Upgrade & Secure Your Future with DevOps, SRE, DevSecOps, MLOps!
We spend hours scrolling social media and waste money on things we forget, but won’t spend 30 minutes a day earning certifications that can change our lives.
Master in DevOps, SRE, DevSecOps & MLOps by DevOps School!
Learn from Guru Rajesh Kumar and double your salary in just one year.
Modern enterprise IT environments have grown far too complex for traditional monitoring systems to handle. With microservices architectures, multi-cloud deployments, and millions of metrics streaming in every second, human operators can no longer keep track of system health using manual methods. When a critical failure occurs, finding the root cause amidst a sea of noise is like finding a needle in a digital haystack.
This is where artificial intelligence transforms operations. By shifting from static, threshold-based alerts to intelligent, automated insights, organizations can discover and mitigate system issues before they impact end users. For deep-dive resources, blueprints, and expert perspectives on modernizing your operational workflows, TheAIOps provides the industry-standard guidance required to successfully deploy these advanced capabilities. Implementing robust AI-based anomaly detection in AIOps has transitioned from an innovative luxury to an absolute operational necessity.
What is Anomaly Detection?
At its core, anomaly detection is the process of identifying data points, events, or observations that deviate significantly from the expected baseline of a system. In IT operations, these deviations represent unexpected behavioral changes that frequently point to underlying structural failures, software bugs, resource exhaustion, or security breaches.
Anomalies occur in IT systems due to a multitude of unpredictable factors. A sudden code deployment might introduce a memory leak, a marketing campaign could cause an unprecedented spike in user traffic, or an underlying hardware component might begin to degrade. Because these events do not follow a predetermined schedule, they manifest as unusual patterns within operational metrics.
Understanding these deviations is critical for maintaining infrastructure stability. In standard operational environments, data follows a predictable rhythm based on business hours, weekly cycles, and seasonal trends. An anomaly represents a break in this rhythm, serving as an early warning sign that a system component is entering an unhealthy or unstable state.
What is AIOps?
AIOps, or Artificial Intelligence for IT Operations, combines big data, machine learning, and advanced analytics to automate and enhance IT operational workflows. The primary objective of an AIOps platform is to ingest vast quantities of telemetry data from across the entire technology stack, analyze it in real time, and provide actionable insights to operations teams.
In modern IT environments, AIOps acts as an intelligent layer that sits above your monitoring infrastructure. It unifies disparate data silos—such as logs, metrics, traces, and events—into a single, cohesive analytical pipeline. By applying data science methodologies to operational data, it eliminates manual triage and accelerates incident response.
The relationship between AIOps and anomaly detection is foundational. Anomaly detection serves as the primary engine for AIOps platforms, acting as the front-line mechanism that spots deviations across thousands of parallel data streams, enabling downstream automation engines to correlate, root-cause, and remediate incidents effectively.
Why AI is Needed for Anomaly Detection
Traditional monitoring tools rely heavily on static thresholds, such as alerting an engineer when CPU utilization exceeds 85%. While this approach worked well for monolithic applications running on static physical servers, it fails completely in the era of dynamic, cloud-native infrastructure where resource consumption fluctuates naturally based on microservice scaling.
The sheer scale of modern enterprise data makes manual oversight mathematically impossible. A single cloud-native application can generate hundreds of thousands of distinct time-series metrics per minute across containers, databases, serverless functions, and network interfaces. Configuring and maintaining manual threshold rules for this volume of data would consume an entire engineering team’s time.
Furthermore, static thresholds create a binary view of system health that misses complex, multi-variable failures. A system might experience severe degradation even if no single metric crosses its individual high-water mark. AI is uniquely capable of analyzing relationships between multiple variables simultaneously, identifying subtle, low-amplitude anomalies that human operators and static rules would completely overlook.
AI-Based Anomaly Detection Techniques
To successfully identify deviations across diverse data types, AIOps platforms utilize a sophisticated matrix of mathematical models and algorithmic approaches.
Statistical Methods
Statistical techniques form the bedrock of baseline anomaly detection, relying on mathematical distributions to identify outliers.
- Z-Score Analysis: Measures how many standard deviations a specific data point is away from the mean of the dataset, working efficiently for normally distributed metrics.
- Moving Median Absolute Deviation (MAD): A robust statistical measure that is less sensitive to extreme outliers than standard deviation, making it excellent for noisy operational data.
- Grubbs’ Test: Used to detect a single outlier in a univariate dataset that follows a normal distribution pattern.
These methods require minimal computational power and can run in real time directly at the edge of your data collection pipeline. However, they struggle with highly dynamic data that does not follow a standard statistical distribution or exhibits heavy seasonal fluctuations.
Machine Learning Models
Supervised and unsupervised machine learning models provide the adaptability needed to analyze multi-dimensional operational metrics.
- Isolation Forests: An unsupervised learning algorithm that explicitly isolates anomalies instead of profiling normal data points by randomly selecting a feature and splitting the value range. Since anomalies require fewer splits to isolate, they appear closer to the root of the tree.
- One-Class Support Vector Machines (SVM): Maps data points into a high-dimensional space and establishes a boundary around the cluster of normal operating data, flagging any point falling outside this boundary as anomalous.
- Local Outlier Factor (LOF): Measures the local density deviation of a given data point relative to its neighbors, proving highly effective at finding anomalies in datasets with varying densities.
Deep Learning Approaches
When dealing with high-dimensional, unstructured, or deeply sequential telemetry data, deep neural networks offer unparalleled detection accuracy.
- Autoencoders: Unsupervised neural networks trained to compress input data into a lower-dimensional representation and then reconstruct it back to the original format. When the model encounters anomalous data, it fails to reconstruct it accurately, resulting in a high reconstruction error that signals an issue.
- Long Short-Term Memory (LSTM) Networks: A specialized architecture of Recurrent Neural Networks (RNNs) capable of learning long-term dependencies in sequential data, making them ideal for evaluating complex time-series metrics.
- Generative Adversarial Networks (GANs): Utilized by training a generator to model normal system behavior while a discriminator attempts to identify anomalies, creating a highly sensitive detection boundary.
Clustering-Based Detection
Clustering algorithms group historical operational data into distinct cohorts based on similarity metrics, identifying anomalies based on distance.
- K-Means Clustering: Groups data into a predetermined number of clusters; points that fall far from the centroids of all established clusters are categorized as anomalies.
- DBSCAN (Density-Based Spatial Clustering of Applications with Noise): Locates core samples of high density and expands clusters from them, naturally classifying low-density points in sparse regions as structural noise or anomalies.
Clustering is highly valuable for behavioral profiling, allowing operations teams to discover anomalous infrastructure components by comparing their behavior against similar assets within the same cluster.
Time-Series Forecasting Models
Forecasting models project future system behavior based on historical trends, identifying anomalies when real-time telemetry deviates from the forecast.
- ARIMA (Autoregressive Integrated Moving Average): A classic statistical linear model used for analyzing and forecasting time-series data based on past values and errors.
- SARIMAX: An extension of ARIMA that incorporates seasonal elements and exogenous variables, allowing the model to adapt to complex enterprise business cycles.
- Prophet: An open-source forecasting algorithm optimized for handling time-series data that contains strong seasonal patterns and multiple structural breaks.
y(t)=g(t)+s(t)+h(t)+ϵt
The formula above represents the additive components of a time-series model like Prophet, where g(t) is the trend, s(t) represents seasonality, h(t) accounts for holidays, and ϵt is the error term. When the actual observed value deviates significantly from this calculated y(t), an anomaly is detected.
How AI Detects Anomalies in AIOps Systems
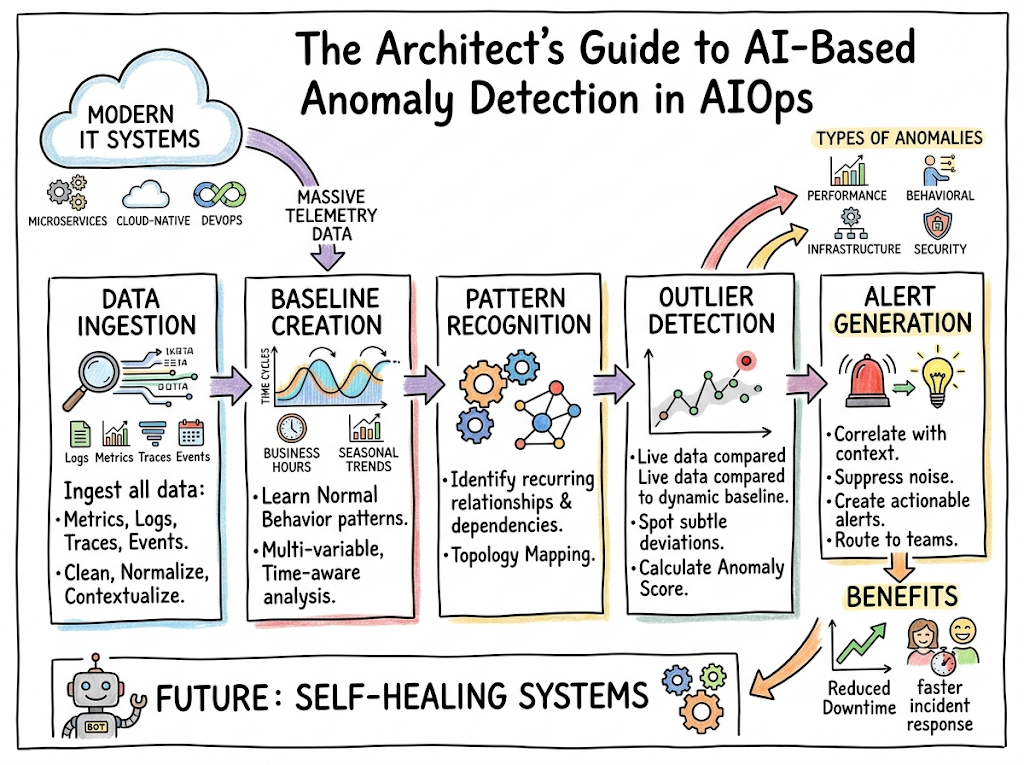
The lifecycle of AI-based anomaly detection in AIOps is a continuous loop consisting of five foundational architectural stages.
[Data Ingestion] ──> [Baseline Creation] ──> [Pattern Recognition] ──> [Outlier Detection] ──> [Alert Generation]
Data Ingestion
The process begins by capturing continuous streams of telemetry from across the enterprise ecosystem. This includes numeric metrics (such as CPU, memory, and network throughput), structured and unstructured log files, application distributed traces, and event streams from orchestrators. The data is normalized, timestamped, and structured into unified data streams for immediate processing.
Baseline Creation
Once ingested, historical data is processed by the AI engine to establish a baseline of normal operating behavior. This baseline is not a static line; it is a dynamic, time-aware boundary that accounts for hourly, daily, and weekly variations. The system learns that a massive traffic spike at 9:00 AM on a Monday is normal, while the same spike at 2:00 AM on a Sunday is highly unusual.
Pattern Recognition
With a baseline established, the machine learning models continuously analyze incoming telemetry streams to recognize recurring structural patterns. This includes identifying correlations between different components, such as a predictable increase in database read operations following a rise in web server traffic. The system maps these multi-variable relationships to build a holistic model of system topology.
Outlier Detection
As live data feeds through the system, the trained algorithms evaluate the incoming points against the dynamic baselines and recognized patterns. If a metric deviates past the mathematically calculated tolerance window, or if a collection of variables breaks their established correlation patterns, the system flags the occurrence as a statistical outlier.
Alert Generation
Rather than immediately paging an engineer upon detecting a single outlier, the AIOps platform subjects the anomaly to a scoring and contextualization engine. The system correlates the outlier with surrounding log events, topology changes, and deployment registries. If the anomaly score surpasses the calculated importance threshold, a contextualized alert is generated and routed to the appropriate engineering team.
Types of Anomalies in IT Systems
To properly manage an enterprise environment, an AIOps platform must differentiate between several distinct classes of behavioral anomalies.
Performance Anomalies
Performance anomalies involve deviations in metrics that directly impact application responsiveness and user experience. Examples include sudden, unexpected increases in API response latencies, drops in transaction processing throughput, or a spike in HTTP 500 error rates. These anomalies directly threaten Service Level Objectives (SLOs) and require immediate operational intervention.
Behavioral Anomalies
Behavioral anomalies occur when an application or system component begins acting in a manner completely inconsistent with its design or historical trends. For instance, a microservice that typically communicates with only two internal databases suddenly attempts to establish connections across dozens of external IP addresses. This class of anomaly frequently points to application misconfigurations or internal logic loops.
Infrastructure Anomalies
Infrastructure anomalies manifest within the physical or virtual hosting environments supporting applications. This includes memory leaks characterized by a monotonic upward trend in RAM consumption, sudden CPU throttling on container hosts, or unexpected drops in storage disk input/output operations per second (IOPS).
Security Anomalies
Security anomalies indicate potential malicious activity or compliance violations within the environment. Examples include unusual patterns of failed administrative logins, unexpected data exfiltration patterns over network interfaces, or unauthorized modifications to system configuration files. By detecting these structural variations early, AIOps platforms act as a critical layer of defense alongside dedicated security systems.
Real-World Use Cases
The practical application of AI-based anomaly detection in AIOps spans every dimension of modern digital infrastructure management.
Cloud Infrastructure Monitoring
In large-scale, auto-scaling cloud environments, systems expand and contract fluidly based on user demand. Traditional monitoring systems frequently generate false alarms when nodes terminate or start up rapidly. An AIOps platform uses clustering and time-series forecasting to understand true capacity demands, identifying genuine resource constraints while ignoring healthy, automated scaling behavior.
Application Performance Monitoring (APM)
Modern distributed tracing tracks requests as they traverse hundreds of individual microservices. When a user experiences a slowdown, finding the specific microservice causing the bottleneck is incredibly challenging. Deep learning autoencoders can analyze the execution traces of millions of transactions simultaneously, instantly isolating the specific database query or downstream service call exhibiting anomalous latency profiles.
Cybersecurity Threat Detection
Advanced persistent threats and zero-day exploits often bypass traditional signature-based security tools. By leveraging unsupervised machine learning algorithms like Isolation Forests, an AIOps framework monitors system call patterns and user access behaviors across production servers. When an attacker attempts to elevate privileges or execute foreign binaries, the system flags the behavior as an anomalous operational event.
Network Traffic Analysis
Enterprise networks route massive volumes of data across global software-defined architectures. Machine learning models track network telemetry metrics, including packet drops, jitter, and bandwidth utilization across individual interfaces. By analyzing these variables concurrently, AIOps platforms can predict network path degradation and pinpoint failing hardware switches or misconfigured routing tables prior to a total network outage.
Benefits of AI-Based Anomaly Detection
Transitioning to an AI-driven operational paradigm yields quantifiable improvements across all primary engineering and business metrics.
Faster Incident Detection
By continuously analyzing data streams in real time, machine learning models spot the microscopic warning signs of system degradation long before traditional thresholds are breached. This drastically reduces the Mean Time to Detect (MTTD) critical infrastructure failures, allowing operations teams to begin remediation efforts before users ever notice a drop in service quality.
Reduced Alert Noise
One of the most significant challenges facing modern operations teams is alert fatigue, driven by thousands of redundant or low-priority notifications daily. AIOps platforms use correlation algorithms to group related anomalies across disparate systems into a single, cohesive incident context. This filters out the operational background noise, allowing engineers to focus exclusively on meaningful events.
| Monitoring Metric | Traditional Static Thresholds | AI-Based Anomaly Detection |
|---|---|---|
| Alert Volume | High (Thousands of unlinked alerts) | Low (Consolidated, contextual incidents) |
| Setup Overhead | High (Manual configuration per metric) | Low (Automated algorithmic baselining) |
| Adaptability | None (Requires constant manual updates) | High (Continuously learns from new data) |
| False Positives | Frequent (Driven by natural business spikes) | Rare (Filtered via multi-variable validation) |
Better System Reliability
As anomaly detection models become deeply integrated into operational workflows, the overall stability of the IT ecosystem increases. Organizations shift from a chaotic, reactive firefighting mode to a controlled, proactive posture. Preventing catastrophic downtime events directly preserves corporate revenue, protects brand reputation, and ensures consistent adherence to strict customer service level agreements.
Predictive Insights
Advanced time-series forecasting models allow AIOps systems to project current resource utilization trends into the future. If a database storage volume is experiencing an anomalous, non-linear acceleration in data logging, the system can calculate the exact day the disk will reach capacity. This provides teams with actionable runway to allocate resources systematically rather than responding to a late-night system crash.
Challenges
While the capabilities of AI-driven operations are extensive, enterprise deployment requires navigating several distinct technical hurdles.
False Positives
Although machine learning dramatically reduces alert noise compared to static thresholds, models can still generate false positives when encountering completely unprecedented, yet entirely benign, business events. A sudden, unannounced flash sale or emergency software release can cause metrics to shift so radically that the algorithm flags the behavior as a critical incident.
Data Quality Issues
Machine learning models are entirely dependent on the quality of the data used to train them. If historical telemetry streams contain prolonged periods of missing data, corrupted timestamps, or unindexed log formats, the resulting baseline models will be fundamentally flawed. Organizations must invest heavily in establishing clean, structured data pipelines before deploying advanced AI analytics.
Model Training Complexity
Selecting, configuring, and tuning the appropriate machine learning algorithms for specific infrastructure footprints requires specialized data science and site reliability engineering expertise. If a model is overfit to historical data, it will fail to detect novel anomalies; if it is underfit, it will capture too much noise and fail to provide operational value.
Scalability Challenges
Running advanced deep learning architectures, such as LSTMs or heavy autoencoders, across millions of streaming metrics requires substantial computational infrastructure. The financial and hardware costs of processing these models in real time can escalate quickly if the underlying AIOps architecture is not carefully optimized for distributed, streaming data processing.
Best Practices
To maximize the return on investment when deploying AI-based anomaly detection in AIOps, engineering organizations should adhere to proven architectural patterns.
Continuous Model Training
Enterprise environments are in a state of constant evolution, with regular software updates, architectural refactoring, and shifting user behaviors. Anomaly detection models cannot be trained once and left indefinitely. Organizations must implement automated retraining pipelines that periodically refresh models with recent operational data to prevent model drift and maintain high detection accuracy.
Data Normalization
Before raw telemetry reaches mathematical algorithms, it must undergo strict normalization. This includes parsing unstructured log strings into structured JSON fields, resolving varying time zones across global data centers into Coordinated Universal Time (UTC), and smoothing out extreme, non-representative network spikes using rolling average transformations. Clean data dramatically accelerates model convergence.
Hybrid Rule + AI Systems
Deploying an effective AIOps strategy does not mean deleting your existing monitoring configurations. The most resilient architectures utilize a hybrid model that combines deterministic, rule-based checks with advanced AI analytics. Known hard failures, such as an expired SSL certificate or a completely full disk partition, should still be caught instantly by simple static rules, freeing the AI engine to focus on complex behavioral patterns.
Proper Alert Tuning
When deploying an AIOps platform initially, configure the anomaly detection models to run in a passive observation mode. Allow the system to generate alerts to a non-paging log destination for several weeks. This allows engineers to compare the system’s output against real operational events, fine-tuning mathematical variance thresholds and confidence intervals before routing alerts to on-call response teams.
Future of AI in Anomaly Detection
The domain of AIOps is advancing rapidly, moving beyond basic detection capabilities toward fully autonomous operational environments.
Self-Healing Systems
The ultimate evolution of anomaly detection is the realization of closed-loop, self-healing infrastructure. In this paradigm, when an AIOps engine detects a highly reliable performance anomaly—such as a specific microservice container experiencing a severe memory leak—it will not merely alert an engineer. Instead, it will programmatically trigger an automated orchestration playbook to gracefully restart the container or provision additional parallel resources, resolving the incident without human intervention.
Predictive AIOps
Future AIOps architectures will rely less on detecting active anomalies and more on preventing them before they materialize. By analyzing the subtle, cross-layer telemetry signatures that historically precede major system outtages, models will generate preemptive warnings hours in advance, allowing engineering teams to perform preventative maintenance during scheduled maintenance windows.
LLM-Powered Monitoring
Large Language Models (LLMs) are beginning to merge with traditional quantitative AIOps platforms. While machine learning algorithms excel at identifying mathematical outliers in time-series data, LLMs can ingest those complex mathematical signals and instantly translate them into natural language summaries for engineering teams. An LLM can analyze an anomaly score, read the corresponding error logs, cross-reference recent Git commits, and present the on-call engineer with a detailed, human-readable summary of the exact root cause alongside recommended remediation steps.
Autonomous IT Operations
As trust in artificial intelligence frameworks matures, enterprise environments will transition toward fully autonomous IT operations (AITO). In this future state, the entire infrastructure lifecycle—including provisioning, capacity planning, anomaly detection, security hardening, and performance optimization—will be governed by interconnected AI agents, allowing human engineers to focus entirely on feature design and business logic.
FAQ Section
1.What is the primary difference between traditional monitoring and AI-based anomaly detection?
Traditional monitoring relies entirely on static, human-configured thresholds that trigger alerts when a specific metric passes a rigid numerical boundary. AI-based anomaly detection uses machine learning to analyze historical data patterns, automatically establishing dynamic, time-aware baselines that adapt to natural system fluctuations without manual configuration.
2.How long does it take for an AIOps model to learn normal system behavior?
While basic statistical baselines can be established within a few days, most machine learning models require two to four weeks of continuous historical telemetry data to accurately understand weekly business cycles, seasonal variations, and normal operational patterns unique to an enterprise ecosystem.
3.Can AI anomaly detection models handle encrypted network traffic?
Yes, because AI models in AIOps evaluate metadata profiles—such as packet sizes, transmission frequencies, connection durations, and directional traffic volume changes—rather than analyzing the raw, unencrypted payload data itself, making them highly effective for maintaining security standards.
4.How does an AIOps platform prevent alert fatigue among engineering teams?
AIOps platforms combat alert fatigue by applying correlation algorithms to group multiple related anomalies across different infrastructure layers into a single, unified operational incident. This filters out thousands of redundant, downstream notifications and presents engineers only with root-cause alerts.
5.Is it necessary to have a dedicated team of data scientists to deploy AI anomaly detection?
No, modern enterprise AIOps platforms come pre-packaged with highly optimized, out-of-the-box machine learning algorithms designed specifically for infrastructure data. While having data engineering skills is beneficial for advanced customization, standard operations teams can successfully manage and deploy these platforms.
6.What types of data are most critical for training an effective AIOps anomaly detection engine?
An effective engine requires comprehensive coverage across the three primary pillars of observability: metrics for numerical performance tracking, logs for deep behavioral and structural context, and traces for mapping transaction pathways across distributed microservices architectures.
7.Can AI-based anomaly detection completely replace human site reliability engineers (SREs)?
No, these AI systems are designed to act as powerful operational force multipliers that automate data analysis, noise reduction, and initial root-cause discovery. Human engineers are still essential for handling highly complex architectural troubleshooting, strategic planning, and designing remediation playbooks.
8.How do these systems respond to sudden, planned spikes in traffic, such as a Black Friday event?
To prevent false positives during major business events, operators can feed external context calendars into the AIOps platform or temporarily adjust the sensitivity parameters of the machine learning models, allowing the system to accept elevated baselines as normal behavior during specified intervals.
Conclusion
The transition from rigid, manual threshold monitoring to dynamic, AI-based anomaly detection represents a massive leap forward in how we manage complex enterprise infrastructure. By leveraging statistical modeling, machine learning, and advanced deep learning frameworks, AIOps platforms allow operations teams to cut through the digital noise, discover hidden system degradations early, and maintain high levels of application availability.
As environments continue to expand in scale and complexity, relying on manual human oversight is no longer viable. Embracing artificial intelligence within your operational workflows is the only sustainable strategy for safeguarding modern digital experiences.