Upgrade & Secure Your Future with DevOps, SRE, DevSecOps, MLOps!
We spend hours scrolling social media and waste money on things we forget, but won’t spend 30 minutes a day earning certifications that can change our lives.
Master in DevOps, SRE, DevSecOps & MLOps by DevOps School!
Learn from Guru Rajesh Kumar and double your salary in just one year.
Introduction
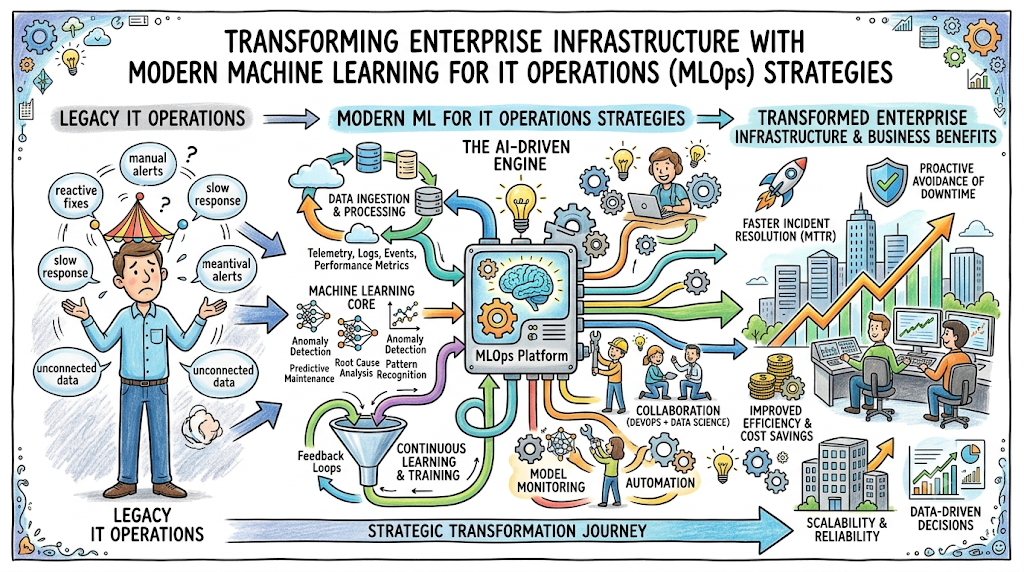
Modern enterprise technology stacks are too large, dynamic, and complex for human operators to manage manually. The rapid adoption of multi-cloud architectures, microservices, and continuous deployment pipelines has caused a massive data explosion. Systems generate terabytes of metrics, logs, and traces every day. Traditional monitoring tools rely on static thresholds and manual configuration, which fail completely at this scale. They overwhelm operations teams with alert fatigue while failing to provide actionable insights when critical incidents occur.
To overcome these challenges, enterprises are turning to AIOps, a discipline that combines big data and artificial intelligence to automate and improve IT operations. At the very core of this transformation is the deployment of machine learning algorithms designed to analyze massive datasets in real time. By shifting from rigid, rule-based systems to dynamic, algorithmic analysis, engineering teams can identify anomalies before they become outages, isolate root causes in seconds, and automate routine remediation tasks.
For organizations looking to navigate this shift, specialized resources like TheAIOps provide deep technical guidance on integrating data science with infrastructure management. Implementing machine learning within IT operations is no longer an experimental strategy for elite technology firms; it is a fundamental requirement for any enterprise aiming to maintain reliability, availability, and performance in a complex digital ecosystem.
Understanding Machine Learning in IT Operations
What Is Machine Learning?
Machine learning is a branch of artificial intelligence focused on building systems that learn from data, identify patterns, and make decisions with minimal human intervention. Instead of following explicitly programmed rules, machine learning algorithms process historical and real-time data to construct mathematical models that reflect the actual behavior of an environment.
- Definition: The practice of utilizing mathematical algorithms to analyze operational data, discover underlying patterns, and make predictions or classifications automatically.
- Why It Matters: It eliminates the need for engineers to manually write and maintain thousands of complex configuration rules for ever-changing infrastructure.
- Real-World IT Example: An algorithm analyzes historical CPU utilization on an application server over several months to learn that usage naturally spikes to 90% at 9:00 AM every Monday due to batch processing, meaning this specific spike should not trigger an emergency page.
- Problem Solved: Eradicates the manual overhead of updating static monitoring thresholds whenever software changes or infrastructure scales.
- Business Impact: Reduces operational overhead, minimizes false alarms, and allows highly skilled engineers to focus on innovation rather than system tuning.
In Simple Terms: Machine learning is like teaching an operations assistant through experience. Instead of giving the assistant a massive manual of strict rules for every possible scenario, you let them observe how the system runs normally over time. Eventually, the assistant learns what looks healthy and what looks broken entirely on their own.
Why IT Operations Need Machine Learning
Traditional operations rely on human operators reviewing dashboards and responding to alarms based on fixed limits. For instance, an alert might trigger if memory utilization exceeds 85%. However, in a modern cloud environment where hundreds of microservices scale up and down dynamically, setting static thresholds is impossible to maintain.
If the threshold is too low, engineers suffer from alert fatigue. If it is too high, critical degradations are missed entirely. Machine learning addresses this by introducing dynamic baselining. Algorithms continuously compute mathematical bounds for every metric, adjusting for time of day, day of the week, and seasonal business cycles.
Evolution from Traditional Monitoring to Intelligent Operations
The journey to intelligent operations follows a clear evolutionary path:
| Capability | Traditional Monitoring | Advanced Observability | Intelligent Operations (AIOps) |
| Data Focus | Disconnected infrastructure metrics | Unified metrics, logs, and traces | Multi-source data ingestion and topology maps |
| Analysis Style | Static, rule-based thresholds | Manual dashboard correlation | Algorithmic analysis and machine learning |
| Operational Stance | Reactive (responding after failures) | Proactive (debugging active issues) | Predictive (preventing issues before impact) |
| Remediation | Manual execution of runbooks | Scripted automation triggers | Intelligent, closed-loop self-healing |
Relationship Between Machine Learning and AIOps
Machine learning is the engine inside the AIOps framework. While AIOps represents the broader operational philosophy and data architecture—including data ingestion pipelines, topology mapping, and collaboration workflows—machine learning provides the intelligence. Without machine learning, an AIOps platform is simply a centralized data warehouse. The algorithms turn raw operational data into actionable intelligence, driving capabilities like automated root cause analysis and predictive monitoring.
Key Takeaways
- Machine learning replaces brittle, manual rules with dynamic, data-driven mathematical models.
- Traditional monitoring cannot scale alongside modern cloud-native architectures due to threshold complexity.
- AIOps relies directly on machine learning algorithms to convert raw telemetry data into automated insights.
Why Traditional IT Operations Struggle
Alert Overload
Enterprise operations teams are routinely bombarded by thousands of alerts every day. When an infrastructure component experiences a minor degradation, it often triggers a cascading waterfall of downstream alarms across networks, databases, and applications. Because traditional tools treat each alert as an isolated event, human operators must sift through overwhelming noise to find the actual issue. This alert fatigue leads to cognitive exhaustion, causing teams to accidentally ignore genuine, high-severity warnings.
Manual Root Cause Analysis
When an incident occurs, resolving it requires finding the root cause. In a legacy operational environment, this involves pulling engineers from different teams into a war room to manually inspect logs, search through command histories, and cross-reference metric graphs across disparate platforms. This manual correlation is slow, prone to human error, and extends the Mean Time to Resolution (MTTR), resulting in prolonged application downtime.
Growing Infrastructure Complexity
Modern software runs on ephemeral infrastructure. Containers, serverless functions, and service meshes constantly deploy, scale, and terminate across hybrid and multi-cloud environments. The relationships and dependencies between components change from minute to minute. Humans can no longer maintain an accurate mental model or static documentation of how software components interact, making manual troubleshooting completely ineffective.
[User Request] -> [API Gateway] -> [Microservice A] -> [Message Queue] -> [Microservice B] -> [Database]
| |
[Third-Party API] [Cloud Storage]
Figure 1: A simplified view of modern microservice dependencies where a failure at any node cascades unpredictably across the entire chain.
Reactive Incident Management
Traditional operations teams operate in a purely reactive state. They are notified of a problem only after a threshold has been breached, an internal health check fails, or an end-user files a support ticket. Operating reactively means the business always suffers damage—whether through lost revenue, disrupted productivity, or damaged customer trust—before engineers even begin the remediation process.
Data Silos
Large enterprises often feature fragmented organizational structures where different groups use completely different monitoring systems. Network engineers look at packet analyzers, database administrators monitor query logs, and developers track application performance monitoring software. These disconnected tools create severe data silos. Without a unified platform to ingest, normalize, and analyze all operational telemetry together, identifying cross-domain dependencies remains a manual, highly inefficient chore.
Key Takeaways
- Alert overload causes cognitive exhaustion, increasing the likelihood that critical system failures are missed.
- Manual root cause analysis in modern distributed systems takes too long, leading to expensive application downtime.
- Fragmented monitoring tools create data silos that block cross-domain visibility and slow down incident response.
How Machine Learning Transforms IT Operations
Pattern Recognition
Machine learning algorithms are exceptionally proficient at identifying subtle patterns across massive, high-dimensional datasets that are invisible to human observers. By continuously analyzing stream data from thousands of infrastructure components simultaneously, machine learning detects complex, multi-variable relationships. For instance, an algorithm can discover that whenever a memory leak occurs in a specific microservice, a minor network packet drop consistently happens three minutes prior on an adjacent switch, mapping hidden dependencies automatically.
Predictive Analytics
Rather than merely reporting what is currently happening or what has already occurred, machine learning introduces predictive analytics into IT operations. By executing statistical forecasting models on historical time-series data, these platforms project future system behavior. This allows operations teams to shift from a reactive state to a proactive stance, resolving resource exhaustion and performance bottlenecks before they degrade the end-user experience.
Intelligent Automation
Automation is only as effective as the logic that triggers it. Traditional automation relies on rigid statements: if variable X exceeds value Y, execute script Z. This becomes dangerous if variable X spikes due to a brief, harmless anomaly, leading to unnecessary restarts or resource provisioning. Machine learning provides intelligent automation by acting as an advanced decision layer. It ensures that automated remediation runbooks are executed only when the algorithm verifies a genuine, systemic issue.
Traditional: [Static Metric Threshold Breached] --------------------> [Trigger Automation Script] (Risky)
Machine Learning: [Metric Anomaly] -> [ML Context & Topology Analysis] -> [Validated True Incident] -> [Trigger Remediation] (Safe)
Operational Intelligence
Operational intelligence represents the capability to extract deep, contextual insights from messy, unstructured enterprise data. Machine learning models parse millions of raw log entries, categorize exceptions, extract recurring themes, and correlate them with infrastructure metrics. This transforms unreadable text streams into a clean, structured asset, giving leadership and technical teams a clear view of systemic health and operational efficiency.
Decision Support Systems
Machine learning does not replace human engineers; instead, it serves as a powerful decision support system. During high-severity incidents, an AIOps platform analyzes the active failure patterns, compares them against historical incident records, isolates the most probable root cause, and presents engineers with the exact remediation steps that successfully resolved the issue in the past. This dramatically cuts down debugging time and accelerates incident resolution.
In Simple Terms: Imagine trying to find a single broken wire inside a massive skyscraper using only a flashlight. That is manual IT operations. Machine learning acts like a digital twin of the building’s entire electrical grid, instantly lighting up the exact square inch where the failure occurred and explaining how to fix it.
Key Takeaways
- Pattern recognition uncovers hidden, multi-variable dependencies across diverse infrastructure layers.
- Predictive analytics allows operations teams to address upcoming system degradations before users notice.
- ML serves as an intelligent decision layer, preventing dangerous, accidental automation triggers.
Core Machine Learning Capabilities in AIOps
Anomaly Detection
Anomaly detection is the foundational capability of machine learning in IT operations. It replaces fixed thresholds with dynamic statistical boundaries that adapt to the environment automatically.
- Definition: The algorithmic process of identifying data points, events, or observations that deviate significantly from a dataset’s normal, historically established baseline.
- How It Works: Algorithms analyze historical time-series data to calculate a moving baseline of normal behavior that incorporates seasonality. The model then monitors live telemetry, raising a flag if data points fall outside these computed boundaries.
- Example: A sudden, unseasonal 40% drop in login requests at 2:00 PM on a Thursday is flag-tagged as an anomaly, even though the total traffic volume is technically within safe absolute operational limits.
- Benefits: Captures silent, complex degradations that do not breach traditional static thresholds, eliminating manual configuration work.
Event Correlation
Event correlation reduces the massive noise generated by modern enterprise tracking infrastructure by grouping related alerts together.
- Definition: The process of analyzing thousands of disparate, distributed system events to group related alerts into a single, cohesive incident context.
- How It Works: Algorithms evaluate incoming alerts based on spatial relationship (topology maps), temporal proximity (occurring within the same time window), and semantic similarity (matching text in log descriptions).
- Example: When a rack switch fails, instead of sending 300 individual alerts for every unreachable server and application downstream, the system groups them into one primary incident ticket titled “Switch Failure on Rack 4.”
- Benefits: Reduces total alert volume by up to 90%, preventing war-room confusion and helping teams focus on the source event.
Root Cause Analysis (RCA)
Root cause analysis accelerates incident resolution by tracing the path of a failure back to its origin point.
- Definition: The algorithmic identification of the underlying, primary driver responsible for an operational incident or performance degradation.
- How It Works: The system builds and references an enterprise topology map showing how hardware, cloud services, and software apps connect. When multiple anomalies trigger, graph algorithms track the flow of dependencies to find the initial failure node.
- Example: An algorithm traces a sudden transaction timeout error back through a web server, a middleware queue, and isolates the root cause to a specific database disk running completely out of IOPS capacity.
- Benefits: Eliminates manual, cross-team finger-pointing and slashes the Mean Time to Identify (MTTI) from hours to seconds.
Predictive Monitoring
Predictive monitoring shifts an operations team from a defensive posture to an offensive, preventative workflow.
In Simple Terms: Predictive monitoring is like weather forecasting for your IT systems. By looking at current atmospheric pressure, wind speeds, and historical seasonal data, meteorologists can tell you a storm is coming hours before the first raindrop hits. Predictive monitoring does the exact same thing for your servers and software applications.
- Definition: Using historical and active operational data streams to forecast upcoming performance issues or system failures before they physically manifest.
- How It Works: Time-series forecasting algorithms (such as autoregressive models or recurrent neural networks) extrapolate metrics into the future, checking if the projected trajectory intersects with dangerous system limits.
- Example: An algorithm tracks memory consumption on a critical microservice cluster and warns engineers that, based on current consumption trends, the system will trigger an Out-Of-Memory (OOM) crash in exactly 45 minutes.
- Benefits: Gives SREs and operations teams an early window to gracefully resolve resource constraints without customer disruption.
Capacity Forecasting
- Definition: The long-term projection of infrastructure resource demands to guide procurement, budgeting, and scaling strategies.
- How It Works: Regression models evaluate months of historical utilization data alongside business growth metrics to project compute, storage, and network requirements over quarters or years.
- Example: A cloud platform team receives an automated report stating that their object storage usage will exceed their current enterprise commitment limit in Q3, allowing them to negotiate pricing early.
- Benefits: Optimizes infrastructure spend, prevents emergency cloud over-provisioning costs, and ensures long-term system stability.
Alert Noise Reduction
- Definition: Filtering out non-actionable, transient, or duplicate notifications from the primary engineering alert queue.
- How It Works: Clustering and classification models evaluate historical alert patterns to identify short-lived spikes that self-heal quickly without human intervention, suppressing them automatically.
- Example: A brief CPU spike to 99% that lasts for less than 15 seconds during a routine container initialization is suppressed rather than paging an on-call engineer at midnight.
- Benefits: Prevents engineering burnout, stabilizes team morale, and ensures that critical alerts receive immediate attention.
Automated Remediation
- Definition: The self-healing execution of software runbooks to fix validated operational failures without requiring manual human labor.
- How It Works: Once an ML algorithm confirms a root cause with high mathematical confidence, it interfaces with automation platforms to trigger targeted, pre-approved resolution workflows.
- Example: Upon verifying that an isolated server node has frozen due to a specific thread deadlock, the system orchestrates a graceful container restart and diverts incoming traffic away during the boot sequence.
- Benefits: Achieves near-instantaneous resolution for known operational issues, freeing up human staff for higher-priority tasks.
Key Takeaways
- Anomaly detection catches subtle, complex system failures by calculating dynamic, seasonal baselines.
- Event correlation organizes thousands of individual notifications into a single, cohesive incident context.
- Automated remediation enables self-healing infrastructure by safely executing pre-approved runbooks when confidence scores are high.
Types of Machine Learning Used in IT Operations
To understand how these platforms function, it helps to look at the primary classes of machine learning algorithms applied to operational data.
Supervised Learning
Supervised learning models are trained on labeled datasets, meaning the input data is already paired with the correct output answer. In IT operations, this means training an algorithm on historical logs that humans have tagged as “normal performance,” “database error,” or “security breach.”
Once trained, the model evaluates new, unlabeled incoming data to classify it into these pre-learned categories. This approach is highly effective for predictive maintenance and alert classification, though it requires significant upfront human effort to properly label the training data.
Unsupervised Learning
Unsupervised learning algorithms process unlabeled data. They inspect the raw dataset without any human guidance to discover hidden structures, groupings, or patterns completely on their own. This approach is exceptionally valuable for IT operations because enterprise data is usually too vast and chaotic for manual labeling.
Clustering algorithms (like K-Means) group similar log messages together, while density-based models highlight outliers as anomalies. This allows organizations to uncover unknown system issues and understand new operational states without prior configuration.
Reinforcement Learning
Reinforcement learning models learn through a system of trial and error, guided by mathematical rewards and penalties within a defined environment. While less common in standard monitoring tools, reinforcement learning is increasingly used in advanced cloud cost optimization and auto-scaling engines.
The algorithm experiments with different infrastructure configurations—such as shifting workloads or adjusting container memory allocations—to maximize performance while minimizing cost, safely learning the most efficient operational strategies over time.
Deep Learning and Neural Networks
Deep learning uses multi-layered neural networks to analyze complex, high-dimensional datasets. In an enterprise environment, deep learning models are applied to full-stack observability challenges, such as parsing multi-domain log files, analyzing distributed execution traces, and processing natural language documentation.
These networks can comprehend intricate, non-linear relationships across thousands of distinct software components, driving advanced capabilities like automated root cause analysis in large-scale architectures.
Key Takeaways
- Supervised learning uses labeled historical data to accurately classify known operational issues.
- Unsupervised learning uncovers hidden system patterns and anomalies without requiring manual data labeling.
- Deep learning handles massive, complex datasets to map non-linear relationships across distributed environments.
Machine Learning Workflow in IT Operations
Deploying machine learning within enterprise operations follows a structured, continuous pipeline.
[Data Collection] -> [Data Cleaning] -> [Feature Engineering] -> [Model Training]
^ |
|------------------ [Real-Time Monitoring] <------- [Model Evaluation]
1. Data Collection
The workflow begins by collecting raw telemetry data from every layer of the enterprise technology stack. This includes streaming infrastructure metrics, unstructured system logs, distributed application traces, network packet data, and configuration management databases (CMDB). Data collection must happen continuously and at high velocity to fuel downstream real-time analysis engines.
2. Data Cleaning
Raw operational telemetry is notoriously messy. It contains missing data points, duplicate log entries, timestamp mismatches across different time zones, and irrelevant background noise. The cleaning phase standardizes and normalizes this incoming data. Timestamps are synced to a unified standard, empty fields are handled systematically, and unstructured text patterns are parsed into a uniform schema.
3. Feature Engineering
Feature engineering converts cleaned data into specific mathematical attributes that machine learning models can understand. For time-series metrics, this might involve calculating rolling averages, standard deviations, or rate-of-change indicators. For text logs, it means converting strings into numerical vectors that highlight the frequency and importance of specific error codes or system keywords.
4. Model Training
During the training phase, the prepared historical data is fed into chosen machine learning algorithms. The model adjusts its internal parameters to map out normal system behavior, establish seasonal baselines, and recognize known failure patterns. This training can occur offline using historical archives or continuously as new live stream data flows through the environment.
5. Model Evaluation
Before a model is trusted to trigger alerts or orchestrate automation in production, its performance must be evaluated. Data scientists and SRE teams validate the model using a separate testing dataset, checking key metrics like precision (avoiding false alarms) and recall (ensuring genuine incidents are not missed). Models that pass these validation gates are approved for deployment.
6. Real-Time Monitoring
The validated model is deployed into the production data pipeline to evaluate live telemetry streams. It continuously scores incoming metrics, logs, and events in real time, looking for deviations from normal baselines. When the model detects an anomaly or predicts an impending failure, it surfaces the insight directly within the operations team’s dashboard.
7. Continuous Improvement
Enterprise infrastructure is never static; software updates roll out daily, and cloud footprints scale constantly. This means machine learning models can experience “data drift” over time, gradually losing accuracy as the environment changes. To prevent this, the AIOps platform continuously collects human feedback (such as an engineer marking an anomaly as a false positive) and retrains the models on fresh data to maintain accuracy.
Key Takeaways
- Data cleaning is essential to normalize messy logs and synchronize mismatched timestamps across infrastructure domains.
- Model evaluation ensures high precision and recall before letting algorithms run live in production.
- Continuous retraining prevents data drift, keeping machine learning models accurate as software and infrastructure evolve.
Real-World Use Cases
Incident Prediction
- Problem: A global banking institution regularly suffered expensive outages when memory exhaustion caused their core transaction processing clusters to crash unexpectedly during high-volume trading hours.
- ML Solution: The bank deployed time-series forecasting models that analyzed live memory consumption trends, garbage collection metrics, and transaction velocities, extending visibility 60 minutes into the future.
- Outcome: The system accurately predicted impending memory exhaustion events, alerting on-call SREs early enough to safely route traffic away and restart nodes, reducing high-severity downtime by 78%.
Predictive Maintenance
- Problem: An industrial manufacturing enterprise experienced sudden storage array failures within their private data centers, halting supply chain management software for hours at a time.
- ML Solution: Supervised classification algorithms were trained on historical hardware telemetry, tracking parameters like disk read-write latency spikes, block errors, and fan speeds.
- Outcome: The model began identifying subtle hardware degradation signatures weeks before physical failure, allowing the infrastructure team to schedule disk replacements during routine maintenance windows.
Capacity Planning
- Problem: A logistics provider consistently over-provisioned their cloud resources by 40% to handle unpredictable demand spikes, leading to millions of dollars in wasted annual cloud expenditure.
- ML Solution: The company implemented regression models that evaluated years of seasonal shipment data alongside cloud utilization metrics to project exact infrastructure capacity needs.
- Outcome: The enterprise safely downsized over-provisioned clusters and aligned their cloud footprint with data-driven demand models, lowering infrastructure costs by 25% without sacrificing performance.
Cloud Resource Optimization
- Problem: A media streaming service struggled with massive cloud bills caused by developers spinning up large testing environments and leaving them idling over weekends and holidays.
- ML Solution: Unsupervised clustering models scanned the entire cloud footprint hourly, categorizing workloads based on active utilization patterns, network traffic, and CPU demand.
- Outcome: The AIOps system automatically identified idle, orphaned, or vastly over-provisioned environments and safely terminated or downsized them, saving the business significant monthly cloud spend.
Security Threat Detection
- Problem: A healthcare provider faced sophisticated insider threats where compromised user credentials were used to slowly exfiltrate sensitive patient data without triggering traditional firewall rules.
- ML Solution: User and Entity Behavior Analytics (UEBA) models established a baseline of normal daily activity for every credentialed employee, mapping access times, data transfer sizes, and target systems.
- Outcome: The system instantly flagged and blocked an account that suddenly began downloading thousands of medical records at 3:00 AM from an unusual IP address, preventing a severe data breach.
Network Performance Monitoring
- Problem: A telecom firm suffered from intermittent voice-call drops due to hidden routing loops and transient packet loss across their global software-defined network (SDN).
- ML Solution: Deep learning neural networks analyzed real-time network traffic paths, interface errors, and jitter metrics across millions of active connections simultaneously.
- Outcome: The model detected the exact combination of minor interface drops that caused the routing loops, automatically rerouting core traffic paths to clear network congestion within seconds.
Application Performance Monitoring (APM)
- Problem: A SaaS enterprise frequently dropped service level agreements (SLAs) due to intermittent microservice response latencies that manual tracing tools could not isolate.
- ML Solution: An AIOps platform mapped the entire application topology and applied anomaly detection across every single distributed microservice execution trace.
- Outcome: The platform instantly isolated latency spikes to a specific third-party API payment gateway that was responding slowly, allowing engineers to bypass the vendor and maintain their SLAs.
Key Takeaways
- Incident prediction gives technical teams a proactive window to protect end-user experiences before an outage occurs.
- Cloud optimization models save enterprises millions by identifying and reclaiming idle or over-provisioned infrastructure resources.
- Behavioral machine learning models spot sophisticated security threats that bypass standard, rule-based firewalls.
Machine Learning and Observability
Observability is the practice of measuring the internal states of a system by examining its external outputs—specifically metrics, logs, and traces. While traditional observability platforms excel at collecting and presenting this data on dashboards, machine learning provides the analytical power needed to understand it comprehensively.
Metrics Analysis
Metrics provide numerical data points over time, such as CPU utilization, disk throughput, or request counts. Machine learning enhances metrics analysis by providing multi-variate anomaly detection. Instead of evaluating each metric in a vacuum, algorithms analyze groups of related metrics simultaneously. For example, it evaluates the relationship between CPU utilization, thread count, and request rates to determine whether a spike represents healthy scaling or an active system failure.
Log Analytics
Log files provide a detailed history of events recorded by operating systems and applications. However, searching through millions of raw log lines manually during an outage is impossible. Machine learning structures this data by applying natural language processing (NLP) and log clustering. The system groups identical log messages together, strips out changing variables (like user IDs or transaction numbers), and highlights rare or entirely new error messages that appeared right alongside an incident.
Trace Analysis
Distributed tracing tracks the journey of a user request as it flows through various microservices across a network. A single end-user click can generate thousands of individual trace segments. Machine learning algorithms analyze this massive trace graph to establish baseline latencies for every single hop. When an application slows down, the algorithm scans the active trace paths, identifies the exact microservice dependency causing the bottleneck, and isolates the specific code-level method responsible.
[User Click]
|
v
[Gateway] --(Normal: 5ms)--> [Auth Service] --(Normal: 12ms)--> [Database]
|
+------(ANOMALY: 850ms)-----> [Inventory Service] <--- *ML isolates latency here*
Full-Stack Visibility
By combining metrics, logs, and traces into a unified topological model, machine learning delivers true full-stack visibility. It breaks down the historical boundaries separating infrastructure, databases, networks, and applications. When a failure occurs anywhere in the ecosystem, the machine learning engine traces the downstream impacts across the entire stack, helping teams understand exactly how an infrastructure fault affects business outcomes.
Key Takeaways
- Multi-variate metric analysis evaluates groups of related metrics simultaneously to understand true system health.
- Log clustering structures millions of unreadable lines of text, highlighting rare or new error signatures automatically.
- Trace-based machine learning maps distributed application pathways to isolate hidden microservice bottlenecks instantly.
Machine Learning for Incident Management
Incident management is the operational workflow focused on identifying, analyzing, and resolving system disruptions. Machine learning modernizes this entire lifecycle, shifting the organization from manual firefighting to automated precision.
Faster Detection
The classical incident response model depends heavily on human notification—either a user reporting a broken feature or an engineer noticing an elevated chart on a dashboard. Machine learning accelerates this phase by analyzing telemetry streams in real time. Because algorithms identify subtle anomalies long before they cross traditional threshold limits, incidents are captured at the earliest stages of degradation, often before any end-users experience an issue.
Intelligent Prioritization
When multiple systems experience issues at the same time, operations teams can struggle to determine which ticket to tackle first. Machine learning provides intelligent prioritization by evaluating the business and operational context of an incident. By referencing topology maps and business data, the system distinguishes between a staging server failure and a core production database degradation, routing and escalating tickets based on actual business impact.
Root Cause Discovery
In Simple Terms: Root cause discovery is like tracing a localized power outage in a massive neighborhood back to the single original circuit breaker that tripped. Instead of checking every house one by one, an automated diagnostic system maps the grid connections, skips the working circuits, and points you directly to the broken switch.
Machine learning replaces manual log searching and cross-team war rooms with automated root cause discovery. By tracking data dependencies across infrastructure layers, the algorithm identifies the primary event that triggered the cascading failure. This cuts down the time spent diagnosing problems, allowing engineering teams to immediately focus on fixing the issue.
Automated Response
The ultimate goal of incorporating machine learning into incident management is achieving safe, automated response capabilities. For well-understood incidents—such as disk space exhaustion, predictable traffic surges, or isolated software deadlocks—the machine learning engine triggers targeted recovery scripts. The system resolves the incident automatically, updates the tracking ticket with the diagnostic details, and closes the file without requiring a human engineer to log into a single terminal.
Key Takeaways
- Algorithmic analysis catches incidents during the early stages of system degradation, preventing major customer impact.
- Intelligent prioritization automatically ranks incidents by evaluating real-world business context and topology maps.
- Automated incident response loops safely resolve recurring, known issues without requiring human intervention.
Popular Tools Leveraging Machine Learning
Several enterprise platforms have integrated machine learning capabilities into their core architectures to deliver modern AIOps functionalities.
Dynatrace
- Primary Use Case: Full-stack observability and deterministic root cause analysis for large cloud environments.
- ML Capabilities: Utilizes a built-in, causal AI engine named Davis to continuously analyze dependency maps and topology.
- Operational Benefits: Delivers clear, precise root cause explanations for incidents rather than just statistical correlations, minimizing manual troubleshooting.
Splunk
- Primary Use Case: Enterprise log analytics, security information event management (SIEM), and operational intelligence.
- ML Capabilities: Features the Machine Learning Toolkit (MLTK) for building custom anomaly detection and forecasting models on log data.
- Operational Benefits: Translates petabytes of unstructured text logs into clear, actionable dashboards and real-time security alerts.
Datadog
- Primary Use Case: Cloud monitoring, application performance management, and infrastructure observability.
- ML Capabilities: Provides Watchdog, an automated AI engine that automatically surfaces anomalies, outliers, and log patterns.
- Operational Benefits: Requires zero configuration setup to begin surfacing hidden performance anomalies across complex cloud-native applications.
New Relic
- Primary Use Case: All-in-one observability and alert noise management for engineering teams.
- ML Capabilities: Employs machine learning algorithms for automatic alert correlation, incident grouping, and golden signal tracking.
- Operational Benefits: Reduces alert noise significantly, preventing on-call engineering fatigue and accelerating incident triage.
Moogsoft
- Primary Use Case: Collaborative enterprise incident management and cross-source alert noise reduction.
- ML Capabilities: Employs advanced unsupervised learning algorithms to ingest and deduplicate alerts from multiple monitoring tools.
- Operational Benefits: Integrates disparate IT systems together, filtering out noise and presenting a unified view of critical operational incidents.
BigPanda
- Primary Use Case: Event correlation and automated automation trigger management for large IT operations centers (NOCs).
- ML Capabilities: Uses Open Box Machine Learning to clean, normalize, and group fragmented IT alerts into plain-language incidents.
- Operational Benefits: Prevents war-room confusion by converting thousands of noisy, raw events into clear, actionable incident insights.
Elastic
- Primary Use Case: Scalable system search, security log analytics, and distributed infrastructure monitoring.
- ML Capabilities: Provides native time-series anomaly detection, classification, and log file categorization models directly inside the database engine.
- Operational Benefits: Allows teams to run real-time anomaly detection workflows directly on massive logs and security events at scale.
Key Takeaways
- Modern AIOps platforms leverage machine learning natively to replace manual monitoring setups with automated insights.
- Tools like Dynatrace focus on causal root cause analysis, while platforms like BigPanda excel at alert noise correlation.
- Integrating machine learning directly into your observability stack transforms raw data archives into active decision-making support.
Benefits of Machine Learning in IT Operations
Implementing machine learning across enterprise operations environments yields clear, quantifiable advantages for both technology and business teams.
- Reduced Downtime: By predicting system degradations early and accelerating incident isolation, enterprises minimize total system downtime, keeping revenue-generating digital services continuously available.
- Faster Incident Resolution: Machine learning slashes Mean Time to Resolution (MTTR) by eliminating hours of manual log searching, instantly providing engineers with the exact root cause and context.
- Better Resource Utilization: Capacity forecasting and optimization algorithms ensure that cloud footprints scale precisely alongside actual consumer demand, eliminating wasteful over-provisioning spend.
- Improved Reliability: Continuous dynamic baselining and proactive anomaly detection prevent fragile software regressions from degrading production environments, ensuring consistent system reliability.
- Enhanced User Experience: Eliminating performance bottlenecks and application latency ensures that end-users enjoy a fast, reliable, and smooth digital experience.
- Lower Operational Costs: Automating routine incident remediation tasks and alert triage reduces operational firedrills, allowing engineering teams to shift resources toward high-value innovation.
Challenges of Implementing Machine Learning in IT Operations
While the benefits are significant, enterprises frequently encounter specific obstacles when deploying machine learning within their operations workflows.
| Operational Challenge | Root Cause of the Issue | Practical Enterprise Solution |
| Data Quality Issues | Siloed systems, noisy log formats, and missing metric data points corrupt model accuracy. | Implement unified telemetry standards and rigorous data-cleaning pipelines before training. |
| Model Accuracy Challenges | Models generate false positives or miss subtle anomalies due to poor baseline calculations. | Use seasonal time-series models and adjust precision and recall settings using real historical data. |
| Integration Complexity | Fragmented legacy tools and multi-cloud environments resist central data aggregation. | Deploy modern AIOps platforms designed to ingest multi-source data through open APIs and standard frameworks. |
| Skills Gap | Operations teams often lack data science training, while data scientists rarely understand IT infrastructure. | Form cross-functional platform engineering teams that bridge the gap between data science and operational practices. |
| Trust and Explainability | Black-box AI recommendations make engineers hesitant to trust automated remediation scripts. | Prioritize explainable AI models that clearly present the supporting evidence and topology paths behind every insight. |
Key Takeaways
- High-quality, clean operational data is foundational to achieving accurate, trustworthy machine learning insights.
- Cross-functional collaboration between data science and infrastructure teams is essential to overcome skills gaps.
- Explainable AI models build engineering confidence by revealing the underlying logic behind automated recommendations.
Best Practices
To ensure a successful deployment of machine learning within your operations workflows, focus on these five core execution strategies.
Start with High-Value Use Cases
Avoid trying to automate your entire infrastructure overnight. Start by targeting a well-defined, high-volume operational pain point, such as alert noise reduction on a single critical application or capacity forecasting for a fast-growing storage tier. Achieving early success builds team confidence and validates the machine learning architecture.
Focus on Data Quality
The accuracy of any machine learning model depends directly on the quality of the data fed into it. Prioritize building clean, unified data pipelines. Standardize time logs, ensure consistent timestamp schemas across distributed servers, and eliminate junk notifications before passing telemetry streams into your machine learning models.
Continuously Train Models
Enterprise systems change constantly due to software updates, architecture adjustments, and shifting business demand patterns. Schedule continuous, automated retraining loops for your machine learning models to prevent data drift and ensure that your baselines remain aligned with active production realities.
Combine Human Expertise with ML
Keep human engineers in the loop, especially during the early phases of an AIOps rollout. Design systems where human troubleshooting validation helps train the underlying models. When an engineer marks an automated root cause recommendation as correct or incorrect, that feedback should feed directly into the model retraining loop to improve future accuracy.
Measure Operational Outcomes
Track clear metrics to measure the success of your machine learning initiatives. Monitor trends in Mean Time to Identify (MTTI), Mean Time to Resolution (MTTR), total monthly alert volumes, and the percentage of incidents resolved through automated workflows to prove the concrete business value of your investments.
Key Takeaways
- Begin with targeted, high-value projects like alert noise reduction to prove immediate operational value.
- Incorporate human engineering feedback into model training loops to systematically improve automated insights.
- Track key operational metrics like MTTR and alert volume reduction to measure the success of your AIOps strategy.
The Future of Machine Learning in IT Operations
The integration of machine learning into enterprise infrastructure is driving toward a highly automated, self-managing future.
Autonomous Operations
The long-term vision for enterprise infrastructure is the realization of fully autonomous operations. In this state, environments manage their own day-to-day operations with minimal human intervention. The underlying systems continuously monitor their own health, optimize resource allocations on the fly, adjust network routing paths, and deploy security patches dynamically based on real-time risk evaluations.
Self-Healing Systems
Self-healing systems will evolve from simple container restarts into sophisticated, adaptive architectures. When a machine learning engine identifies an active code performance regression or hardware failure, the infrastructure will automatically isolate the degraded components, spin up optimized alternatives, and initiate code rollbacks safely without causing any end-user disruption or requiring manual operator intervention.
AI-Driven Observability
Observability architectures will transition from passive, dashboard-centric telemetry collection models to active, AI-driven guidance frameworks. Instead of requiring human operators to build dashboards and hunt for anomalies, the observability stack will automatically instrument new services as they deploy, adapt data collection frequencies based on current system risk levels, and surface contextual insights proactively.
Intelligent Incident Prevention
Rather than focusing on rapid incident response after a failure has occurred, the core emphasis of enterprise operations will shift to intelligent incident prevention. Advanced predictive modeling systems will continuously simulate potential failure scenarios, analyze architectural risks, and remediate underlying software and configuration vulnerabilities long before they can cause an actual operational disruption.
Reactive (Past): [System Outage Occurs] -------> [Manual Troubleshooting] -> [System Restored]
Proactive (Present): [Anomaly Detected Early] ---> [ML Root Cause Isolation] -> [Rapid Fix Applied]
Preventative (Future): [Risk Pattern Modeled] ----> [Automated Self-Healing] -> [Outage Entirely Prevented]
Generative AI in AIOps
Generative AI and Large Language Models (LLMs) are quickly becoming powerful tools within AIOps architectures. Natural language interfaces allow operations teams to query complex, distributed environments using plain language questions like, “What caused the latency spike on the billing service yesterday morning?”
Furthermore, Generative AI models can instantly draft accurate incident post-mortems, generate targeted automation scripts to remediate validated infrastructure failures, and synthesize technical documentation to bridge the knowledge gap between data science and operational engineering teams.
Key Takeaways
- Autonomous operations will allow enterprise infrastructures to self-manage, self-tune, and self-secure with minimal human overhead.
- Generative AI provides plain-language interfaces to simplify troubleshooting across complex, multi-cloud architectures.
- The future of operations shifts focus completely away from rapid firefighting toward total, predictive incident prevention.
FAQ Section
- What is the difference between traditional IT monitoring and AIOps?
Traditional IT monitoring relies heavily on fixed, manually configured thresholds that sound an alarm only after a specific limit is crossed. This approach creates significant alert noise and fails to scale within complex, cloud-native architectures. AIOps integrates machine learning algorithms to ingest data from multiple systems simultaneously, automatically calculate dynamic, seasonal baselines, group related alerts together, and isolate root causes in real time.
- How does machine learning reduce alert fatigue for on-call operations teams?
Machine learning minimizes alert noise by applying event correlation and deduplication algorithms. Instead of letting every minor downstream system failure trigger an individual emergency page, the system evaluates alerts based on spatial relationships, time windows, and text descriptions. It groups hundreds of related notifications into a single, comprehensive incident ticket that identifies the root cause, filtering out irrelevant noise.
- Can machine learning completely replace human engineers in IT operations?
No, machine learning does not replace human engineers; instead, it serves as an advanced decision support system. Algorithms handle the heavy lifting of processing petabytes of raw data, filtering out background alert noise, and pinpointing the root causes of failures. This handles time-consuming diagnostic work, leaving human experts with the clear context needed to make informed choices and build long-term system improvements.
- What is dynamic baselining, and why is it better than static thresholds?
Dynamic baselining uses machine learning algorithms to continuously analyze historical time-series data, mapping out normal behavior patterns while adjusting for hours of the day, days of the week, and business seasonality. This is far superior to static thresholds because it prevents false alarms during natural, expected traffic spikes while catching subtle performance anomalies that occur well within normal absolute operational limits.
- How long does it typically take to train machine learning models on infrastructure data?
The initial time required to train an operational machine learning model depends on the specific use case, but most anomaly detection algorithms need between two to four weeks of historical data to establish reliable baselines that account for weekly business cycles. Advanced long-term capacity forecasting models may require several months of historical data to accurately factor in quarterly patterns and business trends.
- What is the difference between supervised and unsupervised learning in an AIOps context?
Supervised learning models are trained on datasets labeled by humans, making them highly effective for identifying known failure signatures and guiding predictive maintenance tasks. Unsupervised learning models process unlabeled data without human intervention, automatically discovering hidden anomalies, grouping similar logs, and highlighting unknown system issues that engineers haven’t predefined.
- How do machine learning models adapt when an enterprise updates its software or infrastructure?
Modern AIOps platforms manage changing environments through continuous model retraining loops and data drift detection. As developers roll out new software updates or modify cloud infrastructure configurations, the algorithms automatically process the new stream data and refine their baseline calculations, keeping the system aligned with production realities.
- What role does natural language processing play in modern log analytics?
Natural Language Processing (NLP) allows machine learning systems to read, understand, and structure messy, text-heavy log files generated across an enterprise. NLP algorithms parse millions of raw text lines, filter out variable data like user IDs or IP addresses, group identical messages into clean categories, and instantly highlight rare exceptions or error messages during an active incident.
- What are the main risks of implementing automated remediation with machine learning?
The primary risk of automated remediation is the accidental execution of recovery scripts due to a false positive anomaly, which can inadvertently disrupt stable systems. To prevent this, organizations should implement strict confidence scoring thresholds, ensure the system analyzes contextual topology maps before acting, and keep human approval steps in place for high-risk automated workflows.
- How should an enterprise begin its journey toward implementing machine learning for IT operations?
Organizations should begin their journey by focusing on a single, well-defined problem that offers high operational value, such as alert noise reduction on a problematic application cluster. Ensure you build clean data extraction pipelines for that specific area first, validate the accuracy of the model’s insights with your engineering team, and then expand the machine learning workflows across the rest of the enterprise stack.
Final Summary
Implementing machine learning for IT operations represents a fundamental shift in how modern enterprises manage, observe, and protect their digital infrastructure. By replacing brittle, manually configured rules with dynamic machine learning algorithms, organizations can easily scale alongside the data explosion generated by modern multi-cloud architectures.
AIOps capabilities—such as automated anomaly detection, event correlation, root cause analysis, and predictive monitoring—transform operational workflows from a reactive fire-fighting stance to a proactive strategy. Real-world enterprise use cases prove that integrating machine learning directly into operations pipelines delivers clear, measurable business value by reducing system downtime, optimizing cloud infrastructure spend, and accelerating incident resolution times.