to prevent system slowdowns for hospital staff.
Retail and E-Commerce Platforms
During high-traffic shopping holidays, a multi-national retailer scales its AIOps engines to monitor cloud infrastructure constraints. The platform uses predictive resource optimization to adjust microservices instances ahead of projected user traffic waves, maintaining zero downtime.
Manufacturing Operations
An automotive manufacturing group integrated its Industrial IoT edge gateways with an enterprise AIOps platform. The ML engine monitors sensory anomalies on assembly line components, preventing unplanned factory downtime.
Cloud Service Providers
Managed infrastructure providers leverage automated alert clustering across multi-tenant environments. This isolates localized client issues from broader network outages, stopping cascading notifications across their client communication portals.
The Role of Observability in Enterprise AIOps
AIOps platforms cannot function without data, and that data is provided by deep enterprise observability frameworks. Observability isn’t just about collecting information; it’s about providing the structural context required for ML engines to reason about complex digital ecosystems.
- Metrics: Numerical time-series measurements that provide historical data on system performance, such as CPU load, memory consumption, or request rates.
- Logs: Highly detailed, time-stamped textual records of specific execution events inside applications or operating systems, critical for forensic analysis.
- Traces: End-to-end paths of transactions as they move through distributed microservices, highlighting exactly where delays or errors occur.
- Event Correlation: The process of linking these metrics, logs, and traces together based on time and architectural context.
- Operational Intelligence: The actionable end product of this analysis, giving engineers an immediate explanation of why a system is failing rather than just stating that it is failing.
Governance and Compliance Considerations
Operating AIOps at scale introduces unique regulatory, security, and administrative requirements that must be handled with care.
- Data Governance: Restrict sensitive data (such as PII or financial records) from leaking into monitoring logs or ingestion pipelines. Mask data before it reaches analytical engines.
- Security Controls: Enforce strict Role-Based Access Control (RBAC) and least-privilege principles for automated scripts. An AI platform triggering remediations requires the same access security as a principal systems engineer.
- Regulatory Compliance: Ensure automated systems generate clear logs for compliance reviews under frameworks like SOC 2, HIPAA, or GDPR.
- Risk Management: Put safety guardrails in place to prevent automated workflows from running endlessly or triggering destructive loops during complex system dependencies.
- Auditability: Every action taken by your machine learning engine—whether it’s raising an alert or restarting a cloud server—must be fully documented in a searchable system log.
12. Organizational Readiness for AIOps
Technology is only one part of the puzzle. The success of an AIOps rollout depends heavily on your team’s operational maturity and readiness to adapt.
- Leadership Support: Large-scale rollouts require sustained executive sponsorship to clear cross-departmental road blocks and align funding with long-term digital goals.
- Team Skills Development: Provide engineering paths for team upskilling. Help traditional infrastructure specialists transition into data-fluent operations experts who understand telemetry analysis.
- Cultural Transformation: Move your organization from a reactive “firefighting” mindset to a proactive, blameless culture that values automated workflows and data-driven insights.
- Operational Maturity Assessment: Grade your current operational maturity before purchasing software. Ensure your infrastructure is properly instrumented and your fundamental incident workflows are stable before adding complex AI layers.
AIOps and Enterprise Automation
AIOps serves as the brain, while automation provides the hands. True efficiency gains happen when intelligence drives automated execution loops.
- Incident Automation: Automatically creates, routes, and updates support tickets with rich context, matching log snips and topology links to expedite resolution.
- Root Cause Analysis: Isolates the foundational trigger of cascading failures by evaluating infrastructure changes, code deployments, and telemetry spikes simultaneously.
- Predictive Operations: Evaluates performance trends over time to identify emerging disk space shortages or memory leaks, opening maintenance tickets before users notice an issue.
- Self-Healing Systems: Resolves common, well-understood issues by automatically restarting microservices, flushing cache files, or executing localized recovery scripts.
- Capacity Optimization: Tracks usage patterns to safely downsize over-provisioned infrastructure or scale out resources to handle real-time demand.
Future of Enterprise AIOps
The capabilities of AIOps platforms continue to evolve rapidly, shifting from simple anomaly detection toward fully proactive operational environments.
- Autonomous Operations: Systems that dynamically configure, protect, and heal themselves across multi-cloud environments, requiring minimal human intervention.
- Hyperautomation: The systematic identification and automation of all viable IT operations, application delivery, and infrastructure tasks.
- AI-Driven Decision Intelligence: Complex simulation models that show executives the downstream operational impact of architectural or software modifications before code goes live.
- Predictive Infrastructure Management: Systems that model future infrastructure needs based on business forecasts, automatically adjusting cloud footprints weeks in advance.
- Self-Optimizing Enterprise Systems: Cognitive infrastructure layouts that continuously tune kernel settings, database indexes, and network routes to achieve maximum speed and efficiency.
Career Opportunities in Enterprise AIOps
As enterprises shift toward intelligent operations management, new and specialized engineering roles are emerging across the tech sector.
- Enterprise AIOps Engineer: Focuses on designing, scaling, and maintaining the core analytical models, telemetry streams, and orchestration layers of the AIOps platform.
- Site Reliability Engineer (SRE): Uses AIOps insights to design software guardrails, manage error budgets, and build reliable distributed applications.
- Platform Engineer: Builds internal developer portals and configures underlying telemetry pipelines to ensure new applications enroll in the central AIOps platform automatically.
- Cloud Operations Architect: Designs scalable multi-cloud infrastructure topologies that integrate smoothly with centralized monitoring and automated healing pipelines.
- Enterprise Automation Consultant: Helps organizations assess their technical maturity, rewrite operational processes, and design dependable automated runbooks.
Common Misconceptions About Enterprise AIOps
- Myth: AIOps is a turnkey software product that works instantly out of the box.
- Reality: AIOps is a continuous practice. It requires clean telemetry pipelines, regular model tuning, and ongoing process adjustment to deliver real-world accuracy.
- Myth: AIOps will replace human engineering teams entirely.
- Reality: AIOps removes repetitive manual work, freeing engineers from alert fatigue so they can focus on architectural design, security improvements, and systemic scale.
- Myth: Automated systems will misconfigure themselves and break production environments.
- Reality: Modern enterprise automation frameworks rely on strict human-defined boundaries, approval steps, and step-by-step rollouts to guarantee safety and compliance.
FAQ Section
- What is the first step in scaling AIOps in a large enterprise?The first step is to establish a unified data schema and telemetry pipeline. Ensure that your metrics, logs, and traces use standard tags across business silos before you deploy complex machine learning analytics models.
- Can enterprise AIOps work with legacy on-premises infrastructure?Yes, modern AIOps platforms ingest telemetry from legacy mainframes and bare-metal environments via custom APIs, enterprise message brokers, or legacy log collectors alongside cloud-native platforms.
- How does AIOps reduce alert fatigue for SRE teams?AIOps engines run clustering algorithms to group thousands of related notifications into a single incident based on time, infrastructure dependencies, and historical topologies.
- What is the difference between observability and AIOps?Observability is the practice of collecting and structuring telemetry data (metrics, logs, traces) to expose system states. AIOps applies machine learning and automated reasoning to that data to drive intelligence and orchestration.
- How do we handle model drift in an enterprise AIOps deployment?Establish an AIOps Center of Excellence to track model accuracy. Schedule regular retraining cadences so your models adapt to code changes and infrastructure updates over time.
- Are open-source standards like OpenTelemetry useful for AIOps?OpenTelemetry is essential. It standardizes data formats across disparate applications and tools, giving your AIOps platform a clean, predictable data stream.
- How does AIOps support predictive capacity planning?The platform tracks usage trends and uncovers subtle performance drops, projecting future cloud compute, storage, and database needs ahead of peak business demands.
- What is the average timeline for an enterprise-wide AIOps rollout?A full-scale rollout generally takes 12 to 24 months, moving through phases from initial discovery and data standardization to alert correlation and automated remediation loops.
- Does AIOps present any data privacy risks?Yes, if unmasked logs contain customer personally identifiable information (PII). Enterprises must configure telemetry pipelines to strip or mask data at the ingestion layer.
- What skills should traditional operations teams develop to prepare for AIOps?Operations professionals should build familiarity with data analysis concepts, script-based automation, infrastructure-as-code deployment models, and foundational site reliability engineering practices.
Final Summary
Scaling AIOps across a large enterprise requires moving past isolated optimization projects and embracing an integrated approach to data, architecture, and team workflows. Success relies on standardizing data schemas, building dependable observability layers, and adopting automated operations progressively. By focusing on measurable metrics like MTTR reductions and alert clustering efficiency, organizations can convert overwhelming raw telemetry into clear operational intelligence. As your team scales its automation and intelligence frameworks, establishing strong governance and upskilling engineers will ensure long-term agility and system resilience.