Upgrade & Secure Your Future with DevOps, SRE, DevSecOps, MLOps!
We spend hours scrolling social media and waste money on things we forget, but won’t spend 30 minutes a day earning certifications that can change our lives.
Master in DevOps, SRE, DevSecOps & MLOps by DevOps School!
Learn from Guru Rajesh Kumar and double your salary in just one year.
Introduction
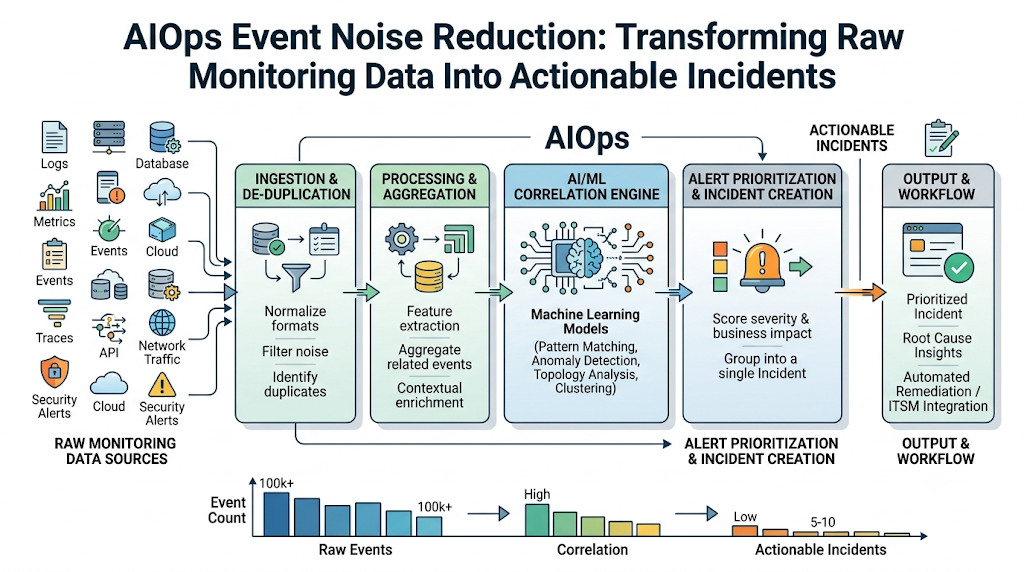
Enterprise IT environments generate thousands of monitoring events every day. Servers, cloud services, applications, databases, network devices, containers, security systems, and observability tools continuously report status changes, errors, warnings, performance spikes, and availability issues. The problem is that not every event requires action. Many events are duplicates, low-priority warnings, false positives, or symptoms of the same underlying problem. When IT teams receive too many alerts, they become overloaded. Important incidents may get missed, response becomes slower, and engineers lose confidence in monitoring systems. This is where IT Event Noise Reduction with AIOps becomes valuable. AIOps helps IT teams collect events, remove duplicates, correlate related signals, prioritize important alerts, and create meaningful incidents for faster resolution. As an educational resource, TheAIOps.com helps learners and IT professionals understand AIOps concepts, intelligent operations, automation, observability, and practical incident management workflows. In this tutorial, you will learn what IT event noise is, why alert fatigue is dangerous, how AIOps reduces event noise, how intelligent event correlation works, and how enterprises can build more reliable incident management processes.
What Is IT Event Noise?
IT event noise refers to the large volume of unnecessary, duplicate, low-value, or poorly prioritized events generated by monitoring tools across IT systems.
In simple terms, event noise is the unwanted sound inside IT monitoring. It hides the real problems behind too many notifications.
For example, if one database outage triggers alerts from the database monitor, application monitor, API gateway, cloud infrastructure, Kubernetes cluster, and customer experience tool, the operations team may receive dozens or hundreds of alerts for one actual problem.
Common Sources of Event Noise
Event noise usually comes from:
- Misconfigured monitoring thresholds
- Duplicate alerts from multiple tools
- Temporary performance spikes
- Repeated warnings from unstable systems
- Poorly grouped infrastructure events
- Dependency-related alerts
- Application errors caused by one root issue
- Security logs that lack proper filtering
Difference Between Events, Alerts, and Incidents
| Term | Meaning | Example |
|---|---|---|
| Event | A recorded change or signal from a system | CPU usage reached 80% |
| Alert | A notification that may need attention | CPU usage stayed high for 10 minutes |
| Incident | A confirmed issue affecting service reliability | Application response time increased for users |
Not every event should become an alert. Not every alert should become an incident. A mature AIOps strategy helps teams make this distinction clearly.
Impact on IT Operations
Too much event noise creates confusion. Engineers spend time checking repetitive alerts instead of solving real incidents.
Over time, teams may ignore alerts because many of them are not useful. This creates a dangerous situation where a real service-impacting incident may be missed.
Why Event Noise Reduction Matters
Event noise reduction is not only about reducing alert volume. It is about helping IT teams focus on what matters.
A good noise reduction strategy improves incident response, team productivity, service reliability, and customer experience.
Reducing Alert Fatigue
Alert fatigue happens when IT teams receive too many alerts and stop treating them with urgency.
For example, a NOC engineer may receive hundreds of alerts during a night shift. If most of them are duplicates or low-priority warnings, the engineer may struggle to identify the one alert that signals a real outage.
AIOps event noise reduction helps by grouping related alerts, removing duplicates, and showing only meaningful incidents.
Faster Incident Detection
When monitoring systems produce too much noise, real incidents are harder to detect.
AIOps helps teams detect serious issues faster by correlating signals from logs, metrics, traces, topology, and historical patterns.
For example, instead of showing separate alerts for API latency, database timeout, and failed login transactions, an AIOps platform may group them into one incident related to database connection failure.
Improved Operational Efficiency
IT teams often waste time investigating alerts that do not need action.
By reducing false positives and duplicate alerts, AIOps allows engineers to spend more time on root cause analysis, prevention, automation, and service improvement.
Better Decision-Making
AIOps adds context to alerts.
Instead of only saying “CPU usage is high,” an intelligent alert may show:
- Which service is affected
- Which users may be impacted
- Whether similar incidents happened before
- Which dependency changed recently
- What remediation steps were used earlier
This helps teams make faster and better decisions.
Enhanced Customer Experience
Customers care about service availability, performance, and reliability.
When IT teams detect incidents faster and resolve them sooner, users experience fewer outages, fewer slowdowns, and more stable digital services.
What Is AIOps?
AIOps, or Artificial Intelligence for IT Operations, is the use of machine learning, analytics, automation, and operational data to improve IT monitoring, incident detection, root cause analysis, and response.
AIOps does not replace IT teams. It helps them work smarter by reducing manual effort and improving operational visibility.
Core Technologies Behind AIOps
AIOps platforms commonly use:
- Machine learning
- Event correlation
- Log analytics
- Metrics analysis
- Anomaly detection
- Topology mapping
- Automation workflows
- Predictive analytics
- Natural language processing for event text
Machine Learning in IT Operations
Machine learning helps identify patterns that are difficult for humans to detect manually.
For example, a system may learn that a short CPU spike during backup time is normal, but the same spike during business hours combined with high error rates may indicate a real issue.
This allows AIOps to reduce false positives and prioritize alerts based on behavior, history, and business impact.
Relationship with Observability and Automation
Observability provides the data. AIOps analyzes the data. Automation acts on the data.
AIOps works best when connected with observability tools that collect:
- Metrics
- Logs
- Traces
- Events
- Service dependencies
- User experience data
Once AIOps identifies a meaningful issue, automation can help create tickets, notify the right team, run diagnostic scripts, or trigger remediation workflows.
How AIOps Reduces IT Event Noise
AIOps reduces event noise through a structured event processing pipeline. This usually includes telemetry collection, normalization, filtering, deduplication, machine learning-based grouping, enrichment, prioritization, and incident creation.
Data Collection and Normalization
The first step is collecting events from different monitoring tools and converting them into a common format.
Enterprise environments often use many tools for infrastructure, cloud, network, application, database, security, and user monitoring. Each tool may use different field names, severity levels, timestamps, and event formats.
AIOps normalizes this data so events can be compared and analyzed together.
Example:
A cloud monitoring tool may report “critical,” while another tool reports “severity 1.” Normalization helps the AIOps platform understand that both may represent high-priority events.
Event Deduplication
Event deduplication removes repeated alerts that describe the same issue.
For example, if a server sends the same disk space warning every minute, the operations team does not need hundreds of identical notifications. AIOps can combine them into one active event with updated frequency and duration.
This reduces alert volume without hiding important information.
Intelligent Event Correlation
Event correlation is one of the most important parts of AIOps event noise reduction.
IT event correlation means grouping related events together to identify a common cause or shared incident.
AIOps can correlate events based on:
- Time
- Hostname
- Application service
- Network dependency
- Kubernetes cluster
- Cloud region
- Business service
- Historical incident patterns
- Topology relationships
Example:
An e-commerce platform may show alerts for payment API failure, checkout delay, database timeout, and increased cart abandonment. Instead of treating these as separate problems, AIOps may correlate them into one incident related to payment database latency.
Anomaly Detection
Anomaly detection identifies unusual behavior compared to normal system patterns.
Traditional monitoring depends heavily on static thresholds. But static thresholds can create noise because systems behave differently at different times.
AIOps learns normal behavior and detects meaningful deviations.
Example:
A CPU usage level of 75% may be normal during peak traffic but unusual during low-traffic hours. AIOps can understand this difference better than a simple rule-based alert.
Alert Prioritization
Not all alerts have the same business impact.
AIOps prioritizes alerts based on severity, affected service, customer impact, dependency importance, and incident history.
Example:
A warning on a test server may be low priority, while the same warning on a production payment service may need immediate attention.
This helps teams focus on business-critical issues first.
Root Cause Analysis
AIOps supports root cause analysis by connecting related signals and showing possible causes.
It may highlight recent changes, failed deployments, dependency failures, configuration updates, or repeated historical patterns.
Example:
If application errors started shortly after a new deployment, AIOps may recommend checking the deployment as a likely root cause.
This does not remove the engineer’s responsibility. It gives engineers a stronger starting point.
Automated Incident Creation
After deduplication, correlation, enrichment, and prioritization, AIOps can create a clean incident in an ITSM or incident management system.
A good incident should include:
- A clear incident title
- Impacted services
- Related alerts
- Timeline of events
- Severity level
- Probable root cause
- Suggested owner team
- Recommended actions
This prevents engineers from manually checking hundreds of raw alerts.
Common Sources of Event Noise
Different systems create different types of event noise. Understanding the sources helps teams design better AIOps workflows.
Infrastructure Monitoring
Servers, virtual machines, storage systems, and databases often generate repeated alerts for CPU, memory, disk, process failures, and service restarts.
Many of these alerts are symptoms, not root causes.
Cloud Platforms
Cloud environments are dynamic. Resources scale up, scale down, restart, move, or change frequently.
Without proper context, normal cloud behavior may appear as event noise.
Containers and Kubernetes
Kubernetes environments generate events from pods, nodes, deployments, services, autoscaling, networking, and storage.
A single pod failure may trigger many alerts across different layers.
AIOps helps by mapping relationships between containers, services, namespaces, and clusters.
Network Devices
Routers, switches, firewalls, load balancers, and gateways can produce large volumes of events.
Network noise often increases during link flaps, packet loss, configuration changes, or dependency failures.
Security Monitoring
Security tools produce logs and alerts from authentication systems, firewalls, endpoint tools, access controls, and threat detection platforms.
SOC teams need careful filtering because not every security event is an active threat.
Application Performance Monitoring
APM tools report slow transactions, error rates, service failures, dependency delays, and code-level exceptions.
AIOps can connect application alerts with infrastructure and cloud events to show the larger picture.
Benefits of IT Event Noise Reduction
AIOps event noise reduction creates value across operations, engineering, business, and customer experience.
Lower Alert Volumes
By removing duplicates and grouping related alerts, teams receive fewer notifications.
This makes monitoring easier to trust.
Faster Mean Time to Detect
MTTD improves when real issues are easier to identify.
AIOps highlights high-impact incidents quickly instead of forcing engineers to search through noisy dashboards.
Reduced Mean Time to Resolve
MTTR improves when incidents include context, history, probable causes, and suggested actions.
Engineers can move from investigation to resolution faster.
Improved Team Productivity
Less noise means fewer interruptions.
DevOps engineers, SRE teams, NOC analysts, and cloud operations teams can spend more time improving systems instead of reacting to low-value alerts.
Better Service Reliability
When teams understand incidents faster, they can prevent repeat failures.
This improves uptime, performance, and customer confidence.
TheAIOps.com Tutorial: Best Practices for Event Noise Reduction
Event noise reduction works best when it is treated as an ongoing operational practice, not a one-time tool setup.
Standardize Monitoring Data
Create consistent naming, severity levels, tags, service ownership, and environment labels.
Use clear fields such as:
- Application name
- Service name
- Environment
- Region
- Cluster
- Owner team
- Business impact
- Severity
Standardized data helps AIOps platforms correlate events more accurately.
Eliminate Duplicate Alerts
Review repeated alerts regularly.
If the same warning appears many times without action, tune the alert rule, adjust the threshold, or combine repeated events.
Deduplication should reduce noise while preserving important frequency and duration details.
Build Effective Correlation Rules
Start with simple correlation rules based on time, service, host, and dependency.
Then improve them using historical incidents and machine learning.
For example, group all alerts related to a specific payment service outage into one incident instead of creating separate incidents for each component.
Continuously Train AI Models
AIOps models improve when they receive feedback.
Engineers should mark whether correlations are correct, whether alerts are useful, and whether suggested root causes are accurate.
This feedback helps the system learn operational patterns.
Monitor Operational Metrics
Track the results of event noise reduction.
Useful metrics include alert volume, duplicate alert rate, incident accuracy, MTTD, MTTR, escalation rate, and engineer workload.
Without measurement, teams cannot prove whether AIOps is improving operations.
Balance Automation with Human Oversight
Automation is powerful, but it should be introduced carefully.
Start with low-risk actions such as ticket creation, alert enrichment, routing, and notification.
Move toward auto-remediation only after teams trust the workflow and understand the risks.
Real-World Use Cases
Enterprise Data Centers
Large data centers generate events from servers, storage, virtualization, databases, backup systems, and network devices.
AIOps can correlate hardware warnings, virtual machine failures, storage latency, and application errors into service-level incidents.
This helps data center teams avoid chasing separate symptoms.
Cloud-Native Applications
Cloud-native systems often run across microservices, containers, managed databases, serverless functions, and APIs.
AIOps can group alerts across cloud services and show which dependency is causing the service degradation.
For example, one cloud region issue may create alerts across many applications. AIOps can group them into a single regional incident.
Banking and Financial Services
Banks need reliable digital banking, payment processing, ATM networks, trading systems, and fraud detection platforms.
Alert noise can slow down response during critical transaction failures.
AIOps helps prioritize incidents that affect customer transactions, compliance workflows, and payment availability.
Healthcare Systems
Hospitals and healthcare platforms depend on patient systems, appointment platforms, lab systems, medical records, and connected devices.
AIOps can help IT teams identify service-impacting incidents faster while reducing unnecessary alerts from supporting systems.
This supports better operational continuity.
E-Commerce Platforms
E-commerce platforms depend on product search, cart, payment, inventory, recommendation, and delivery systems.
During traffic spikes, traditional monitoring may generate too many alerts.
AIOps can identify whether the real issue is database latency, checkout service failure, API timeout, or infrastructure capacity.
Common Challenges
Poor Data Quality
AIOps depends on good data.
If event fields are missing, inconsistent, or poorly labeled, correlation becomes difficult.
Solution:
Create standard tagging, naming, ownership, and severity practices across monitoring tools.
Alert Rule Misconfiguration
Poor thresholds create unnecessary alerts.
For example, a CPU alert may trigger during normal batch processing.
Solution:
Review noisy alert rules and replace static thresholds with dynamic baselines where possible.
Integration Complexity
Enterprises often use many monitoring, logging, cloud, security, and ITSM tools.
Connecting them can be difficult.
Solution:
Start with the most important systems first. Integrate critical monitoring tools, service maps, and incident platforms before expanding.
Rapid Infrastructure Changes
Cloud and Kubernetes systems change frequently.
AIOps models and rules may become outdated if environments change too quickly.
Solution:
Use automated discovery, service mapping, and continuous model updates.
Skills Gaps
Teams may not fully understand machine learning, observability, or event correlation.
Solution:
Train IT operations, DevOps, SRE, and NOC teams on AIOps concepts, data quality, incident workflows, and feedback practices.
Best Practices for Successful AIOps Adoption
Successful AIOps adoption requires people, process, data, and tools to work together.
Start by improving telemetry quality. Logs, metrics, traces, and events should be consistent, searchable, and connected to services.
Integrate monitoring platforms carefully. AIOps is more useful when it receives data from infrastructure, cloud, network, application, database, security, and ITSM systems.
Continuously refine correlation models. Event patterns change as applications, infrastructure, and business services evolve.
Measure operational outcomes. Focus on alert reduction, incident accuracy, MTTD, MTTR, escalation quality, and engineer productivity.
Keep engineers involved in decision-making. AIOps should support human expertise, not hide important operational context.
Traditional Alerting vs AIOps Event Management
| Capability | Traditional Monitoring | AIOps-Based Event Management |
| Alert Processing | Rule-based | AI-assisted correlation |
| Noise Reduction | Limited | Deduplication and intelligent filtering |
| Root Cause Analysis | Manual | Context-aware recommendations |
| Incident Prioritization | Static | Dynamic and risk-aware |
| Automation | Minimal | Workflow-driven automation |
Traditional monitoring is useful for detecting known conditions. However, it often struggles with complex, fast-changing environments.
AIOps-based event management adds intelligence by learning patterns, grouping related events, and helping teams focus on real operational impact.
Key Metrics to Measure Success
Alert Reduction Rate
This measures how much the alert volume decreases after deduplication, filtering, and correlation.
A healthy reduction means engineers are seeing fewer low-value notifications.
Incident Accuracy
Incident accuracy measures whether generated incidents represent real operational issues.
High incident accuracy builds trust in the AIOps system.
Mean Time to Detect
MTTD measures how quickly teams identify a real issue.
AIOps should reduce detection time by highlighting important incidents faster.
Mean Time to Resolve
MTTR measures how quickly teams restore normal service.
AIOps can reduce MTTR by providing context, probable causes, and recommended actions.
Event Correlation Accuracy
This measures whether related events are grouped correctly.
Poor correlation can create confusion. Accurate correlation improves incident understanding.
Operational Productivity
This measures how much time teams save by reducing manual triage, duplicate investigation, and unnecessary escalations.
Future of Event Noise Reduction
Predictive Alerting
AIOps will continue moving from reactive alerting to predictive alerting.
Instead of waiting for a service to fail, systems can identify early warning patterns and notify teams before impact occurs.
Autonomous Incident Management
Incident workflows will become more automated.
AIOps platforms may create incidents, assign teams, collect diagnostics, suggest fixes, and trigger approved remediation steps.
AI-Driven Observability
Observability will become more intelligent.
Teams will not only view dashboards but also receive explanations, patterns, and recommendations from operational data.
Self-Healing Infrastructure
Self-healing systems can detect common issues and automatically apply safe fixes.
For example, restarting a failed service, scaling capacity, clearing temporary cache issues, or switching traffic routes may become automated under controlled policies.
Intelligent Operations Platforms
Future operations platforms will combine monitoring, observability, automation, incident management, and business impact analysis into one intelligent workflow.
This will help enterprises move from alert-driven operations to outcome-driven operations.
Career Opportunities
AIOps skills are valuable for professionals working in monitoring, automation, cloud, reliability, and enterprise IT operations.
AIOps Engineer
An AIOps Engineer designs and manages intelligent operations workflows, event correlation, automation, and operational analytics.
Observability Engineer
An Observability Engineer improves visibility across logs, metrics, traces, events, dashboards, and service maps.
Site Reliability Engineer
An SRE uses automation, monitoring, reliability engineering, and incident response practices to improve service stability.
IT Operations Analyst
An IT Operations Analyst monitors systems, investigates alerts, supports incident response, and helps improve operational workflows.
Cloud Operations Engineer
A Cloud Operations Engineer manages cloud infrastructure, performance, availability, cost, automation, and service reliability.
Common Misconceptions About Event Noise Reduction
Myth: Noise reduction means hiding alerts
Reality:
Noise reduction does not mean ignoring alerts. It means organizing, deduplicating, correlating, and prioritizing alerts so teams can act on the right issues.
Myth: AIOps removes the need for engineers
Reality:
AIOps supports engineers by reducing manual triage and adding context. Human judgment remains important for complex incidents.
Myth: Alert suppression and noise reduction are the same
Reality:
Alert suppression simply blocks or hides alerts. Noise reduction uses intelligence to decide which signals matter and how they relate to each other.
Myth: AI can fully automate incident management immediately
Reality:
Full automation requires trust, governance, testing, and operational maturity. Most teams start with assisted workflows before moving to auto-remediation.
Myth: More monitoring tools always mean better visibility
Reality:
More tools can create more noise if data is not integrated and correlated properly.
FAQ Section
- What is IT event noise reduction with AIOps?
IT event noise reduction with AIOps is the process of using artificial intelligence, machine learning, correlation, and automation to reduce duplicate, unnecessary, or low-value monitoring events. - Why do IT teams receive too many alerts?
IT teams receive too many alerts because modern environments include many servers, applications, cloud services, containers, databases, and monitoring tools that generate continuous events. - Is event noise the same as alert noise?
They are closely related but not exactly the same. Event noise includes all unnecessary system events, while alert noise refers specifically to too many notifications sent to teams. - How does AIOps reduce alert fatigue?
AIOps reduces alert fatigue by deduplicating repeated alerts, correlating related events, prioritizing important incidents, and removing low-value noise from daily operations. - What is event correlation in AIOps?
Event correlation is the process of grouping related events together so teams can understand whether multiple alerts are connected to one common issue. - Can AIOps find the root cause of incidents?
AIOps can suggest probable root causes by analyzing event patterns, service dependencies, topology, historical incidents, and recent changes. Engineers still validate the final cause. - Does AIOps replace traditional monitoring tools?
No. AIOps usually works with existing monitoring and observability tools. It adds intelligence by analyzing and correlating data from those tools. - What teams benefit from AIOps event noise reduction?
IT operations teams, DevOps engineers, SRE teams, NOC teams, SOC analysts, cloud teams, and system administrators can all benefit from reduced alert noise. - What is the first step to reduce event noise?
The first step is to improve monitoring data quality. Teams should standardize event names, severity levels, ownership tags, service labels, and environment details. - Is AIOps useful for small teams?
Yes. Small teams can benefit from AIOps if they manage complex systems or receive too many alerts. Even basic deduplication and correlation can save time.
Final Summary
IT event noise is one of the biggest challenges in modern IT operations. As enterprises adopt cloud platforms, containers, microservices, security tools, and advanced observability systems, the number of events continues to grow. Without proper filtering and correlation, teams face alert fatigue, slower incident detection, delayed resolution, and reduced trust in monitoring tools. AIOps improves this situation by collecting operational data, normalizing telemetry, removing duplicates, correlating related events, detecting anomalies, prioritizing incidents, and supporting root cause analysis. The real goal of IT Event Noise Reduction with AIOps is not simply fewer alerts. The goal is better incident understanding, faster response, improved service reliability, and more focused engineering work.