Upgrade & Secure Your Future with DevOps, SRE, DevSecOps, MLOps!
We spend hours scrolling social media and waste money on things we forget, but won’t spend 30 minutes a day earning certifications that can change our lives.
Master in DevOps, SRE, DevSecOps & MLOps by DevOps School!
Learn from Guru Rajesh Kumar and double your salary in just one year.
Introduction
In today’s fast-moving software economy, unexpected IT downtime can paralyze an entire corporation within minutes. When core infrastructure components drop offline, transaction processing halts, supply chains freeze, and customer trust evaporates. The financial repercussions are often measured in thousands of dollars per minute, making system resilience the ultimate metric for operations teams. To survive at scale, engineering teams must transition to a proactive operational posture. This shift is driven by predictive infrastructure management, which applies artificial intelligence and historical pattern analysis to locate underlying system vulnerabilities before they trigger an operational crisis. For professionals looking to master these modern workflows, TheAIOps.com serves as an educational learning resource dedicated to breaking down artificial intelligence for IT operations. In this guide, you will learn how engineering teams use predictive models to eliminate service disruptions, decode operational telemetry, and build truly self-healing enterprise environments.
What Are Predictive Models in AIOps?
Predictive models in AIOps are mathematical and statistical frameworks that analyze historical telemetry data to calculate the probability of future infrastructure failures. Instead of waiting for a hardware drive to fill completely or a memory leak to crash a container, these models track the trajectory of system behavior over time.
Core Objectives
The primary objectives of predictive infrastructure management include:
- Early Anomaly Identification: Highlighting subtle deviations from normal baselines that human analysts cannot track manually.
- Time-to-Failure Forecasting: Estimating exactly how much runway an operations team has before a resource bottleneck causes a service degradation.
- Root-Cause Acceleration: Correlating disparate telemetry events across multi-cloud environments to pinpoint the origin of an impending failure.
Key Technologies Involved
Predictive analytics for IT operations brings together several core technological disciplines:
- Machine Learning (ML): Regressive and classification algorithms that learn standard performance curves without manual threshold programming.
- Time-Series Analysis: Specialized modeling techniques designed to read sequences of data points collected over time, identifying trends, seasonality, and cyclic behaviors.
- Natural Language Processing (NLP): Systems used to parse unstructured text logs, identifying dangerous clusters of error logs across application layers.
Why Predictive Analytics Matters in IT Operations
Modern cloud platforms generate billions of operational metrics, logs, and trace events every single day. Human operators cannot scale alongside this volume of data. Predictive models transform this overwhelming mountain of raw telemetry into proactive insights, turning chaotic data streams into organized, actionable warnings.
Fundamentals of Predictive Downtime Prevention
Implementing predictive analytics requires a structured data workflow. Predictive models do not operate in a vacuum; they depend on a continuous cycle of data collection, scoring, and refinement.
[Raw Telemetry Engine] -> [Real-Time Stream Parsing] -> [Pattern Comparison Engine] -> [Risk Scoring Logic] -> [Automated Action/Alerting]
Historical Data Analysis
Every effective predictive engine begins with historical context. Models must ingest months of metric data, configuration changes, past incident tickets, and deployment logs. By analyzing this archive, the system learns what “normal” looks like during a major product launch, a quiet weekend night, or a high-volume seasonal sale.
Real-Time Monitoring
While historical data builds the model’s intelligence, live streaming data feeds its real-time decisions. Modern data collectors stream system states—such as CPU utilization, network latency, database connection pools, and queue lengths—directly into the predictive model with minimal latency.
Machine Learning Models
At the heart of the architecture sits the machine learning layer. Depending on the design, this might feature supervised learning models (trained on historical examples of past outages) or unsupervised learning algorithms (designed to surface anomalies without prior labeling).
Pattern Recognition
Predictive models look beyond isolated metrics. They execute complex pattern recognition across thousands of parallel signals. For example, a minor rise in network latency coupled with a subtle dip in database read speeds might signal an impending thread exhaustion event, even if both metrics are well within traditional safety zones.
Risk Scoring
When an anomaly is spotted, the system calculates an operational risk score. This dynamic metric factors in the critical nature of the component, the likelihood of a system failure, and the projected time until an outage occurs.
Continuous Learning
Infrastructure configurations change constantly due to software updates and infrastructure scaling. Predictive models feature continuous feedback loops, adjusting their internal weights based on whether their past predictions were accurate or false alarms.
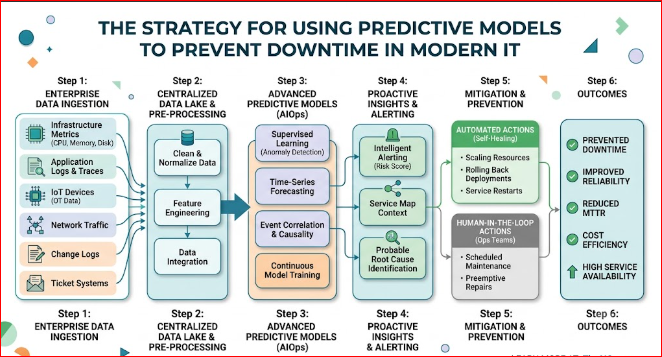
Using Predictive Models to Prevent Downtime
To appreciate the value of predictive models, let’s explore how they operate across six critical operational scenarios.
Detecting Early Warning Signals
Consider a massive microservice application where a slow memory leak is developing on a core authentication service. Traditional monitoring remains silent because memory usage is still at 65%.
However, a predictive model analyzes the step-by-step upward trajectory of the memory consumption curve over the last 48 hours. Recognizing that this pattern deviates from the service’s historical baseline, the model generates an early warning signal, allowing developers to patch the code long before the server runs out of memory.
Forecasting Infrastructure Failures
In enterprise storage arrays, hard drive degradations can occur suddenly. By tracking underlying physical telemetry—such as input/output error counts, temperature fluctuations, and write speeds—predictive models can flag a storage node that is likely to fail within the next 48 hours.
[Healthy Baseline] ---> [Subtle I/O Latency Spikes] ---> [Model Generates Risk Warning] ---> [Safe Node Evacuation]
This alert window gives storage architects plenty of time to safely migrate live workloads to healthy volumes before data corruption occurs.
Predicting Capacity Bottlenecks
During flash sales, web infrastructure experiences massive, sudden surges in user traffic. Traditional auto-scaling groups react only after the traffic hits, leading to temporary connection dropouts.
Predictive models use time-series forecasting to analyze inbound traffic velocity, computing infrastructure needs minutes in advance. The system proactively spins up new compute instances ahead of the surge, ensuring seamless application performance.
Intelligent Alert Prioritization
When an enterprise infrastructure layer degrades, it often triggers an “alert storm”—hundreds of downstream systems shouting about lost connections simultaneously. This noise completely overwhelms the on-call engineer.
An AIOps platform uses predictive data relationships to instantly group these alerts, highlighting the single, foundational bottleneck causing the downstream issues, and silencing the unneeded duplicate warnings.
Automated Preventive Actions
True operational maturity combines predictive analytics with automated remediation rules. If a predictive framework calculates a 95% probability that a third-party API gateway node will crash due to thread starvation within ten minutes, it doesn’t just wait for an engineer to log in.
The predictive engine can automatically route incoming production traffic away from the failing instance while safely restarting the service behind the scenes.
Continuous Model Improvement
Every time an engineering team handles an incident, the resolution data is fed back into the training pipeline. If the model predicted an outage that did not materialize, the operational parameters are retuned. This iterative cycle keeps the machine learning framework aligned with the ever-changing nature of modern software architectures.
TheAIOps.com Insights on Predictive Downtime Prevention
According to engineering frameworks established at TheAIOps.com, scaling intelligent incident prevention requires moving past generic AI implementations. True predictive monitoring is built on clear structural layers.
Building Predictive Monitoring Systems
Successful enterprise implementations avoid dropping a generic machine learning model onto a chaotic network. Teams must build unified data pipelines that cleanly ingest metric, log, and trace data into a central data lake. Without this data normalization, predictive algorithms will struggle with messy data and return unreliable results.
Reducing Service Interruptions
The team at TheAIOps.com stresses that reducing service interruptions depends entirely on extending the prediction window. Moving your discovery horizon from two minutes before an incident to two hours completely changes how your team responds. Engineers move away from chaotic emergency firefighting and shift into organized, scheduled software maintenance.
Improving Operational Reliability
Reliability is won by eliminating blind spots across complex architectures. Predictive models must observe everything: on-premises hardware layers, third-party cloud integrations, virtualized networks, and edge database instances. By unifying these fields into a single pattern-matching engine, enterprises eliminate the hidden operational dead zones where outages often hide.
Automating Preventive Maintenance
Modern infrastructure moves too fast for slow, manual work tickets. Organizations must connect predictive alerting engines directly with infrastructure automation systems like Ansible, Terraform, or Kubernetes operators. This allows the system to execute safe, automated fixes—like expanding disk space or recycling app pools—without needing human approval.
Scaling Predictive Operations Across Enterprises
To successfully scale predictive models, you must secure organizational buy-in. Teams should start with a small, well-defined pilot program, such as predicting memory bottlenecks on a single non-critical microservice. Once the model proves its value by successfully stopping an outage, you can safely scale the predictive framework across the wider enterprise.
Benefits of Predictive Models
Transitioning from an emergency-response mindset to predictive monitoring delivers massive advantages across both engineering teams and business units.
- Reduced Downtime: By identifying performance risks early, systems stay operational, preserving revenue streams and user access.
- Faster Incident Prevention: Teams stop wasting hours hunting through log files during an active outage; the predictive model surfaces root causes before things break.
- Improved Service Availability: System availability metrics rise steadily toward the gold standard of “five nines” ($99.999\%$), protecting critical service-level agreements (SLAs).
- Better Resource Planning: Accurate, forward-looking capacity forecasts stop teams from over-provisioning expensive cloud hardware, maximizing asset efficiency.
- Lower Operational Costs: Preventing major system crashes reduces expensive overtime costs, regulatory failure fines, and emergency consultant interventions.
- Increased Customer Satisfaction: End users enjoy a smooth, reliable digital environment, protecting brand loyalty and driving platform adoption.
Real-World Industry Applications
Predictive models are reshaping how different sectors approach digital infrastructure stability.
Banking and Financial Services
In high-frequency trading and retail banking networks, a millisecond of network latency can cost millions of dollars. Financial institutions deploy predictive analytics for IT operations to constantly screen database clusters, catching connection pool congestion early and keeping transaction clearing networks up and running safely.
Healthcare
Modern hospitals rely entirely on digital health networks and connected medical devices. Predictive models keep electronic health record (EHR) databases reliable, alerting engineering teams to system degradations well before doctors or care providers encounter a software slowdown.
Telecommunications
Telecom providers manage massive, geographically distributed core networks. By leveraging predictive infrastructure management, network teams track signal degradation trends and device health metrics across thousands of towers, orchestrating preventative field hardware repairs before local mobile users experience a dropped connection.
Manufacturing
Industrial IoT systems connect physical factory floors directly with enterprise cloud networks. Predictive maintenance models parse machine vibration and temperature metrics alongside network performance streams, scheduling equipment updates during quiet, natural production gaps to completely avoid unexpected factory halts.
Cloud Service Providers
Hyper-scale infrastructure providers use deep predictive analytics to balance workloads across thousands of physical host servers. By predicting hardware hotspots and network bottlenecks, they dynamically shift tenant workloads around, ensuring stable performance across the global network.
E-Commerce Platforms
During high-stakes online sales events, e-commerce architectures face massive traffic variations. Predictive models scan checkout microservices and payment gateways in real time, allowing platform architectures to auto-scale resources and fix software anomalies before shoppers encounter a broken checkout cart.
Reactive Monitoring vs. Predictive Monitoring
| Feature | Reactive Monitoring | Predictive Monitoring |
| Problem Detection | After failure occurs | Before failure occurs |
| Incident Response | Reactive and stressful | Preventive and orderly |
| Alerting | Rule-based on static thresholds | AI-driven pattern predictions |
| Resource Planning | Historical trends analyzed manually | Predictive forecasting models |
| Service Availability | Lower due to active outages | Higher via continuous mitigation |
Common Challenges
While the benefits are clear, rolling out predictive systems comes with specific operational hurdles. Here is how teams can overcome them.
Poor Data Quality
- The Challenge: Machine learning models fail when fed inconsistent, incomplete, or disorganized telemetry data.
- The Solution: Build strict data validation pipelines. Use open telemetry standards to format metrics, traces, and logs uniformly before they reach your AI models.
Limited Historical Data
- The Challenge: New software deployments or fresh cloud environments lack the deep data history needed to train advanced models.
- The Solution: Use unsupervised anomaly detection models to start. These models can spot weird behavior patterns right away without needing months of past training data.
False Positives
- The Challenge: Overly sensitive predictive configurations create a flood of false alarms, causing alert fatigue and leading engineers to ignore warnings.
- The Solution: Set up a validation feedback system. When the model triggers an alert, engineers must easily flag it as accurate or a false alarm, sharpening the model’s accuracy over time.
Legacy System Integration
- The Challenge: Older monolithic applications often lack clean, modern API endpoints for streaming live telemetry data.
- The Solution: Deploy lightweight data agents and log wrappers to grab legacy console outputs, formatting that data into clean time-series metrics.
Model Maintenance
- The Challenge: As application code changes and new features roll out, the predictive model’s accuracy can naturally drift and degrade.
- The Solution: Automate your model training. Integrate model updating directly into your standard CI/CD deployment pipelines to keep your AI smart.
Best Practices
To make the most of your predictive infrastructure tools, keep these core implementation strategies in mind:
- Collect High-Quality Operational Data: Invest heavily in building clean, standardized monitoring pipelines across your entire architecture.
- Continuously Retrain Predictive Models: Schedule regular model training runs so your system naturally learns to recognize new structural states and software configurations.
- Integrate Monitoring Across the IT Environment: Break down isolated team data siloes by feeding network, database, application, and cloud metrics into a single analysis engine.
- Validate Prediction Accuracy Regularly: Track your model’s accuracy metrics closely to find and fix false alarms before they disrupt your engineering workflow.
- Combine AI Insights with Expert Review: Use automated guardrails. Let your AI find the risks, but keep your senior engineers involved to review major architecture changes.
Key Performance Metrics
If you want to track how well your predictive models are preventing downtime, monitor these six core operational metrics:
Mean Time to Detect (MTTD)
The average time it takes your monitoring systems to spot an emerging problem. Predictive monitoring aims to drop this metric to zero or move it into negative territory by catching problems before they impact users.
Mean Time to Resolve (MTTR)
The average time required to fix a system failure. By pinpointing the exact root cause of a risk early, predictive analytics helps engineers fix problems much faster, lowering overall MTTR.
Prediction Accuracy
The percentage of your model’s alerts that point to real infrastructure risks. Higher accuracy ensures your engineering team trusts your monitoring system.
Service Availability
The overall uptime percentage of your services. Moving toward predictive operations directly protects your service uptime, helping you hit your critical SLA goals.
Alert Precision
The ratio of true operational anomalies compared to the total number of alerts sent out. High precision means your team spends time fixing real problems instead of chasing false alarms.
Downtime Reduction Rate
The percentage drop in total unplanned downtime hours after launching your predictive models. This is the ultimate metric for proving the business ROI of your AIOps platform.
Career Opportunities
The massive industry shift toward automated operations is opening up exciting new career paths for technical professionals:
- AIOps Engineer: Specialists who build, connect, and manage the data pipelines and machine learning engines that drive corporate monitoring platforms.
- Predictive Analytics Engineer: Data scientists focused on building time-series algorithms, anomaly detection tools, and failure prediction models for IT systems.
- Site Reliability Engineer (SRE): Systems engineers who use predictive data to build scalable, resilient infrastructure and eliminate manual operational work.
- Infrastructure Engineer: Architects who design underlying server networks that can scale and self-heal based on predictive insights.
- Cloud Operations Engineer: Cloud specialists focused on managing performance baselines, optimizing costs, and ensuring uptime across complex multi-cloud setups.
- Observability Specialist: Telemetry experts who ensure metrics, logs, and traces are cleanly collected and formatted across wide corporate architectures.
Future of Predictive Operations
As machine learning models become more powerful, predictive IT operations will evolve far beyond basic dashboards.
Autonomous IT Operations
We are moving toward fully autonomous operations systems. Future platforms will manage data streams, diagnose root causes, and fix complex system anomalies completely on their own, requiring zero manual human intervention.
Self-Healing Infrastructure
Tomorrow’s cloud networks will be completely self-healing. When a predictive model spots an oncoming regional cloud slowdown, the infrastructure layer will automatically move its own data workloads to safe regions seamlessly.
AI-Driven Capacity Planning
Manual budget forecasting will soon be obsolete. Predictive engines will study business expansion goals alongside real system usage patterns to automatically purchase and balance global cloud resources at the best possible price.
Intelligent Infrastructure Optimization
Predictive networks will continuously tune their own internal software configurations, adjusting database settings and memory allocations on the fly to deliver peak performance as traffic changes.
Hyperautomation
By blending predictive insights with advanced automation engines, enterprise systems will handle thousands of complex fixes simultaneously, transforming how businesses scale their technology.
Common Misconceptions
Let’s clear up a few frequent misunderstandings about predictive infrastructure models.
Misconception 1: Predictive Models Eliminate Every Single Failure.
Reality: No model can predict unpredictable external problems, like a sudden physical fiber-optic cable cut or an instantaneous third-party power grid failure.
Misconception 2: AI Never Makes Incorrect Predictions.
Reality: Predictive models work on probabilities, not total certainties. They can experience false alarms or miss completely new issues if their training data isn’t regularly updated.
Misconception 3: Predictive Monitoring Is Only for Large Enterprises.
Reality: Thanks to modern cloud tools, predictive monitoring is highly accessible. Small teams can easily deploy lightweight anomaly detection to protect their growing applications.
Misconception 4: Historical Data Alone Guarantees Accurate Predictions.
Reality: Deep historical archives are highly valuable, but they must be paired with clean, real-time telemetry streaming to catch active, fast-moving system anomalies.
FAQ Section
- What is the difference between AIOps and traditional monitoring tools?
Traditional tools use static thresholds to alert teams after a failure has already occurred. AIOps platforms use machine learning and pattern recognition to analyze streams of telemetry data, catching anomalies early so teams can stop outages before they impact users. - How much historical data is required to train a basic predictive model?
While having three to six months of data is best for learning seasonal business trends, you can easily launch basic anomaly detection models with just two to four weeks of clean, continuous performance data. - Can predictive models prevent outages caused by bad code deployments?
Yes. By monitoring system health metrics closely right after a new code deployment, predictive models can instantly spot unusual performance dips, letting teams quickly roll back updates before a major crash happens. - What are false positives, and how do they impact engineering teams?
A false positive is an inaccurate alarm triggered by a model for a problem that doesn’t exist. Too many false alarms cause alert fatigue, which frustrates engineers and can lead them to ignore real warnings. - Do predictive models require manual threshold configuration?
No. The biggest advantage of machine learning models is that they calculate dynamic baselines automatically, adjusting to shifting traffic patterns without needing manual updates. - How does predictive monitoring help lower corporate cloud infrastructure costs?
By providing highly accurate capacity forecasts, predictive models help teams avoid over-provisioning expensive cloud hardware, allowing them to scale down resources safely when traffic drops. - What role do site reliability engineers play in predictive operations?
SREs use predictive insights to build automated remediation scripts, configure data pipelines, and design resilient systems that can fix infrastructure issues autonomously. - Is it possible to implement predictive models inside legacy on-premises data centers?
Yes. As long as your legacy servers can export system logs and metrics cleanly via data collectors, predictive models can analyze that data to protect your older systems. - What is an alert storm, and how do predictive analytics tools fix it?
An alert storm happens when a single failure triggers hundreds of downstream alarms at once. Predictive systems use event correlation to group these alerts together, highlighting the single root cause and silencing the extra noise. - How should a team begin introducing predictive infrastructure management?
Start with a small, clear pilot project. Connect a single core service to an anomaly detection engine, prove its accuracy, and then gradually expand the tool across your wider corporate network.
Final Summary
Shifting from reactive firefighting to predictive monitoring is a major milestone for modern enterprise engineering. Using predictive models to prevent downtime allows organizations to spot underlying performance risks early, helping them address issues long before they turn into disruptive user outages. This proactive approach relies heavily on clean data pipelines, smart machine learning models, and a commitment to continuous system tuning. As software architectures grow more distributed, relying on manual monitoring simply isn’t an option. Embracing advanced predictive analytics, smart event correlation, and automated fixes is the best way to ensure your systems remain highly reliable, scalable, and cost-effective.