Upgrade & Secure Your Future with DevOps, SRE, DevSecOps, MLOps!
We spend hours scrolling social media and waste money on things we forget, but won’t spend 30 minutes a day earning certifications that can change our lives.
Master in DevOps, SRE, DevSecOps & MLOps by DevOps School!
Learn from Guru Rajesh Kumar and double your salary in just one year.
Introduction
Modern IT infrastructure is growing more complex by the day. Microservices, hybrid cloud architectures, serverless computing, and distributed networks have created a massive web of interconnected systems. For operations teams, managing this footprint manually has become nearly impossible. To overcome these challenges, enterprises are turning to artificial intelligence. Incorporating machine learning and advanced data analytics into your operational workflow represents the next logical evolution of IT operations. This shift moves teams away from reactive firefighting and toward proactive, intelligent management. As an educational learning platform, TheAIOps.com provides IT professionals with the resources needed to navigate this transition. In this comprehensive guide, you will learn the fundamentals of intelligent IT monitoring, explore the core capabilities of AI-driven systems, and discover practical strategies for implementing automated infrastructure observability in your organization.
What Is AI for IT Infrastructure Monitoring?
AI for IT Infrastructure Monitoring is the practice of using artificial intelligence, machine learning, and natural language processing to automatically collect, analyze, and act upon performance data across an organization’s entire technology stack.
Unlike legacy monitoring systems that simply report historical data, AI-powered monitoring analyzes massive streams of telemetry data in real time to identify underlying patterns and operational anomalies.
Core Objectives
The primary goals of implementing AI within your infrastructure monitoring strategy include:
- Achieving Unified Visibility: Breaking down data silos by aggregating logs, metrics, traces, and events into a single, cohesive pane of glass.
- Predicting System Failures: Identifying early indicators of degradation before they result in system downtime or impact end users.
- Accelerating Root Cause Analysis (RCA): Automatically isolating the exact source of an infrastructure fault within seconds instead of hours.
- Enabling Autonomous Remediation: Triggering automated scripts to fix known, repetitive issues without human intervention.
Key Technologies Involved
AI infrastructure monitoring leverages a combination of advanced data engineering techniques:
- Machine Learning (ML) Algorithms: Supervised and unsupervised models trained to understand normal baseline behaviors and detect deviations.
- Pattern Recognition: Systems that analyze historical sequences to match current system behaviors with past operational incidents.
- Natural Language Processing (NLP): Used to parse complex unstructured log data, error reports, and support tickets to extract actionable insights.
- Heuristic Event Correlation: Clustering thousands of individual alert notifications into a single, contextualized incident ticket.
Why Enterprises Are Adopting AI-Driven Monitoring
Enterprises are rapidly migrating toward AI infrastructure monitoring because human scale no longer matches data scale. A typical enterprise infrastructure stack generates gigabytes of telemetry data every minute. AI systems can process this data instantaneously, allowing IT operations engineers, system administrators, and site reliability engineers (SREs) to optimize resource allocations, reduce operational expenses, and maintain continuous application delivery.
Fundamentals of IT Infrastructure Monitoring
To appreciate how artificial intelligence enhances operational workflows, we must first look at the core components of traditional IT infrastructure management. Every enterprise environment consists of multiple distinct layers, each producing its own distinct telemetry data.
+-------------------------------------------------------------+
| Applications |
| (APM, Microservices, User Transactions) |
+------------------------------+------------------------------+
|
+------------------------------v------------------------------+
| Databases |
| (SQL, NoSQL, Query Performance) |
+------------------------------+------------------------------+
|
+------------------------------v------------------------------+
| Cloud & Storage Infrastructure |
| (VMs, Containers, SAN, S3 Buckets) |
+------------------------------+------------------------------+
|
+------------------------------v------------------------------+
| Networks & Physical Servers |
| (Routers, Switches, Bare-Metal CPU) |
+-------------------------------------------------------------+
Servers
Bare-metal machines and virtual instances form the foundational compute layer. Monitoring here focuses on utilization metrics such as CPU usage, memory consumption, disk I/O, and hardware health indicators like fan speeds and power supply temperatures.
Networks
Network infrastructure links your distributed resources together. Monitoring at this layer tracks bandwidth utilization, packet loss, latency, jitter, and error rates across routers, switches, firewalls, and load balancers to ensure reliable data transit.
Cloud Infrastructure
Cloud platforms present unique tracking challenges due to their dynamic, ephemeral nature. Monitoring cloud environments involves tracking auto-scaling groups, virtual private clouds (VPCs), managed container clusters (such as Kubernetes), and serverless functions across multi-cloud ecosystems.
Databases
Databases store and manage core business assets. Monitoring databases involves tracking query execution times, connection pool utilization, deadlocks, transaction logs, and cache hit ratios to prevent data access bottlenecks.
Storage Systems
Storage layers manage both block-level and object-level data. Monitoring focuses on available storage capacity, read/write IOPS, replication latency, and drive health indicators across Storage Area Networks (SAN) and Network Attached Storage (NAS) setups.
Applications
Though often managed by separate Application Performance Monitoring (APM) tools, the application layer depends heavily on the underlying infrastructure. Monitoring applications entails tracking HTTP error codes, API endpoint response times, transaction throughput, and middleware performance dependencies.
AI for IT Infrastructure Monitoring: Core Capabilities
Shifting to an AI-powered monitoring strategy introduces several advanced features that change how operations teams handle infrastructure telemetry.
Intelligent Data Collection
Traditional agents merely pull data at rigid intervals, creating significant overhead or missing brief performance spikes. AI-driven agents adapt their collection frequencies based on current system conditions.
- Enterprise Example: If a retail banking database shows unexpected transaction patterns, the intelligent agent automatically increases its sampling frequency from every 60 seconds to every 5 seconds, capturing the precise details of the anomaly without overloading the system during normal operation.
Event Correlation
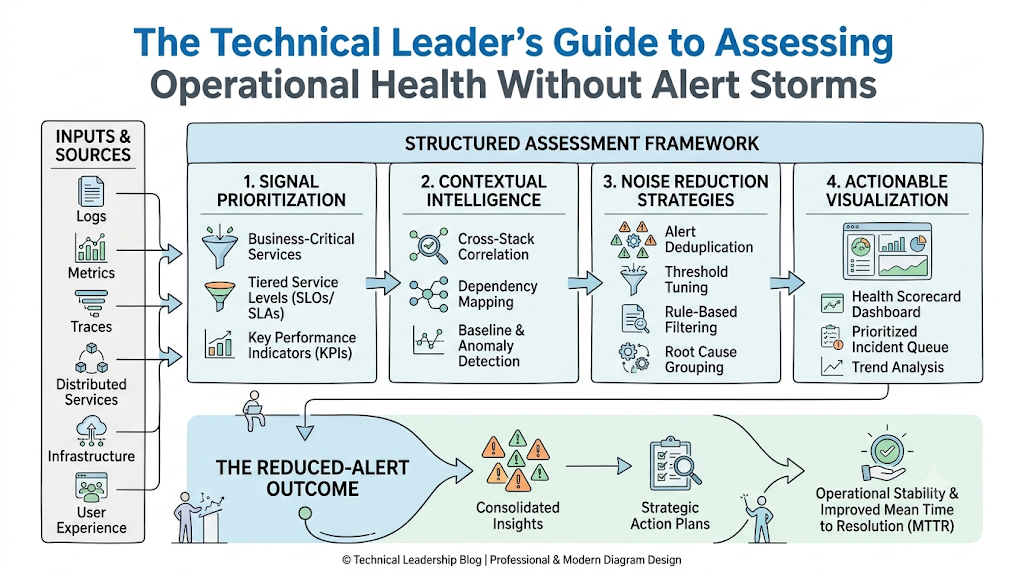
When a core network switch fails, it can trigger downstream alerts across hundreds of virtual machines, applications, and databases. This results in an alert storm that buries the true root cause under a mountain of noise.
- Enterprise Example: An AIOps infrastructure monitoring platform groups 500 individual alerts from a distributed application cluster into a single incident. It identifies that a single top-of-rack switch failure caused the entire disruption, sparing engineers from sorting through 500 repetitive notifications.
Anomaly Detection
Static thresholds assume that system behavior remains identical at all hours of the day. AI monitoring systems establish dynamic baselines that adjust for seasonal trends, business hours, and weekly cycles.
- Enterprise Example: A food delivery application naturally sees a massive spike in traffic every Friday evening. A traditional system might flag this as a critical CPU overload. An AI system recognizes this as normal weekend behavior, only triggering an alert if performance metrics deviate from typical Friday night patterns.
Predictive Analytics
Predictive IT monitoring shifts your team from a reactive posture to a proactive one by forecasting system trends before failures happen.
- Enterprise Example: An AI model analyzes historical disk consumption patterns on an enterprise ERP system. It predicts that, based on current data growth, storage space will completely run out in exactly 11 days, prompting system administrators to scale the volume long before services are disrupted.
Automated Root Cause Analysis
When an outage happens, finding the source of the problem usually requires manual log analysis across multiple departments. AI-driven platforms accelerate this process by reviewing the entire timeline of events for you.
- Enterprise Example: An e-commerce checkout system begins dropping transactions. The AI system scans configuration changes, log files, and network traces simultaneously. It determines that a software patch deployed 10 minutes prior altered a database schema configuration, pinpointing the precise cause of the error.
Self-Healing Automation
Enterprise infrastructure automation connects insights directly to real-world remediation actions, allowing systems to resolve straightforward issues autonomously.
- Enterprise Example: A memory leak causes a non-critical microservice instance to slow down. The AI platform detects the problem, safely isolates the degraded container, spins up a fresh instance, and routes traffic away from the faulty node without requiring manual intervention from an on-call SRE.
Capacity Forecasting
Long-term resource planning often relies on guesswork or simple linear projections. AI capacity forecasting analyzes multi-cloud usage trends to help organizations right-size their environments.
- Enterprise Example: An infrastructure architect plans a migration strategy. The AI platform reviews resource use across the past year and suggests downsizing 40 underutilized cloud instances, saving the company thousands of dollars in monthly cloud spend while ensuring performance remains unaffected.
TheAIOps.com Guide to AI-Powered Infrastructure Monitoring
Implementing AI within your enterprise operations demands a structured, intentional strategy. This framework outlines the core stages needed to build an efficient, intelligent infrastructure management workflow.
+------------------------------------------------------------+
| 1. Build Unified Observability |
| Consolidate logs, metrics, and traces into a |
| centralized platform. |
+-----------------------------+------------------------------+
|
+-----------------------------v------------------------------+
| 2. Reduce Alert Fatigue |
| Apply machine learning models to deduplicate and |
| group related alerts. |
+-----------------------------+------------------------------+
|
+-----------------------------v------------------------------+
| 3. Improve Incident Response |
| Deliver contextual root-cause analysis directly |
| to on-call engineering teams. |
+-----------------------------+------------------------------+
|
+-----------------------------v------------------------------+
| 4. Automate Operational Workflows |
| Connect monitoring insights to self-healing runbooks |
| and automated scaling scripts. |
+-----------------------------+------------------------------+
|
+-----------------------------v------------------------------+
| 5. Scale Enterprise Infrastructure Monitoring |
| Continuously refine AI models to support expanding |
| hybrid and multi-cloud footprints. |
+------------------------------------------------------------+
Building Unified Observability
The journey begins by tearing down traditional data silos. You must ingest all performance data—logs, metrics, configuration registries, and network flows—into a centralized data lake. This cross-domain dataset gives your AI models the context they need to spot complex, multi-layered infrastructure problems.
Reducing Alert Fatigue
Once data collection is unified, focus on cleaning up your alerting system. Use machine learning models to group related notifications together and filter out background noise. Eliminating irrelevant alerts helps protect your operations teams from burnout and ensures they focus on real, business-impacting issues.
Improving Incident Response
Integrate your AI monitoring tool directly with your incident management platforms (such as ServiceNow or PagerDuty). When an incident occurs, the AI system should provide clear, actionable details: what is broken, what caused it, who is affected, and how to resolve it. This gives on-call engineers the necessary context to begin remediation immediately.
Automating Operational Workflows
As you build trust in your AI model’s analytical accuracy, start connecting it to automation engines (like Ansible, Terraform, or Kubernetes operators). Begin with low-risk tasks, such as automatically restarting a frozen service or clearing out temp directories when storage runs low, before moving to complex automated changes.
Scaling Enterprise Infrastructure Monitoring
As your infrastructure grows across hybrid clouds and edge locations, your monitoring architecture must scale alongside it. Review your AI model performance regularly to ensure baseline metrics adjust to newly deployed assets, changing network configurations, and evolving application usage patterns.
Benefits of AI-Powered Infrastructure Monitoring
Upgrading from legacy, rule-based tools to an intelligent IT monitoring system offers significant operational advantages for enterprise teams.
- Faster Issue Detection: AI algorithms identify subtle anomalies and system degradations in real time, catching emerging problems hours before they breach static thresholds or impact your users.
- Reduced Downtime: Automated root cause analysis and early warnings help operations teams dramatically lower their mean time to resolution, preventing prolonged outages.
- Better Resource Utilization: Detailed capacity forecasting highlights over-provisioned infrastructure, helping you downsize idle servers and lower cloud or data center costs.
- Improved Infrastructure Performance: Continuous, automated optimization keeps your compute, network, and storage layers running efficiently, ensuring a smooth end-user experience.
- Enhanced Operational Efficiency: Automating alert triage and repetitive troubleshooting tasks frees your engineering teams from manual firefighting, allowing them to focus on high-value projects.
- Stronger Service Reliability: Building a predictive infrastructure environment helps you meet strict Service Level Objectives (SLOs) and maintain high customer trust.
Real-World Industry Applications
Artificial intelligence transforms infrastructure management across various enterprise verticals by solving distinct operational challenges.
Banking and Financial Services
High-frequency trading networks and core banking applications require absolute reliability. AI platforms monitor transactional data and network latency at the millisecond level, catching micro-bursts of network congestion that could cause failed transactions or compliance penalties.
Healthcare
Modern hospitals rely heavily on distributed electronic health records (EHR) systems and connected medical IoT devices. AI infrastructure monitoring tracks network health and server availability across these networks, ensuring medical professionals retain fast, uninterrupted access to patient data.
Telecommunications
Telecom operators handle massive data distribution networks across millions of connected endpoints. AI-powered monitoring platforms analyze signal metrics, fiber backbone traffic, and cell tower performance to automatically reroute traffic during unexpected hardware failures.
Manufacturing
Smart factories utilize Industrial IoT (IIOT) setups to run automated production lines. Intelligent infrastructure systems track edge compute nodes, industrial gateways, and factory floor server networks to predict connection drop-offs, avoiding costly production stoppages.
Retail and E-Commerce
Digital retail platforms experience extreme traffic fluctuations during promotional sales events. AI infrastructure systems track real-world traffic growth, automatically scaling cloud infrastructure and optimizing database query queues to handle heavy customer volume without crashing.
Cloud Service Providers
Managed service providers run large multi-tenant cloud architectures. AI infrastructure monitoring helps optimize hardware allocations, balances workloads across server racks, and isolates tenant performance anomalies to protect shared infrastructure from the “noisy neighbor” effect.
Traditional Monitoring vs. AI-Powered Infrastructure Monitoring
To clearly understand how these paradigms differ, here is a breakdown comparing legacy practices with an AI-driven approach.
| Capability | Traditional Monitoring | AI-Powered Monitoring |
|---|---|---|
| Data Analysis | Manual review across multiple independent screens. | Centralized, AI-driven data processing across domains. |
| Alert Management | Rule-based, static thresholds that trigger alert storms. | Intelligent event correlation and automatic noise reduction. |
| Root Cause Analysis | Time-consuming manual log correlation and team bridges. | Automated insights that pinpoint the source of faults in real time. |
| Incident Response | Reactive firefighting after a service disruption occurs. | Predictive tracking and automated remediation workflows. |
| Capacity Planning | Simple linear projections using historical trends. | AI forecasting based on actual seasonal usage patterns. |
Common Challenges and Solutions
While the benefits are clear, deploying an AI-powered monitoring solution comes with practical implementation hurdles.
Legacy Infrastructure
- The Challenge: Older systems and mainframes often lack standard API endpoints or modern telemetry outputs, making it difficult to extract data.
- The Solution: Use lightweight open-source log collectors, intermediate data forwarders, or legacy middleware wrappers to standardize data before sending it to your AI platform.
Data Quality
- The Challenge: Missing, disorganized, or duplicated telemetry logs can confuse machine learning algorithms, resulting in inaccurate baselines.
- The Solution: Enforce strict data schemas, sanitize incoming metrics, and ensure your data collection agents are configured uniformly across your environment.
Tool Integration
- The Challenge: Enterprise teams often use a mix of fragmented monitoring tools, making it tough to connect a central AI engine.
- The Solution: Choose open, platform-agnostic observability solutions that offer pre-built connectors for popular cloud platforms, databases, and network vendors.
AI Model Training
- The Challenge: Unsupervised machine learning models require a learning period to understand your system’s normal behavior, which can cause false positives early on.
- The Solution: Run your AI monitoring system in a read-only, non-alerting “shadow mode” for the first few weeks, allowing the algorithms to mature using real traffic before activating live production alerts.
Organizational Adoption
- The Challenge: Operations engineers may feel hesitant to trust automated insights or self-healing scripts with critical production systems.
- The Solution: Start with a phased rollout. Begin by automating simple alerts and low-risk tasks, then gradually expand automated actions as your team gains confidence in the system’s recommendations.
Best Practices for Implementation
Adhering to these core principles will help maximize the value of your intelligent monitoring initiatives:
- Centralize Observability Data: Avoid analyzing infrastructure in fragments. Route your network logs, cloud metrics, and system events into a single, shared data platform.
- Automate Repetitive Tasks: Focus your automation efforts on common, well-understood issues first, such as restarting services or rotating log files, before building complex workflows.
- Continuously Validate AI Models: System environments change constantly. Review your AI thresholds and performance alerts regularly to prevent drift and ensure accuracy.
- Standardize Monitoring Policies: Use Monitoring-as-Code (MaC) to define configuration parameters, alerting rules, and dashboard setups within your CI/CD pipelines.
- Foster Cross-Team Collaboration: Encourage SRE, DevOps, and cloud infrastructure teams to share insights and use the same monitoring platform to break down operational barriers.
Key Performance Metrics
Track these essential metrics to measure the health of your infrastructure and gauge the effectiveness of your AI monitoring strategy:
- Mean Time to Detect (MTTD): The average time it takes for your monitoring solution to spot an infrastructure fault. AI systems aim to lower this to seconds.
- Mean Time to Resolve (MTTR): The average time required to troubleshoot, fix, and restore a degraded service.
- Infrastructure Availability: The percentage of time your enterprise systems remain online and fully operational.
- Alert Accuracy: The ratio of true, actionable alerts relative to total notifications received. High accuracy confirms minimal background noise.
- Resource Utilization: A metric assessing how efficiently your infrastructure uses compute, memory, and storage assets.
- Service Uptime: The overall reliability score of user-facing systems, verifying that infrastructure performance supports your broader business commitments.
Career Opportunities in AI Infrastructure Management
The widespread adoption of intelligent IT operations is creating several new, highly technical career paths for professionals in the space:
- AIOps Engineer: Focuses on designing, implementing, and tuning the machine learning models and data pipelines used in enterprise monitoring platforms.
- Infrastructure Engineer: Specializes in building and scaling modern compute, storage, and networking layers with embedded automation tools.
- Site Reliability Engineer (SRE): Uses software engineering principles to automate operational workflows, manage system reliability, and reduce manual intervention.
- Cloud Operations Engineer: Manages provisioning, optimization, and real-time performance tracking for public, private, and multi-cloud environments.
- DevOps Engineer: Bridges development and operations by embedding infrastructure monitoring directly into continuous delivery software pipelines.
- Observability Engineer: Specializes in architecting scalable telemetry systems that capture, index, and visualize complex logs, traces, and operational metrics.
Future of AI Infrastructure Monitoring
As artificial intelligence models evolve, infrastructure management will shift away from human-driven dashboards toward highly autonomous environments.
+--------------------------------------------------------------+
| Hyperautomation |
| AI systems optimize cloud footprints, balance data-center |
| loads, and manage costs across cloud boundaries. |
+------------------------------^-------------------------------+
|
+------------------------------+-------------------------------+
| Self-Healing Infrastructures |
| AI agents continuously resolve system degradations and |
| patch code issues autonomously. |
+------------------------------^-------------------------------+
|
+------------------------------+-------------------------------+
| Autonomous IT Operations |
| Infrastructure systems auto-configure, self-secure, |
| and optimize without human guides. |
+--------------------------------------------------------------+
Autonomous IT Operations
Tomorrow’s infrastructure platforms will likely manage configuration, scaling, and security updates independently based on high-level operational policies, reducing the need for constant manual adjustments.
AI-Driven Observability
Future observability tools will go beyond raw data collection, automatically mapping intricate dependencies between microservices and infrastructure layers even as those systems scale dynamically.
Self-Healing Infrastructure
Self-healing models will evolve from executing simple scripts to managing complex, multi-layered fixes—such as rolling back broken application updates and hot-patching infrastructure bugs on the fly.
Intelligent Capacity Management
AI architectures will handle global workload distribution dynamically, automatically moving operations between cloud regions or data centers to maximize performance, minimize costs, and reduce energy use.
Hyperautomation
Hyperautomation blends AI, machine learning, and robotic process automation to handle end-to-end operational tasks. From provisioning hardware to running security audits, hyperautomation helps scale infrastructure seamlessly without requiring matching increases in headcount.
Common Misconceptions
Understanding what AI-driven monitoring can and cannot do is vital for setting realistic expectations across your organization.
- AI Replaces Infrastructure Teams: AI does not eliminate the need for skilled professionals. Instead, it automates tedious tasks, allowing engineers to focus on architectural design and system innovation.
- AI Monitoring Eliminates Manual Oversight: AI systems require ongoing guidance, regular model calibration, and strategic direction from experienced operations teams to run safely.
- AI Is Only for Large Enterprises: Thanks to accessible cloud-based monitoring platforms, small and mid-sized businesses can easily adopt AI tools to protect their digital services without massive upfront investments.
- Monitoring Alone Prevents All Incidents: Monitoring highlights and predicts infrastructure flaws, but long-term reliability still requires resilient application design, proper disaster recovery planning, and robust code.
FAQ Section
1. How does AI infrastructure monitoring differ from traditional monitoring?
Traditional tools rely on human engineers setting fixed, manual thresholds to trigger basic notifications. AI-powered systems use machine learning to establish dynamic baselines, automatically group related alerts together, and diagnose the underlying root cause of infrastructure faults in real time.
2. What is event correlation in the context of AIOps?
Event correlation is an analytical process that analyzes thousands of separate, unorganized log events and system messages, grouping them into a single contextualized incident ticket. This approach filters out background noise and stops alert storms from overwhelming on-call staff.
3. Can AI monitoring solutions run safely in hybrid cloud environments?
Yes. Modern AI monitoring platforms are built to integrate across hybrid systems, collecting and analyzing telemetry data from physical data centers, legacy servers, and public cloud providers simultaneously.
4. How does predictive IT monitoring reduce enterprise system downtime?
Predictive monitoring tracks long-term system trends and identifies early indicators of hardware or software degradation. This gives operations teams advance notice to scale volumes, fix memory leaks, or replace hardware before users experience a disruption.
5. Do we need a dedicated data science team to use AI infrastructure tools?
No. Most enterprise AIOps and monitoring tools come with pre-trained machine learning models and out-of-the-box analytical features, allowing standard IT operations and systems engineering teams to manage them easily.
6. What role does anomaly detection play in infrastructure security?
Anomaly detection identifies unusual behavior, such as a sudden spike in outbound data or unexpected admin logins late at night. While primarily used for performance tracking, these insights can also alert security teams to potential breaches.
7. How do automated self-healing workflows work?
When the AI monitoring platform identifies an infrastructure issue with a clear, known fix, it triggers an automated playbook or script. This action resolves the issue immediately without needing human intervention.
8. What are logs, metrics, and traces in unified observability?
Metrics represent numerical values tracking performance over time (like CPU load). Logs provide time-stamped textual accounts of events within an application or server. Traces show the end-to-end journey of a request across distributed systems.
9. How long does an AI monitoring system take to learn normal behavior?
While baseline timelines vary by environment, most machine learning algorithms require between 7 to 14 days of continuous operation to fully understand your system’s normal usage cycles and seasonal trends.
10. What is mean time to resolution (MTTR) and why is it important?
MTTR measures the average time required to isolate, troubleshoot, and fix an operational issue. Lowering your MTTR is a primary goal for operations teams, as it directly translates to less downtime and more reliable service delivery.
Final Summary
As enterprise IT architectures grow more distributed, relying on manual monitoring strategies is no longer viable. Implementing AI for IT infrastructure monitoring enables organizations to cut through operational noise, automate root cause analysis, and move from reactive firefighting to proactive, predictive management. Emphasizing unified observability, intelligent event correlation, and automated self-healing workflows helps maximize system uptime, optimize resources, and protect end-user experiences. To keep pace with these shifts, tech professionals must continuously refine their approach to systems engineering. Platforms like TheAIOps serve as valuable educational hubs, providing the guides, insights, and training resources needed to master AI-driven operations and lead modern enterprise automation initiatives.