Upgrade & Secure Your Future with DevOps, SRE, DevSecOps, MLOps!
We spend hours scrolling social media and waste money on things we forget, but won’t spend 30 minutes a day earning certifications that can change our lives.
Master in DevOps, SRE, DevSecOps & MLOps by DevOps School!
Learn from Guru Rajesh Kumar and double your salary in just one year.
Introduction
Modern enterprise IT ecosystems are breaking records in terms of scale and architectural complexity. As organizations shift toward containerized microservices, multi-cloud platforms, and hybrid systems, the volume of telemetry data generated across infrastructure layers expands exponentially. For engineering and operations teams, this structural explosion has changed the core nature of daily work, often turning high-value engineers into full-time firefighters struggling against a non-stop wave of incoming issues. To overcome these structural bottlenecks, forward-thinking enterprise operations teams are moving beyond manual operations. Organizations are shifting toward advanced, data-driven platforms designed to ingest massive telemetry streams, group related system events dynamically, and resolve standard production failures instantly. Discovering the specialized educational resources, implementation playbooks, and strategic deep-dives hosted at TheAIOps.com provides operations teams with the clear blueprints and architectural knowledge required to execute this corporate transformation successfully.
Understanding IT Remediation
Definition of IT Remediation
IT remediation is the structured operational process of identifying, isolating, diagnosing, and resolving technical system failures, software bugs, security vulnerabilities, or performance bottlenecks across an enterprise computing environment. The ultimate goal of remediation is to return a degraded service or infrastructure component to its optimal operational baseline, protecting system availability and ensuring continuous service level agreement (SLA) compliance.
Traditional Remediation Processes
In a traditional IT environment, the remediation lifecycle is linear, slow, and heavily dependent on human intervention. The standard manual process follows a predictable, fragmented sequence:
- Symptom Alerting: A system component crosses a hardcoded threshold, generating a standalone alert.
- Manual Triage: An on-call engineer intercepts the alert, opens an operational ticket, and attempts to assess the overall severity.
- War Room Mobilization: For major issues, multiple cross-functional teams join an emergency troubleshooting call to share logs and coordinate diagnostics.
- Manual Root Cause Diagnostics: Engineers log into disparate servers, manually parsing text logs and executing command-line scripts to isolate the failure point.
- Manual Script Execution: A script or manual patch is deployed to fix the system, followed by human validation to ensure performance has normalized.
Challenges of Manual Intervention
Relying entirely on manual human workflows inside complex, highly distributed modern environments creates significant operational vulnerabilities:
- High Mean Time to Resolution (MTTR): Manually reading through millions of unstructured log lines across multiple microservices can stretch diagnostic timelines from minutes to hours.
- Human Errors during High-Stress Outages: Under intense pressure to restore critical enterprise revenue streams, engineers executing complex commands manually are vulnerable to making configuration mistakes that can compound an outage.
- Severe Alert Fatigue: Combing through endless queues of low-priority, duplicate notifications distracts engineering teams from critical production anomalies, causing them to miss genuine early warning signs of systemic failure.
Why Automation Is Becoming Essential
As digital infrastructure expands to encompass tens of thousands of ephemeral containers and distributed cloud endpoints, human operators can no longer keep pace with the sheer velocity of incoming operational events.
Manual incident management simply cannot scale to match modern development cycles. Introducing automated execution engines to handle routine triage and diagnostic tasks is no longer just an optimization strategy—it is an absolute architectural necessity to safeguard system uptime and protect engineering productivity.
What Is AIOps?
Definition of AIOps
Featured Snippet:
AIOps (Artificial Intelligence for IT Operations) is the strategic practice of combining big data, machine learning, and advanced analytics to automate and optimize enterprise IT operations workflows. By continuously ingesting and normalizing logs, metrics, traces, and events from across infrastructure silos, an AIOps platform filters out operational noise, maps real-time system dependencies, uncovers hidden performance patterns, and executes automated remediation tasks without requiring manual human intervention.
Core Principles of AIOps Platforms
An enterprise-grade AIOps platform operates as an intelligent central nervous system for digital environments, functioning across three core operational layers:
- Comprehensive Telemetry Ingestion: Acting as a massive data sponge, the platform ingests both structured and unstructured historical and real-time data from any infrastructure tier.
- ML-Driven Analysis: Machine learning models run continuously against data streams to isolate anomalies, suppress redundant alerts, and map system topology.
- Automated Action and Execution: The system converts analytical insights into fast, programmatic responses, triggering automated playbooks to fix known incident categories instantly.
AI and Machine Learning in Operations
AIOps eliminates the limitations of rigid, human-configured monitoring rules by applying advanced mathematical and data science models directly to production telemetry:
- Unsupervised Clustering Algorithms: These models analyze vast historical event streams to identify and group related notifications, condensing thousands of chaotic, duplicate alerts into a single, highly contextual incident.
- Dynamic Adaptive Baseling: Instead of using fixed limits, machine learning models continuously calculate normal performance ranges based on variables like time of day, seasonal traffic cycles, and historical application usage.
- Natural Language Processing (NLP): Advanced models parse millions of unstructured log lines in real time, instantly isolating rare error codes or suspicious trace strings hidden deep within infrastructure stacks.
Relationship Between AIOps and Remediation
AIOps serves as the brain, while automated remediation functions as the muscle. An automation engine requires precise, real-time context to execute actions safely; without intelligent data correlation, automated scripts run the risk of firing blindly against the wrong targets.
AIOps provides the critical diagnostic precision required, automatically mapping service dependencies and verifying the true root cause of an event. This ensures that the remediation framework executes the correct playbook against the exact component causing the failure.
Why Organizations Need Automated IT Remediation
Transitioning from manual troubleshooting to an automated IT remediation framework yields immediate, measurable returns across the entire enterprise ecosystem:
- Faster Incident Response: Automated systems intercept incoming anomalies at the speed of software, executing validation checks and running diagnostic playbooks within milliseconds of detection.
- Reduced Downtime: By resolving routine infrastructure failures—such as memory leaks or disk saturation—before they impact end-users, organizations protect customer facing availability and eliminate costly service outages.
- Improved Operational Efficiency: Automated triage removes repetitive, low-risk incidents from engineering queues, allowing teams to stop managing ticket lines and focus on high-value architectural improvements.
- Better Customer Experience: Resolving systemic performance lags before transactions fail ensures smooth application journeys, directly protecting brand reputation and digital revenue.
- Cost Optimization: Automating routine tasks minimizes expensive engineering escalations and optimizes resource allocation across cloud environments, ensuring systems run lean without sacrificing reliability.
How TheAIOps.com Supports Automated IT Remediation
Building an elite, self-healing production environment requires deep architectural insight and a clear understanding of advanced operational platforms. The educational resources and platform guides found at TheAIOps.com help enterprise teams bridge the gap between abstract machine learning theory and practical, real-world deployment.
Intelligent Event Correlation
The platform guide materials illustrate how advanced correlation engines ingest chaotic alert streams from fragmented application monitoring, cloud infrastructure, and network logging tools. By evaluating the precise timing of events and mapping them against real-time application topology, the system clusters hundreds of redundant, noisy alerts into a single, structured incident.
- Operational Benefit: Reduces ambient alert volume by up to 90%, preventing engineering teams from suffering from alert fatigue and surfacing the true scope of an issue instantly.
- Practical Example: If a core database server goes offline, it will trigger downstream alerts across dozens of connected microservices. Instead of opening fifty separate troubleshooting tickets, the platform correlates those alerts into a single incident that targets the core database issue.
Automated Incident Detection
Traditional systems rely on human eyes to spot problems on static dashboards. AIOps platforms automate this visibility layer by processing live streams of logs, traces, and metrics simultaneously, catching micro-failures as they occur.
- Operational Benefit: Eliminates human monitoring delays, identifying subtle systemic degradation before it impacts end-user transactions or breaches SLAs.
- Practical Example: The system tracks an incremental climb in transaction latency across an e-commerce checkout API, immediately flagging the micro-delay before it causes a widespread shopping cart failure.
Anomaly Detection Capabilities
By utilizing unsupervised machine learning models, the platform learns the unique behavioral rhythm of your production stack, establishing a fluid, dynamic baseline for every system metric.
- Operational Benefit: Captures unknown, complex system failures that would easily bypass traditional static monitoring thresholds.
- Practical Example: An application begins consuming an unusual amount of memory at 3:00 AM on a Tuesday. Because this deviates from the historical baseline for that specific time window, the system flags it as a high-priority anomaly, even though the total usage remains below a traditional 80% threshold.
Root Cause Analysis Automation
When an incident strikes, the platform evaluates the complete timeline of anomalous events and cross-references them with real-time dependency graphs to separate upstream causes from downstream symptoms.
- Operational Benefit: Eliminates hours of manual log parsing and collaborative guesswork, providing on-call engineers with the exact point of failure instantly.
- Practical Example: An infrastructure outage triggers a wave of web server timeout alerts. The root cause engine traces the failure back through service layers, pinpointing a faulty configuration change pushed to a central network switch minutes earlier.
Workflow Automation
Once an issue is diagnosed, the framework coordinates the response across your entire tool ecosystem, opening tickets in IT service management (ITSM) platforms, notifying communication channels, and triggering resolution tasks.
- Operational Benefit: Standardizes incident response protocols, ensuring that no critical diagnostic step or stakeholder notification is missed during an active outage.
- Practical Example: Upon identifying a critical application error, the system automatically opens a high-priority incident in ServiceNow, drops an alert with full context into a dedicated Slack channel, and assigns an on-call engineer via your paging platform.
Predictive Operations
Predictive models analyze historical performance trends to forecast future resource consumption patterns and potential operational degradation.
- Operational Benefit: Shifts the operations team from reactive firefighting to proactive prevention, allowing engineers to resolve vulnerabilities during normal business hours.
- Practical Example: The system analyzes storage consumption trends on an enterprise database volume, predicting that it will hit 100% capacity within 48 hours. It generates an early-warning alert, allowing engineers to expand the volume well before an outage occurs.
Self-Healing Capabilities
Advanced implementations connect intelligent analytical outputs directly to automated execution engines, allowing the system to remediate known infrastructure failures without requiring human approval.
- Operational Benefit: Achieves a near-zero MTTR for routine infrastructure incidents, completely protecting service availability around the clock.
- Practical Example: A memory leak causes a critical containerized microservice to freeze. The self-healing loop detects the failure, isolates the broken container, collects thread dumps for later analysis, and restarts the service within seconds.
Continuous Monitoring
The data engine never stops collecting and analyzing system telemetry, continuously retraining its underlying machine learning models to adapt to live infrastructure changes.
- Operational Benefit: Ensures that anomaly detection parameters and automated playbooks remain highly accurate as applications evolve and code updates are deployed.
- Practical Example: A engineering team deploys a massive application update that naturally changes the system’s baseline memory footprint. The continuous monitoring engine detects this shift and automatically updates its behavioral baselines, preventing a wave of false alerts.
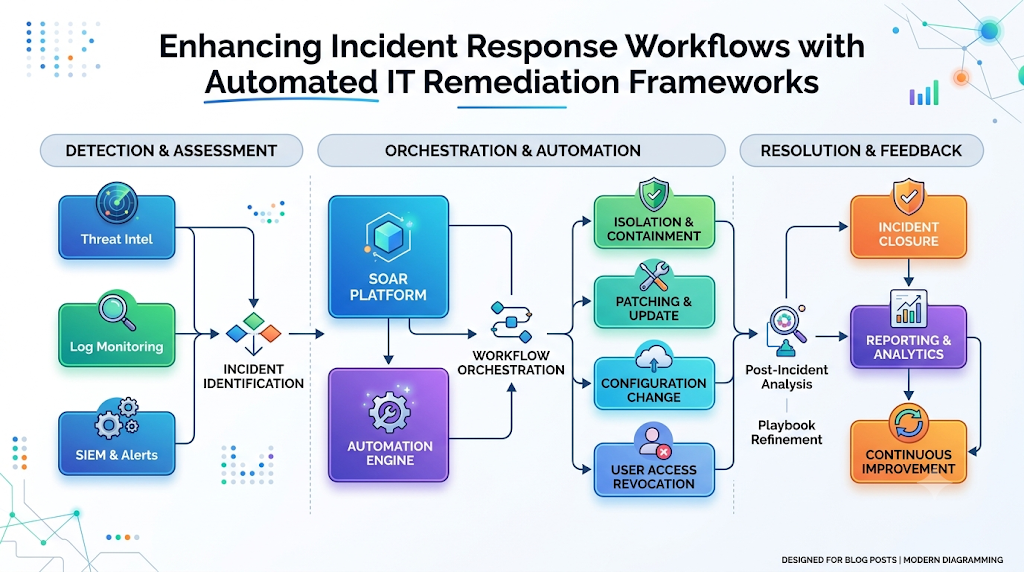
Key Components of an Automated Remediation Framework
A robust, enterprise-grade automated remediation framework requires the seamless integration of several core functional components:
- Monitoring Systems: The foundational sensory layer. These tools ingest raw logs, numeric metrics, and distributed traces from every application layer, server, and network switch, providing high-fidelity telemetry.
- Event Management: The processing layer. This component collects the raw telemetry, normalizes disparate formats, filters out redundant background noise, and uses dependency maps to group events into clean, actionable incidents.
- Automation Engines: The execution layer. A powerful policy and runbook engine that securely connects to target infrastructure, allowing it to run scripts, execute API calls, or trigger configuration playbooks.
- Incident Response Workflows: The orchestration layer. This manages communication and collaboration, integrating directly with enterprise ticketing systems, messaging platforms, and on-call rotations.
- Analytics and Reporting: The diagnostic dashboard. Provides comprehensive visibility into system health, tracking key automation metrics like execution success rates, noise reduction percentages, and overall time saved.
- Continuous Improvement Loops: The optimization phase. Post-incident analytics and machine learning model retraining ensure that automated playbooks and correlation rules are continuously refined over time.
Real-World IT Remediation Scenarios
To understand how an automated framework operates in practice, let us examine how the system manages common enterprise infrastructure failures compared to traditional, manual approaches:
| Infrastructure Layer | Incident Scenario | Automated Diagnostic Action | Automated Remediation Playbook | Operational Outcome |
| Server Performance | High CPU saturation on an application server. | Analyzes process logs to isolate the exact thread causing the spike. | Safely restarts the hung process and captures diagnostic dumps. | Server health normalizes within seconds; zero impact on end-users. |
| Application Layer | Memory leak causing a critical API service to freeze. | Pinpoints failing container via real-time distributed tracing. | Diverts traffic, spins up a fresh container instance, and tears down the old one. | Eliminates application downtime; collects data for root-cause analysis. |
| Cloud Infrastructure | Sudden, unexpected traffic spike saturating cloud compute. | Identifies threshold breaches across multiple web load balancers. | Triggers auto-scaling rules to provision extra virtual machine instances. | Dynamic load balancing protects performance; prevents site crashes. |
| Network Layer | High packet loss on a primary wide-area network router link. | Maps alternate network topology and assesses current link latency. | Modifies routing tables to automatically reroute traffic through a clean backup link. | Network performance stays smooth; avoids manual failover delays. |
| Database Tier | Deadlocks and resource saturation blocking database transactions. | Isolates the specific long-running, unoptimized SQL query. | Terminates the blocking session and surfaces the query to database administrators. | Database unfreezes instantly; avoids cascading application lockups. |
| Security Event | Rogue IP address attempting a brute-force SSH attack. | Detects hundreds of failed login attempts in system authentication logs. | Updates firewall rules instantly to permanently block the malicious IP. | Secures perimeter infrastructure; flags incident for SecOps review. |
Benefits of Using Automated Remediation
Deploying an intelligent automation framework across your operational environment fundamentally transforms your engineering team’s capabilities:
- Faster Mean Time to Resolution (MTTR): Compresses diagnostic and resolution timelines from hours to seconds by eliminating manual troubleshooting steps.
- Reduced Alert Fatigue: Filters out up to 90% of operational noise, allowing on-call engineers to maintain deep focus on genuine, high-priority system events.
- Improved Reliability: Mitigates human error during active outages by relying on standardized, pre-tested software workflows to execute system patches.
- Operational Scalability: Empowers lean infrastructure teams to manage growing cloud footprints without needing to increase engineering headcount.
- Consistent Incident Handling: Guarantees that every production failure is handled exactly according to enterprise compliance, security, and operational standards.
- Increased Productivity: Frees senior engineering talent from routine maintenance tasks, allowing them to focus on core product innovation and performance engineering.
Challenges in IT Remediation Automation
While the operational benefits are significant, organizations must navigate several common technical and organizational hurdles when building out their frameworks:
- Legacy Infrastructure: Older, monolithic systems often lack the comprehensive APIs and advanced logging capabilities required to support real-time automated intervention.
- Integration Complexity: Normalizing disparate data formats and connecting siloed monitoring systems across hybrid environments requires careful architectural planning.
- Managing False Positives: Poorly calibrated machine learning baselines can trigger automated remediation scripts unnecessarily, potentially creating new operational issues.
- Process Standardization: Automation requires clear, well-documented operational steps; automating an inherently chaotic or broken manual process will only accelerate failures.
- Change Management: Shifting operations teams from manual control to autonomous validation requires building organizational trust in machine learning decisions over time.
Best Practices for Successful Automation
To build a reliable, high-performance automated remediation framework, architecture teams should follow a structured, iterative implementation path:
1.Target Repetitive, Low-Risk Incidents:Phase 1.
Begin by mapping out your highest-volume, lowest-complexity tickets—such as simple disk-space expansion or routine service restarts. Automating these quick wins builds immediate momentum and establishes baseline safety.
2.Build Highly Contextual, Clear Workflows:Phase 2.
Ensure your remediation scripts are tightly integrated with your configuration management databases (CMDB). Workflows must validate system conditions before and after executing any corrective action.
3.Monitor Automation Engine Performance:Phase 3.
Track your automation framework as closely as you monitor production applications. Log execution runtimes, pass/fail ratios, and downstream system impacts to catch script errors early.
4.Establish Strong Governance Policies:Phase 4.
Define rigid operational boundaries specifying exactly when an automation engine can act autonomously and when it must pause to secure human engineer approval.
5.Continuously Refine Remediation Rules:Phase 5.
Conduct regular post-incident reviews to tune machine learning models, update dependency maps, and optimize playbook scripts based on real production outcomes.
AIOps Tools and Technologies Supporting Remediation
Building a scalable, autonomous IT operations stack requires coordinating specialized tools across multiple software tiers:
- Monitoring Platforms: Systems like Prometheus and Nagios capture real-time time-series performance data and hardware states from infrastructure layers.
- Observability Solutions: Platforms such as Datadog, New Relic, and Dynatrace track end-to-end distributed tracing, application logs, and deep microservice dependencies.
- Event Management & Correlation: Enterprise tools like BigPanda and Moogsoft excel at ingesting messy multi-tool event streams, filtering out noise, and isolating root causes.
- Automation Engines: Orchestration tools like Ansible, SaltStack, and Terraform execute code-driven configuration updates, container restarts, and safe cloud infrastructure rollbacks.
- Incident Management Systems: Work management platforms like ServiceNow, Jira Service Management, and PagerDuty track incident lifecycles, handle escalations, and log operational auditing trails.
Future of Automated IT Operations
The discipline of enterprise IT operations is moving rapidly toward a completely proactive model:
- Fully Autonomous Operations: Systems will evolve past simple script execution into self-directed platforms capable of dynamically writing and deploying their own corrective actions based on real-time needs.
- Advanced Predictive Remediation: Machine learning models will resolve latent software bugs and balance infrastructure loads days before a failure can manifest in production layers.
- Generative AI Integration: Operations engineers will design, test, and audit highly complex multi-cloud remediation playbooks using intuitive, natural language interfaces.
- Intelligent Self-Healing Infrastructure: Applications and underlying hardware layers will be designed from the ground up to automatically re-architect, scale, and secure themselves against systemic failures.
- Enterprise Hyperautomation: Organizations will connect all IT operational tasks into a single, unified automation layer, completely removing manual overhead from software delivery lifecycles.
Career Opportunities in AIOps and Automation
As organizations aggressively adopt automated remediation, demand for highly specialized infrastructure and data engineering talent is reaching historic highs:
- AIOps Engineer: Specializes in building high-throughput data ingestion pipelines, tuning operational machine learning models, and configuring enterprise event correlation layers.
- Site Reliability Engineer (SRE): Focuses on optimizing system availability, managing error budgets, and designing scalable automated infrastructure playbooks.
- Automation Engineer: Dedicated to writing clean, modular configuration code, integrating APIs across disparate tools, and designing self-healing workflows.
- Platform Engineer: Architect and maintain the underlying enterprise developer platforms, ensuring monitoring and automation frameworks are built directly into standard delivery pipelines.
- Operations Architect: Designs the big-picture strategy for enterprise IT environments, selecting tool stacks and mapping out comprehensive multi-cloud integration patterns.
Common Misconceptions About Automated Remediation
Myth: Automation completely eliminates the need for human IT engineers.
Reality: Automated remediation handles repetitive, well-understood tasks. This does not replace human intelligence; rather, it elevates it, allowing engineers to focus on architectural design, security strategy, and deep performance engineering.
Myth: Implementing automated remediation happens overnight.
Reality: Building a trusted, self-healing production ecosystem is a step-by-step journey. It requires systematically building data maturity, standardizing workflows, and refining scripts over time to ensure long-term stability.
Myth: Automation creates unacceptable security and stability risks.
Reality: When combined with rigid governance policies, strict role-based access control, and robust pre-execution checks, automated playbooks are significantly safer and more accurate than manual human intervention during a high-stress outage.
FAQ Section
1. What is the difference between standard IT automation and AIOps-driven remediation?
Standard IT automation relies entirely on static, human-configured triggers to execute basic scripts. AIOps-driven remediation uses advanced machine learning models to dynamically analyze telemetry streams, filter background noise, map system dependencies, and accurately diagnose the root cause of an incident before safely launching a targeted playbook.
2. How does automated remediation help reduce MTTR?
The framework compresses the entire incident response lifecycle by replacing slow human processes with software-driven execution. It intercepts system anomalies within milliseconds of detection, runs complex diagnostics instantly, isolates the root cause, and executes corrective playbooks immediately to restore service availability.
3. Can automated remediation scripts run safely in complex, multi-cloud environments?
Yes. By utilizing modern API abstraction layers and unified cloud configuration tools, advanced automation engines can seamlessly execute remediation playbooks across distributed on-premises networks and multiple cloud providers while maintaining central governance.
4. Will automating system fixes increase the risk of cascading production failures?
Not if built correctly. Robust frameworks include pre-execution checks, limits on how many times a playbook can run consecutively, and automated validation rules. If a script fails to normalize a metric on the first try, the system pauses execution and instantly escalates the issue to an on-call engineer.
5. How do machine learning models prevent alert fatigue for operations teams?
Machine learning models apply clustering algorithms to analyze incoming alert streams in real time. By evaluating event timing and referencing live dependency maps, the system groups thousands of duplicate or related alerts into a single, comprehensive incident, filtering out up to 90% of ambient background noise.
6. What are the best operational use cases to start with when introducing automation?
Organizations should always start with low-risk, high-volume, and repetitive technical incidents. Excellent initial candidates include expanding saturated disk volumes, clearing frozen application caches, restarting hung non-critical background services, or collecting thread diagnostic dumps during memory spikes.
7. How does topology mapping support automated root cause analysis?
Real-time topology mapping tracks the live behavioral dependencies between applications, underlying microservices, databases, and network hardware. When an outage occurs, the root cause engine references this structural map to trace causality, allowing it to easily separate secondary symptoms from the primary failure point.
8. Do we need an internal team of data scientists to deploy and manage an AIOps framework?
No. Modern enterprise AIOps solutions feature highly trained, out-of-the-box machine learning models and intuitive user interfaces. This design allows existing IT operations, DevOps, and SRE teams to configure correlation rules and deploy automated playbooks without needing advanced data science degrees.
9. What role do human engineers play once an infrastructure becomes fully self-healing?
Human engineers shift from reactive troubleshooting to proactive design and continuous improvement. They spend their time optimizing system architecture, updating automation playbooks, reviewing complex anomalies, strengthening infrastructure security, and focusing on high-value features.
10. How do we measure the overall return on investment of our remediation framework?
Organizations can track ROI by monitoring key operational performance indicators. Focus on measuring the overall reduction in MTTR, the drop in engineering escalations, the percentage of ambient alert noise suppressed, total system uptime improvement, and the hours of engineering time saved each month.
Final Summary
Navigating the operational realities of modern enterprise IT infrastructure requires moving decisively away from manual, reactive firefighting. Alert overload, complex microservice dependencies, and high-stress outages drain valuable engineering resources and threaten critical business availability. Transitioning to an intelligent automated IT remediation framework allows organizations to transform their incident response lifecycle—compressing resolution times from hours to seconds and eliminating up to 90% of background alert noise.