Upgrade & Secure Your Future with DevOps, SRE, DevSecOps, MLOps!
We spend hours scrolling social media and waste money on things we forget, but won’t spend 30 minutes a day earning certifications that can change our lives.
Master in DevOps, SRE, DevSecOps & MLOps by DevOps School!
Learn from Guru Rajesh Kumar and double your salary in just one year.
Introduction
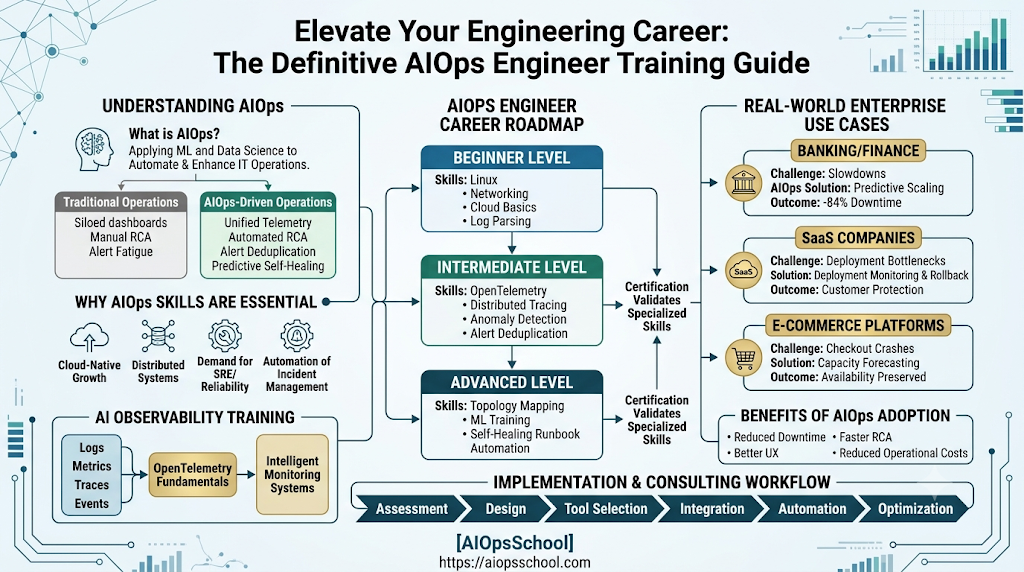
Modern IT landscapes have broken past the threshold of human-scale management. The rapid migration toward cloud-native ecosystems, microservices architectures, and highly dynamic Kubernetes deployments has unlocked unprecedented velocity. However, this architectural evolution has introduced immense operational complexity. Teams no longer manage isolated physical nodes; they orchestrate transient, ephemeral infrastructure components that generate terabytes of telemetry data every hour.The database team blames the network; the network team points to the microservice deployment; and the DevOps engineers face a wall of text in a logging dashboard. This phenomenon, known as alert fatigue, drains engineering hours and extends the Mean Time to Resolution (MTTR). Resolving issues requires sorting through vast mountains of noise to locate a single root cause. Engineering leaders and technology professionals can access industry-validated expertise through AIOpsSchool, a comprehensive resource providing the essential educational blueprints, frameworks, and targeted training programs required to navigate and master this shifting operational landscape.
What Is AIOps?
AIOps (Artificial Intelligence for IT Operations) combines big data, machine learning, and advanced analytics to automate and enhance IT operations. By continuously ingesting multi-source telemetry data, AIOps platforms filter operational noise, correlate disparate events, detect real-time anomalies, and provide automated root cause analysis to accelerate incident resolution.
Understanding AIOps
What Is Artificial Intelligence for IT Operations?
At its core, AIOps applies machine learning algorithms to operational datasets. It acts as an intelligent overlay above your entire infrastructure, continuously gathering, normalizing, and analyzing logs, metrics, traces, and event streams. Instead of relying on static, human-configured thresholds that break as workloads scale, AIOps models learn the normal behavioral baselines of your systems and flag statistical deviations automatically.
In Simple Terms
Think of AIOps as a smart digital assistant for your IT systems. Instead of making engineers check dozens of dashboards and read thousands of error messages during a system crash, the AI scans everything instantly, points directly to the problem, and explains how to fix it.
Real-World Example
An enterprise e-commerce platform experiences a sudden checkout failure. Instead of multiple separate teams getting woken up by individual alerts for database lag, API latency, and container restarts, the AIOps engine correlates these signals. It reveals that a recent application deployment caused an unindexed database query, automatically identifying the specific code commit responsible.
Why It Matters
As IT environments grow too massive for human teams to monitor manually, AIOps converts overwhelming system noise into actionable steps. This allows businesses to protect their revenue and prevent major outages before they affect end users.
Key Takeaways
- Combines machine learning with telemetry data to streamline operations.
- Shifts IT teams from manual dashboard monitoring to automated insights.
- Detects hidden infrastructure issues before they turn into major outages.
Why Traditional IT Operations Are No Longer Enough
Traditional IT operations rely heavily on siloed monitoring tools and static thresholds (e.g., triggering an alert when CPU utilization hits 85%). In a distributed, auto-scaling cloud environment, these rigid rules cause two major problems: continuous false positives that cause alert fatigue, or silent failures where systems degrade without crossing specific thresholds. Human operators cannot manually track every dependency across thousands of interconnected microservices.
How AI and Machine Learning Improve Operations
AI algorithms excel at pattern recognition across massive datasets. Mathematical models use clustering techniques to group related alerts together, reducing noise by up to 90%. Linear regression and time-series forecasting allow engines to predict resource exhaustion before it happens, while anomaly detection models identify subtle, multi-variable performance drops that traditional monitoring misses entirely.
Evolution from Monitoring to Intelligent Operations
Monitoring answers the question, “Is a specific system working?” Observability explains, “Why is it not working based on its outputs?” AIOps moves a step further to answer, “What will go wrong next, and how do we fix it automatically?”
| Traditional Operations | AIOps-Driven Operations |
| Siloed Dashboards: Teams check separate tools for logs, network data, and application performance. | Unified Data Ingestion: All telemetry streams feed into a single centralized machine learning layer. |
| Static Thresholds: Fixed alerts trigger on rigid, pre-set values (e.g., Disk > 90%). | Dynamic Baselines: ML models adjust alert triggers based on historic time and usage patterns. |
| Manual Triaging: Engineers hold emergency bridge calls to isolate root causes. | Automated RCA: Mathematical correlation points directly to the underlying technical failure. |
| Reactive Remediation: Action is taken only after a system breaks or a ticket is filed. | Proactive & Self-Healing: Automated scripts fix predicted issues before impact occurs. |
Why AIOps Skills Are Becoming Essential
Growth of Cloud-Native Infrastructure
As enterprises migrate to containerized, dynamic architectures managed by Kubernetes, the infrastructure changes state minute by minute. Understanding how to apply algorithmic modeling to these transient layers has become a required capability for engineering teams.
Rise of Distributed Systems
Modern applications rely on complex webs of serverless functions, external APIs, and distributed databases. When an application failure occurs, finding the root cause requires tracing requests across dozens of network boundaries—a task that is practically impossible without algorithmic cross-layer correlation.
Demand for Reliability Engineering
Organizations are shifting from legacy operations models to Site Reliability Engineering (SRE) frameworks. SRE teams prioritize eliminating repetitive manual work (“toil”). Acquiring AIOps skills allows engineers to build self-healing pipelines that automate these routine tasks.
Automation of Incident Management
Enterprise operations teams cannot afford to spend hours managing incident life cycles manually. AIOps skills enable engineers to build automated pipelines that ingest alerts, open tracking tickets with correct context, route them to the right on-call team, and trigger automated runbooks.
Future of Autonomous Operations
The long-term goal of enterprise IT infrastructure is NoOps—a fully autonomous environment that provisions, tunes, secures, and heals itself. Engineers who master AIOps methodologies today are positioning themselves to design and manage these self-healing architectures tomorrow.
AIOps Certification Explained
What Is an AIOps Certification?
An AIOps Certification is a professional credential that validates an engineer’s ability to architect, deploy, and manage AI-driven operational frameworks. It proves that a professional understands both the operational realities of modern infrastructure and the data science principles required to tune machine learning models for IT data.
In Simple Terms
An AIOps certification is a formal badge showing employers that you know how to use AI and machine learning tools to run complex software systems smoothly, clear out alert noise, and fix system errors automatically.
Real-World Example
A Senior DevOps Engineer completes an AIOps Engineer Certification. During a major infrastructure overhaul, they use their training to replace over 500 static Prometheus alert rules with an anomaly detection engine, cutting monthly false alarms from thousands down to twelve critical alerts.
Why It Matters
Certifications provide a clear, structured learning path for engineers while giving enterprises a reliable way to verify that their staff can handle complex cloud-native architectures.
Key Takeaways
- Validates an engineer’s practical skills in machine learning for IT operations.
- Helps professionals stand out in a competitive, cloud-focused job market.
- Gives companies confidence when hiring talent for digital transformation projects.
Benefits of Professional Certification
- Career Advancement: Positions engineers for high-paying roles like AIOps Architect or Lead Reliability Engineer.
- Structured Knowledge: Breaks down complex data science concepts into clear, practical steps for IT systems.
- Enterprise Trust: Demonstrates to leadership teams that you have the skills to handle high-stakes digital transformations.
Skills Validated Through Certification
- Mathematical event correlation and noise reduction configuration.
- Integration of OpenTelemetry frameworks with algorithmic backends.
- Building and executing automated self-healing scripts (runbook automation).
- Configuring predictive analytics models for capacity management.
Who Should Pursue AIOps Certification?
- DevOps Engineers: To build smarter, feedback-driven deployment pipelines.
- SRE Engineers: To eliminate operational toil and improve system uptime.
- Cloud & Platform Engineers: To optimize complex multi-cloud environments.
- Monitoring Specialists: To move beyond basic dashboards toward intelligent telemetry systems.
- IT Managers & Directors: To confidently guide enterprise AIOps adoption strategies.
AIOps Training and Courses
What Learners Typically Study
Machine Learning for IT Operations
Learners explore the underlying algorithms used in operations, including supervised learning for known failure signatures, unsupervised learning for anomaly detection, and natural language processing (NLP) for analyzing system logs and ticketing data.
Event Correlation
Courses teach students how to write rules and train models that group thousands of scattered system events into a single, cohesive incident ticket based on time proximity and topology mapping.
Intelligent Alerting
This module focuses on eliminating alert fatigue. Students learn to configure dynamic thresholds that automatically adapt to patterns like weekend traffic drops or end-of-month batch processing spikes.
[ Raw Telemetry Ingestion ]
│
▼
[ Noise Filtering Layer ] ──► Drops 90% of non-critical event noise
│
▼
[ Algorithmic Correlation ] ──► Matches patterns using topology data
│
▼
[ Intelligent Alert Generation ] ──► Delivers a single actionable ticket
Root Cause Analysis
Engineers learn how graph databases and dependency maps are used by AI engines to trace a system error back through a service mesh to its exact point of origin.
Predictive Analytics
Training covers time-series forecasting techniques, teaching professionals how to use historical consumption data to predict disk saturation, memory leaks, and network bottlenecks before they cause downtime.
Incident Automation
This area focuses on connecting AIOps platforms to automation engines. Students learn how to build closed-loop remediation workflows that trigger self-healing scripts when specific anomalies are verified.
Observability
Learners move past simple monitoring to study the internal state of systems by deeply analyzing core telemetry datasets.
OpenTelemetry
Courses provide hands-on experience with this vendor-neutral standard, showing students how to collect, process, and export high-quality metrics, logs, and traces from cloud-native applications.
Monitoring Automation
Students learn to treat monitoring configuration as code, using tools like Terraform to automatically deploy observation agents and AI configurations alongside raw application infrastructure.
AIOps Engineer Certification Path
To successfully transition into this specialized discipline, professionals should follow a structured learning path that balances foundational systems knowledge with advanced algorithmic operations.
| Level | Skills | Outcome |
| Beginner | Core Linux administration, basic scripting (Python/Bash), understanding logs, metrics, and standard monitoring tools. | Ability to maintain basic monitoring setups and resolve simple, well-defined system alerts. |
| Intermediate | Containerization (Docker/Kubernetes), distributed systems tracing, OpenTelemetry integration, and event correlation basics. | Ability to deploy cloud-native observability frameworks and configure dynamic, smart alerting rules. |
| Advanced | Machine learning model tuning, automated runbook creation, structural architecture design, and full pipeline integration. | Capable of designing end-to-end self-healing enterprise platforms and leading AIOps transformations. |
AIOps Engineer Career Roadmap
Required Technical Skills
Linux
Deep familiarity with Linux operating system internals, performance tuning parameters, and kernel diagnostic utilities is essential for understanding where telemetry data originates.
Networking
A strong grasp of modern networking concepts—such as DNS resolution patterns, BGP routing, service mesh configurations, and HTTP/2 transport protocols—is critical for tracing distributed application paths.
Cloud Platforms
Practical, hands-on experience architectural design across major cloud providers (AWS, Azure, or GCP) is necessary to manage cloud-native scaling and API interactions.
Kubernetes
Since Kubernetes serves as the standard OS for modern cloud infrastructure, engineers must understand pod lifecycles, control plane metrics, and how to monitor containerized microservices.
Monitoring Tools
Proficiency with standard industry tools like Prometheus, Grafana, Datadog, or Dynatrace is required to understand how to collect data before routing it to AI engines.
Automation
Strong skills with automation engines such as Ansible, Terraform, and GitOps tools are vital for turning automated insights into repeatable infrastructure actions.
Python
Python is the primary language used for data manipulation and scripting custom automation routines. Engineers need it to write data pipelines and interact with machine learning libraries.
Observability
A comprehensive understanding of deep tracing, distributed context propagation, and structured logging practices is required to feed high-quality data into AIOps systems.
Learning Sequence
- Master Systems Engineering Foundations: Develop deep proficiency in Linux administration, networking fundamentals, and Python scripting.
- Adopt Cloud-Native Architecture: Learn container management via Kubernetes and study distributed multi-tier application patterns.
- Implement Full-Stack Observability: Learn to instrument applications using OpenTelemetry to capture clean, well-structured logs, metrics, and traces.
- Study Applied Operational Machine Learning: Learn how clustering, regression, and anomaly detection models work with infrastructure data.
- Build Closed-Loop Automation: Connect your AI engine’s analytic outputs to automated configuration frameworks to create fully functional self-healing workflows.
AI Observability Training
What Is AI Observability?
AI Observability represents an evolutionary step beyond legacy system monitoring. While traditional monitoring alerts you when a component breaks, AI-driven observability analyzes the internal telemetry of complex systems to explain why it failed, highlighting hidden patterns across deep architectural layers without needing pre-configured alert rules.
In Simple Terms
Monitoring tells you that your car’s check-engine light is on. AI Observability acts like a master mechanic with a digital scanner, telling you exactly which engine valve is misfiring, why it happened, and how it is affecting your gas mileage in real time.
Real-World Example
During a sudden traffic surge, a financial transaction app experiences sporadic timeouts. Traditional monitoring reports normal CPU use and active databases. An AI observability tool scans distributed trace data and discovers that a specific microservice is waiting on an external authentication API, pinpointing the exact network dependency causing the lag.
Why It Matters
Modern microservices generate too many variables for humans to track. AI Observability automatically maps these complex connections, allowing engineering teams to quickly pinpoint root causes instead of wasting hours searching through logs.
Key Takeaways
- Focuses on understanding system health based on comprehensive telemetry outputs.
- Uses machine learning to identify anomalous behavior without manual rule configuration.
- Cuts down troubleshooting times from hours to fractions of a second.
Why Observability Matters
Without observability, managing a distributed system is like flying blind. When performance drops, engineers waste valuable time guessing where the bottleneck lies. Observability replaces guesswork with clear data, keeping platforms reliable and protecting the user experience.
Logs, Metrics, Traces, and Events
These four telemetry pillars form the foundational data layer for any AIOps deployment:
- Metrics: Numeric values measured over time (e.g., memory usage percentage) used to identify trends.
- Logs: Time-stamped text records produced by applications that provide granular execution context.
- Traces: End-to-end paths of a single request as it moves through various distributed microservices.
- Events: Noteworthy occurrences within an ecosystem, such as a code deployment or a container restart.
OpenTelemetry Fundamentals
OpenTelemetry provides a unified, open-source standard for collecting and exporting telemetry data. By mastering OpenTelemetry, engineers ensure their systems generate clean, consistent data, preventing vendor lock-in and allowing AI engines to parse system signals efficiently.
Intelligent Monitoring Systems
Intelligent monitoring systems use machine learning to move past rigid thresholds. They continuously evaluate system behaviors, adjusting their alarm points dynamically based on seasonal trends, historical patterns, and contextual workloads.
| Monitoring | Observability |
| Symptom Focused: Tells you when something is broken (e.g., “The web server is returning 500 errors”). | Cause Focused: Shows you why something broke by looking at internal states and request lifecycles. |
| Static Testing: Relies on pre-defined rules based on known historical failure patterns. | Dynamic Analysis: Infers systemic health across changing systems without needing pre-set rules. |
| Siloed Views: Looks at components individually (e.g., checking a database disk separate from application code). | Holistic Context: Traces connections across the entire system infrastructure. |
AIOps for SRE and DevOps Engineers
How AIOps Supports SRE Practices
Site Reliability Engineers focus on maintaining highly available infrastructure while continuously rolling out new software features. AIOps acts as a force multiplier for SRE teams by automating manual triage steps and providing the deep insight needed to manage strict Error Budgets and Service Level Objectives (SLOs).
In Simple Terms
For SRE and DevOps engineers, AIOps is like adding an automated assistant to the team. It handles the repetitive work of sorting through system alerts and logs, freeing up engineers to focus on building new features and improving system design.
Real-World Example
An SRE team manages an app with a strict SLO of 99.9% uptime. An AIOps engine notices a slow, steady increase in memory usage after a minor code update. It automatically flags the issue as a slow memory leak and creates a Jira ticket for the development team—preventing a system crash and keeping the team’s uptime target safe.
Why It Matters
By handling routine incident sorting and early anomaly detection, AIOps prevents developer burnout, cuts down on on-call fatigue, and helps teams maintain high system availability.
Key Takeaways
- Helps teams protect their uptime targets (SLOs) by catching system errors early.
- Frees up engineers from repetitive tasks so they can focus on system improvements.
- Seamlessly connects software development speed with reliable system operations.
Reducing Alert Fatigue
Alert fatigue is one of the biggest risks facing on-call engineering teams. When engineers receive hundreds of low-priority or false alarms every day, they can easily miss critical, system-threatening issues. AIOps resolves this by clustering related alerts together, suppressing known noise, and routing only high-priority, actionable insights to on-call engineers.
Improving Incident Response
When a critical incident occurs, AIOps speeds up response times by instantly providing context. Instead of forcing engineers to dig through separate log tools and trace maps, the platform presents a unified incident timeline showing the exact root cause, impacted components, and relevant remediation steps.
Enhancing Reliability Engineering
Reliability engineering requires shift-left practices—identifying operational issues early in the software development lifecycle. AIOps tools analyze performance data from staging and testing environments, catching code regressions and scaling bottlenecks before updates are pushed to production.
Supporting Continuous Delivery
Modern DevOps teams rely on continuous integration and continuous delivery (CI/CD) pipelines to deploy code changes frequently. AIOps supports this by continuously monitoring post-deployment metrics. If a new deployment triggers an algorithmic anomaly, the platform can automatically initiate a safe code rollback to protect the production environment.
Enterprise AIOps Consulting
Why Organizations Need AIOps Consulting
Implementing an enterprise-grade AIOps strategy involves much more than simply buying a software platform license. It requires a fundamental shift in how teams manage data, structure workflows, and organize operational culture. Enterprise AIOps consulting provides organizations with the strategic direction, architectural frameworks, and hands-on experience needed to navigate these transformations successfully, ensuring a strong return on technology investments.
In Simple Terms
AIOps consulting helps large companies create a clear step-by-step plan for bringing AI into their IT operations. This keeps teams from spending money on expensive software tools they might not know how to configure correctly.
Real-World Example
A global retail bank wants to modernize its legacy payment processing infrastructure. Instead of trying to guess which AI tools to buy, they hire an expert consulting team. The consultants evaluate the bank’s system maturity, clean up their data architecture, and guide them through a rollout that cuts system incidents by 40% within six months.
Why It Matters
Large-scale technology rollouts can fail without a clear strategy. Professional consulting ensures that an enterprise aligns its tools, internal processes, and team structures to achieve reliable, long-term operational improvements.
Key Takeaways
- Prevents costly deployment mistakes through expert planning and tool selection.
- Provides a structured path tailored to an organization’s specific operational maturity.
- Ensures technical changes align with core business goals.
Assessing Operational Maturity
Before deploying machine learning models, an organization must understand its current operational standing. Consultants evaluate existing data quality, current monitoring tool sprawl, and team readiness to build a tailored deployment map.
Tool Selection Strategies
The modern AIOps marketplace includes a wide variety of tools, ranging from platform-agnostic analytics engines to vendor-specific cloud monitoring suites. Consultants help organizations evaluate these choices based on their existing technology stack, budget limits, and internal skill levels.
Building AIOps Roadmaps
A successful enterprise deployment requires a phased approach. Consultants design detailed roadmaps that focus on achieving quick wins first—such as alert noise reduction—before moving on to advanced goals like automated self-healing workflows.
Change Management Considerations
Moving to an AI-driven operations model requires shifting team mindsets from manual control to automated trust. Consultants help guide this cultural transition by running training workshops, rewriting old incident management playbooks, and restructuring teams around collaborative AIOps workflows.
AIOps Implementation Services
Implementation Lifecycle
Assessment
Engineers map out the existing infrastructure, audit data sources, and identify operational bottlenecks to set clear performance baseline targets.
Design
Architects plan the overall data ingestion pipelines, pick the right machine learning models, and design integration patterns for ticketing and automation systems.
Tool Selection
Teams evaluate and select the best tools for the enterprise’s unique needs, balancing specialized point solutions against broad, all-in-one AIOps suites.
Integration
Engineers connect telemetry sources (such as OpenTelemetry collectors) to the central processing layer and link output pathways to alerting platforms like PagerDuty or Slack.
Automation
Consultants build and test automated runbooks that trigger specific scripts to resolve common, verified system incidents without human intervention.
Optimization
Data specialists review the machine learning models over time, tuning correlation rules and anomaly sensitivities to eliminate false positives.
Continuous Improvement
The platform is regularly updated to ingest new data sources, refine automated workflows, and adapt to evolving infrastructure architectures.
[ Assessment ] ──► Map current infrastructure and baseline metrics
│
▼
[ Design & Select ] ──► Architect pipelines and choose optimal AI platforms
│
▼
[ Integration ] ──► Connect OpenTelemetry collectors to central AI layers
│
▼
[ Automation Build ] ──► Create closed-loop self-healing runbook scripts
│
▼
[ Continuous Optimization ] ──► Refine machine learning models and tracking rules
Real-World Enterprise Use Cases
Banking and Financial Services
- Operational Challenge: A global investment bank struggled with slow incident responses during high-volume trading windows. Fragmented monitoring tools created massive alert noise, which delayed their ability to identify core database issues and led to expensive compliance penalties.
- AIOps Solution: The bank deployed a centralized AIOps engine that integrated all server, database, and network logs, applying real-time event correlation across the entire infrastructure.
- Business Outcome: Critical alert noise dropped by 85%, and MTTR for trading platform issues fell from 42 minutes to under 3 minutes, completely avoiding costly regulatory fines.
Healthcare Platforms
- Operational Challenge: A large telehealth vendor experienced intermittent API drops across its patient portals. Traditional threshold alerts failed to catch these issues because overall resource usage remained within normal limits.
- AIOps Solution: The company implemented AI-driven observability with real-time anomaly detection to monitor distributed user request paths.
- Business Outcome: The AI engine quickly isolated a microservice memory leak caused by an external medical record integration, allowing the team to resolve the bug before it could impact patient consultations.
SaaS Companies
- Operational Challenge: A fast-growing B2B software provider suffered from high engineering burnout because on-call teams were constantly woken up by non-actionable night alerts.
- AIOps Solution: They adopted automated alert noise reduction algorithms and introduced dynamic threshold scheduling tailored to variations in regional traffic patterns.
- Business Outcome: On-call pages fell by 70%, improving engineer retention rates and allowing teams to focus more time on core product development.
Telecommunications
- Operational Challenge: A major telecom provider faced frequent network performance dips across thousands of cell towers due to legacy, reactive maintenance scheduling.
- AIOps Solution: The provider introduced time-series forecasting and predictive analytics models to continuously analyze signal data and hardware logs.
- Business Outcome: The operations team shifted to a predictive maintenance model, fixing failing tower hardware before local cellular services could drop for customers.
E-Commerce Platforms
- Operational Challenge: A major retail platform suffered frequent checkout dropouts during high-traffic holiday sales events, losing significant revenue during triage delays.
- AIOps Solution: They built a fully integrated AIOps workflow that connected system performance analytics directly to automated infrastructure scaling runbooks.
- Business Outcome: The system achieved self-healing capabilities; the AI engine detected early resource constraints and provisioned extra cloud capacity automatically, maintaining zero checkout downtime during peak sales seasons.
Benefits of AIOps Adoption
- Reduced Downtime: Catches system risks early and automates common fixes to maximize application availability.
- Faster Root Cause Analysis: Replaces manual dashboard triaging with clear, machine-driven diagnostic guidance.
- Better User Experience: Resolves background backend errors before they can cause lag or outages for end users.
- Reduced Operational Costs: Lowers costs by eliminating repetitive work and streamlining tool usage across the enterprise.
- Improved Reliability: Helps teams shift from a reactive firefighting posture to a proactive, reliable system architecture.
- Smarter Decision-Making: Provides engineering leaders with clear, data-driven trends for capacity planning and budget investments.
Common Challenges in AIOps Adoption
- Data Quality Issues: Machine learning models require clean, comprehensive data. If an enterprise feeds unstructured logs and incomplete metrics into an AI engine, the output will be inaccurate.
- Solution: Standardize data collection using OpenTelemetry frameworks before sending information to AI platforms.
- Tool Integration Challenges: Legacy IT systems often rely on older, proprietary monitoring tools that do not easily share data with modern AI layers.
- Solution: Use modern API gateway bridges and open-source data collectors to build reliable integration points.
- Skills Gap: Many engineering teams understand traditional operations well but lack the skills required to manage AI models and data analytics pipelines.
- Solution: Invest in structured training programs like AIOps certifications to build internal skills.
- Organizational Resistance: Teams are often hesitant to hand over system controls to automated self-healing scripts.
- Solution: Build trust gradually by starting with read-only AI recommendations before turning on fully automated remediation scripts.
- Lack of Observability Maturity: Trying to run an advanced AIOps platform without basic telemetry tracing is a recipe for failure.
- Solution: Focus on building a strong foundation of system visibility before introducing complex machine learning tools.
Common Mistakes Professionals Make
- Focusing Only on Tools: Buying expensive software platforms without teaching the team the core principles of algorithmic operations.
- Ignoring Observability Fundamentals: Trying to deploy complex AI engines while relying on basic, unstructured logging setups.
- Poor Data Collection: Ingesting bad data or leaving major gaps in system visibility, which leads to inaccurate AI insights.
- Skipping Automation Strategy: Setting up an AI platform to flag anomalies but failing to build the automated runbooks needed to fix them.
- Lack of Continuous Learning: Assuming a one-time setup is enough, rather than regularly updating skills as cloud-native tech evolves.
Future of AIOps
Autonomous Operations
The long-term future of technology operations points directly toward fully autonomous, self-running environments. As systems grow more complex, human operators will shift away from daily system maintenance, stepping into design roles while AI platforms manage real-time balancing, patching, and provisioning.
AI-Driven Incident Management
Artificial intelligence will completely transform how system incidents are handled. Future AI engines won’t just alert teams to problems; they will automatically write detailed post-mortem documents, update code repositories to patch bugs, and adjust alerting systems based on what they learn from every incident.
Predictive Reliability Engineering
Instead of fixing systems after they break, tomorrow’s SRE teams will focus on predictive reliability engineering. Advanced time-series models will simulate potential system failures well in advance, allowing engineers to strengthen application code before bugs ever reach a live production environment.
Intelligent Capacity Planning
As cloud costs continue to rise, AI engines will play a vital role in budget optimization. By continuously matching historical business data with real-time system performance, AI platforms can automatically adjust global cloud resources to ensure maximum performance at the lowest possible cost.
Self-Healing Infrastructure
The widespread adoption of self-healing infrastructure will turn manual system troubleshooting into a thing of the past. When an issue occurs, automated runbooks powered by deep learning models will instantly isolate containers, adjust routing paths, and fix code errors—keeping platforms online without human intervention.
AI-Powered Observability
As open-source standards like OpenTelemetry continue to mature, AI models will integrate directly into the data collection layer. This change will allow monitoring tools to automatically interpret complex data streams right at the source, giving enterprises instant system visibility with minimal configuration effort.
Why Learn with AIOpsSchool
- Industry-Focused Curriculum: Courses are built and updated by veteran enterprise architects to match real-world operational needs.
- Hands-On Learning: Students practice on live Kubernetes clusters and real enterprise architectures, avoiding purely theoretical lectures.
- Certification Programs: Earn clear, industry-validated credentials that show employers you can manage modern, automated infrastructure.
- Enterprise Consulting Expertise: Learning paths are backed by years of real-world consulting experience across major global industries.
- Career-Oriented Skill Development: Master the specific, high-demand skills needed to excel in competitive roles like SRE, DevOps, and Platform Engineering.
FAQ SECTION
1. What is AIOps Certification?
An AIOps Certification is a formal professional credential that verifies an engineer’s ability to use machine learning, big data, and advanced analytics to optimize IT operations. It proves you know how to reduce alert noise, automate root cause analysis, and configure modern, self-healing system architectures.
2. Who should learn AIOps?
AIOps training is highly beneficial for DevOps engineers, Site Reliability Engineers (SREs), cloud engineers, platform engineers, and IT operations managers. It is ideal for any technology professional who wants to move away from manual system monitoring and build modern, automated infrastructure skills.
3. What skills are required for AIOps Engineers?
A successful AIOps engineer needs a solid mix of systems engineering and data science fundamentals. Key skills include Linux administration, networking, Python scripting, container management with Kubernetes, and a strong understanding of open telemetry frameworks and data analysis models.
4. How does AIOps help DevOps teams?
AIOps assists DevOps teams by filtering out non-actionable alert noise, connecting data across complex microservices, and automating post-deployment checks. This allows development teams to discover and resolve code bugs quickly, preventing issues from affecting users.
5. What is AI Observability?
AI Observability is an advanced approach to system monitoring that uses machine learning to analyze logs, metrics, traces, and events. Instead of relying on static, human-configured alert rules, it studies internal system data to understand why complex applications experience performance drops.
6. What is OpenTelemetry?
OpenTelemetry is an open-source, vendor-neutral framework designed to collect, process, and export metrics, logs, and traces from software applications. It provides the clean, structured data layer that AIOps engines need to perform accurate analytics and correlation.
7. How long does it take to learn AIOps?
The learning timeline depends on your technical background. Experienced DevOps or SRE engineers can master intermediate AIOps concepts within 3 to 6 months of structured study. Professionals new to systems engineering may need 9 to 12 months to build the necessary foundation.
8. What are AIOps Implementation Services?
AIOps Implementation Services are specialized consulting and engineering programs that help enterprises plan, integrate, and optimize AI platforms within their infrastructure. These services ensure that tools are correctly connected to data sources and aligned with business goals.
9. Is AIOps a good career choice?
Yes, AIOps is an excellent, high-growth career path. As corporate infrastructures expand past human scale, enterprises are paying premiums for engineers who can deploy automated, self-healing platforms—making this one of the most resilient specialties in modern tech.
10. What is the future of AIOps?
The future of AIOps centers on fully autonomous operations (NoOps), where systems scale, secure, and fix themselves. AI models will soon handle entire incident lifecycles automatically, allowing human teams to focus on design and long-term architectural improvements.
FINAL SUMMARY
The scale of modern cloud-native architecture has made traditional, manual IT monitoring obsolete. To keep up with complex microservices and rapid software updates, enterprises must transition toward automated, intelligent operations management. Mastering AIOps skills, earning professional certifications, and understanding modern AI observability frameworks allows engineers to eliminate operational toil and advance into high-value engineering roles. For enterprises, adopting AIOps through structured consulting and implementation services is essential for reducing downtime, lowering operational costs, and protecting user experiences. As the technology world moves closer to fully autonomous operations, staying ahead of the curve requires an ongoing commitment to learning. Embracing these advanced automation methodologies gives professionals and organizations the tools they need to lead the next generation of resilient digital platforms.