Upgrade & Secure Your Future with DevOps, SRE, DevSecOps, MLOps!
We spend hours scrolling social media and waste money on things we forget, but won’t spend 30 minutes a day earning certifications that can change our lives.
Master in DevOps, SRE, DevSecOps & MLOps by DevOps School!
Learn from Guru Rajesh Kumar and double your salary in just one year.
Introduction
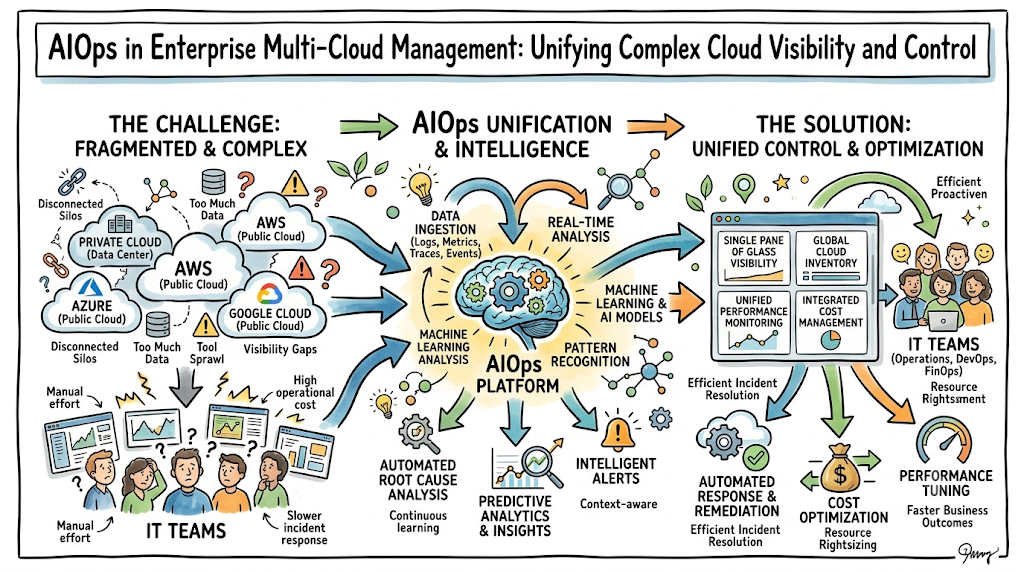
Modern enterprise IT infrastructures have fundamentally outgrown the confines of single-provider ecosystems. Today, organizations are executing a massive shift toward multi-cloud architectures, strategically distributing workloads across Amazon Web Services (AWS), Microsoft Azure, and Google Cloud Platform (GCP). While this strategy prevents vendor lock-in, optimizes operational costs, and ensures compliance with global data sovereignty laws, it introduces an entirely new layer of architectural friction. Managing fragmented infrastructure pools simultaneously fractures an enterprise’s visibility into its own services. Each hyperscaler relies on its own proprietary monitoring tool, native logging system, and unique billing logic. By implementing advanced AI-driven platforms, businesses can move past the limitations of traditional monitoring and build a highly connected operational framework. Leveraging specialized platforms like TheAIOps allows enterprise engineering teams to consolidate their cross-cloud monitoring utilities into a single, intelligent control system. This exhaustive blueprint details exactly how AIOps multi-cloud management eliminates tool fragmentation, delivers comprehensive cloud observability, and drives efficient, automated operations across diverse enterprise clouds.
Core Highlights: Key Takeaways
- Operational Unification: AIOps multi-cloud management overcomes tool fragmentation by consolidating telemetry data from AWS, Azure, and GCP into a single control layer.
- Intelligent Noise Reduction: Advanced machine learning algorithms eliminate cross-cloud alert storms by automatically clustering related events across disparate platforms.
- Proactive Governance: Integrating AI into multi-cloud operations transforms cloud optimization from a manual, retroactive auditing process into real-time, predictive scaling.
- Business Resiliency: Unifying visibility and automation across complex architectures lowers operational overhead, minimizes down-time risks, and ensures strict compliance with enterprise SLAs.
What is Multi-Cloud Management?
Multi-cloud management refers to the comprehensive framework of tools, governance policies, and engineering workflows required to configure, secure, monitor, and optimize IT workloads running across multiple public cloud infrastructure providers. Rather than treating each public cloud deployment as an isolated container, modern multi-cloud operations demand an integrated approach where applications seamlessly share data, scale dynamically, and fall back to alternative cloud networks when disruptions occur.
Enterprises adopt multi-cloud strategies for several distinct reasons:
- Risk Mitigation: Distributing core business systems across distinct cloud environments ensures that a major infrastructure failure at one public cloud provider will not crash the entire enterprise.
- Cost Efficiency: Different cloud providers offer competitive pricing advantages for specific workloads, allowing organizations to run heavy big data analytics on one cloud while using another for enterprise user identity control.
- Compliance and Localization: Global data protection laws often require businesses to store specific citizen datasets within exact geographic boundaries, making a multi-cloud strategy necessary for international expansion.
However, running a multi-cloud environment introduces difficult management challenges. Teams frequently struggle with inconsistent operational dashboards, conflicting security configuration parameters, and highly volatile data egress pricing models. Without a unified management approach, the financial and architectural benefits of adopting multiple cloud providers are completely canceled out by skyrocketing operational complexity.
What is AIOps?
AIOps, or Artificial Intelligence for IT Operations, represents the integration of big data engineering, advanced machine learning, and algorithmic automation directly into the tools used to manage enterprise infrastructure. It replaces manual, human-configured monitoring workflows with intelligent systems that ingest, normalize, and interpret massive volumes of real-time telemetry data produced by modern software ecosystems.
In large-scale application environments, AIOps platforms move past rigid static thresholds that trigger unhelpful notifications every time a server experiences a temporary traffic spike. Instead, the AI engine uses historical and real-time performance data to understand what normal operations look like across varying business seasons. This continuous learning enables the system to flag subtle infrastructure anomalies that indicate an approaching outage well before traditional monitoring setups notice a problem.
Furthermore, AIOps bridges the gap between cloud observability and actionable automated operations. While standard observability tools focus on collecting raw system metrics, logs, and distributed traces, an AIOps platform uses advanced machine learning models to analyze that data. It provides engineers with clear, context-rich root cause analysis and coordinates automated self-healing workflows across complex, distributed networks.
Why Multi-Cloud Needs AIOps
Managing a single cloud infrastructure setup is challenging enough, but expanding across multiple providers increases operational complexity exponentially. The most prominent issue teams face is severe tool fragmentation. When engineers are forced to jump between disparate monitoring tools like AWS CloudWatch, Azure Monitor, and GCP Cloud Logging during a critical production failure, the lack of a single interface slows down troubleshooting and drives up repair times.
This tool fragmentation leads directly to serious cross-cloud visibility issues. Legacy monitoring suites are inherently built to look inward at their own specific environments; they remain completely blind to dependencies running across external cloud networks. If a microservice deployed in an AWS cluster experiences sudden performance degradation because a backend API gateway hosted on Azure is dropping network packets, traditional monitoring tools cannot see the cross-cloud connection.
[AWS Monitoring Tool] <──(Blind Spot)──> [Azure Monitoring Tool]
│
No Cross-Cloud Dependency Mapping
Data inconsistency makes manual monitoring even harder. Every cloud provider formats its log files differently, utilizes custom metric naming conventions, and records timestamps with varying levels of precision. Manually compiling and cleaning these inconsistent data streams during a live application failure requires hours of developer time that should be spent fixing the actual bug.
At the same time, maintaining control over cloud optimization and infrastructure costs becomes incredibly difficult in multi-cloud environments. The sheer scale of ephemeral assets, such as autoscaling container pods and temporary serverless functions, makes tracking resource waste nearly impossible for human operators. Without intelligent, continuous monitoring, enterprises end up paying for over-provisioned cloud instances that sit completely idle.
Ultimately, the high operational complexity of multi-cloud architectures outpaces human scale. When a minor network issue triggers simultaneous alert storms across multiple cloud portals, the on-call team is hit with a wave of disconnected notifications. Multi-cloud environments need AIOps because machine learning is the only way to process millions of cross-cloud data points in real time and deliver clear, actionable operational insights.
How AIOps Improves Multi-Cloud Management
An AIOps platform improves multi-cloud operations by establishing a unified observability plane across all cloud environments. By integrating directly with public cloud infrastructure APIs, the AI engine brings all scattered logs, metrics, and distributed traces into a single control panel. This allows engineering teams to stop manually switching between different vendor dashboards and view their entire multi-cloud ecosystem through a single, clear interface.
[AWS Telemetry] ──┐
[Azure Telemetry] ─┼─> [AIOps Unified Observability Plane] ──> Single Control View
[GCP Telemetry] ──┘
Furthermore, AIOps uses advanced cross-platform incident correlation to cut through alert noise during system outages. When an underlying infrastructure issue triggers a wave of downstream notifications across different cloud environments, the machine learning engine reviews the timing and topology of the alerts. It automatically links those related warnings together, consolidating thousands of separate system notifications into a single, cohesive incident ticket.
AWS Alerts (500) ──┐
Azure Alerts (300) ─┼─> [AIOps Incident Correlation Engine] ──> 1 Unified Incident Ticket
GCP Alerts (200) ──┘
The platform also provides highly intelligent anomaly detection that adapts to changing cloud workloads. Instead of relying on manual configurations, the machine learning models analyze historical resource usage to understand normal variations for each cloud provider. This allows the system to easily differentiate between a normal, expected traffic surge and a genuine performance anomaly, minimizing false alarms and reducing alert fatigue.
Additionally, AIOps simplifies incident response through automated incident routing. Once an anomaly is identified, the system calculates the impact on the business and immediately forwards the ticket to the exact team responsible for that specific cloud environment. By attaching rich diagnostic logs and clear root cause insights directly to the ticket, the platform cuts out manual triage steps and accelerates resolution workflows.
Finally, AIOps introduces predictive cloud resource management, transforming how enterprises handle capacity planning. The platform continuously tracks historical workload patterns across all cloud regions to forecast future compute and storage requirements. It then automatically scales down over-provisioned infrastructure during quiet periods and claims extra resources ahead of predictable traffic spikes, balancing performance with cost efficiency.
AIOps Architecture for Multi-Cloud Environments
To deploy an effective AIOps multi-cloud management strategy, organizations must build an open, multi-layered architecture designed to process massive, distributed streams of telemetry data. The system relies on a clean decoupling of data collection, processing, and visualization layers to ensure seamless operations across different cloud environments.
┌─────────────────────────────────────────────────────────────────┐
│ VISUALIZATION DASHBOARDS │
│ (Unified Control Panel, Cross-Cloud Mapping, Business ROI) │
└────────────────────────────────┼────────────────────────────────┘
▲
┌────────────────────────────────┴────────────────────────────────┐
│ INCIDENT INTELLIGENCE LAYER │
│ (Root Cause Isolation, Context Enrichment, Route Automation) │
└────────────────────────────────┼────────────────────────────────┘
▲
┌────────────────────────────────┴────────────────────────────────┐
│ AI/ML CORRELATION ENGINE │
│ (Topology Mapping, Time-Series Forecasting, Cluster Analysis) │
└────────────────────────────────┼────────────────────────────────┘
▲
┌────────────────────────────────┴────────────────────────────────┐
│ NORMALIZATION & DATA UNIFICATION │
│ (OpenTelemetry Standardization, Metadata Enrichment) │
└────────────────────────────────┼────────────────────────────────┘
▲
┌────────────────────────────────┴────────────────────────────────┐
│ DATA INGESTION LAYER │
│ (AWS CloudWatch, Azure Monitor, GCP Cloud Logging) │
└─────────────────────────────────────────────────────────────────┘
The Data Ingestion Layer
This initial layer serves as the foundation for multi-cloud integration, using secure API connections, streaming webhooks, and lightweight collection daemons to pull real-time data from every provider. It handles a constant stream of raw telemetry data, including platform logs from AWS CloudWatch, compute performance metrics from Azure Monitor, and container traces from GCP Cloud Logging.
Normalization and Data Unification Layer
Because raw telemetry arriving from different clouds uses wildly inconsistent naming styles, this layer standardizes all incoming records into a uniform format using OpenTelemetry guidelines. It rewrites disparate syntax styles into standardized keys, harmonizes time stamps across varying time zones, and adds helpful metadata tags detailing application names, deployment zones, and resource owners.
The AI/ML Correlation Engine
The standardized data streams feed directly into the central processing core, which runs advanced mathematical models designed for high-volume analysis. This engine uses topology mapping algorithms to understand active dependencies across cloud environments, applies time-series forecasting to predict performance trends, and utilizes clustering models to group related system alerts together.
Incident Intelligence Layer
Once the core engine flags a significant system pattern, this operational layer builds a detailed diagnostic file around the incident. It automatically isolates the root cause of the anomaly, attaches relevant code repository logs, and uses predefined runbooks to coordinate automated remediation steps across the target cloud infrastructure.
Visualization Dashboards
The top of the architecture features a clean, unified dashboard that gives engineering teams complete visibility into their entire multi-cloud operations. It replaces individual vendor monitoring portals with an interactive control panel that maps cross-cloud dependencies, displays real-time health scores, and highlights automated system fixes.
Step-by-Step Multi-Cloud AIOps Workflow
Implementing an AIOps multi-cloud management platform establishes a structured, automated workflow that processes raw system signals and transforms them into clear, resolved operational events. This continuous loop removes manual friction from every stage of the incident management lifecycle.
Step 1: Real-Time Cross-Cloud Data Collection
The workflow begins with the continuous collection of telemetry data from every live cloud provider. Secure collectors stream infrastructure logs, microservice metrics, and distributed traces from all active cloud accounts directly to the central processing engine without interrupting production workloads.
Step 2: OpenTelemetry Standardization
As data arrives, the platform cleans and standardizes the disparate logs and metrics. The system normalizes varying terminology definitions into a consistent format and synchronizes time records, creating a dependable data foundation for cross-cloud analysis.
Step 3: Real-Time Performance Baseline Monitoring
The standardized data streams are continuously compared against dynamic performance baselines calculated by the machine learning models. The AIOps platform tracks metrics across all cloud regions simultaneously, learning how system resource usage fluctuates across different hours, days, and business seasons.
Step 4: Algorithmic Anomaly Detection
When real-time telemetry data drifts away from established baselines—such as an unexpected spike in container memory usage in an Azure cluster—the platform flags it as an active system anomaly. It instantly reviews the surrounding context to verify if the change matches an authorized software release or a known traffic spike.
Step 5: Cross-Cloud Event Clustering
If the anomaly is verified as an active issue, the engine scans the wider multi-cloud network for related system alerts. It automatically clusters separate warnings—such as downstream timeout errors in AWS or database latency flags in GCP—into a single, consolidated incident ticket, blocking unhelpful alert storms.
Step 6: Topology-Driven Root Cause Identification
The clustered incident is then analyzed alongside live infrastructure dependency maps to find the source of the issue. The AIOps engine traces connections across clouds, pinpointing the exact microservice, database query, or configuration update that triggered the failure cascade.
Step 7: Automated Remediation and Fixing Triggers
With the root cause found, the platform checks its library of authorized operational runbooks. For verified issues, it fires automated API triggers to fix the infrastructure—such as scaling up container clusters or updating routing tables—resolving the problem instantly without needing manual intervention.
Key AIOps Capabilities in Multi-Cloud Systems
A foundational technical requirement for managing modern infrastructure is true cross-cloud observability. Traditional cloud monitoring solutions are fundamentally designed to track isolated infrastructures, forcing operations teams to manually piece together different data sets. A comprehensive AIOps platform breaks down these walls by collecting metrics, logs, and distributed traces from all public and private cloud networks into a single processing system, allowing engineers to trace complex user transactions across different environments effortlessly.
Workload intelligence forms another critical capability, using unsupervised machine learning models to analyze application performance trends over long periods. Instead of relying on simple static alerts, the system studies how container deployments, database workloads, and application compute threads behave across different cloud platforms. This allows the software to notice tiny drops in database efficiency or subtle network latency issues long before those glitches can affect end users.
Long-Term Telemetry Trends ──> [Workload Intelligence Models] ──> Proactive Microservice Tuning
Cost optimization insights are also a major feature, integrating FinOps principles directly into daily multi-cloud operations. The AIOps engine continuously scans your cloud billing records and real-time compute usage data across AWS, Azure, and GCP to pinpoint financial waste. The platform identifies idle servers, highlights over-provisioned database storage, and automatically suggests rightsizing recommendations to help cut cloud spending without hurting system performance.
Security anomaly detection is integrated directly into the system monitoring flow, rather than running as a disconnected security tool. The machine learning models analyze user access logs, API call patterns, and network traffic flows across all cloud regions to spot potential security threats. If an internal service account unexpectedly attempts to download large volumes of data from an isolated cloud database, the platform flags the unusual behavior and locks down access immediately.
Finally, live dependency mapping tracks the complex, changing connections that tie modern multi-cloud systems together. The AIOps platform automatically discovers and draws updated maps of every relationship connecting your front-end apps, container nodes, data stores, and third-party APIs. When an infrastructure failure occurs, this live map allows the engine to immediately see how a broken database component in one cloud region impacts dependent applications running elsewhere.
Real-World Use Cases
Hybrid Enterprise Infrastructure Monitoring
Large financial enterprises often run core customer records on secure, on-premises mainframes while deploying modern customer-facing web apps across public clouds like AWS and Azure. When a backend system slow-down occurs, traditional tracking tools struggle to trace the issue across the split infrastructure, leading to long delays and finger-pointing between teams. An AIOps platform solves this by monitoring data flows across the entire hybrid network, automatically tracking the latency back to a specific database lock on the local mainframe and allowing teams to resolve the issue in minutes.
Multi-Region SaaS Platforms
Global Software-as-a-Service (SaaS) providers deploy identical application stacks across multiple geographical regions and different cloud vendors to maintain high uptime. If an overseas network provider experiences a major routing failure, it can trigger a wave of downstream container errors across various cloud consoles. An AIOps engine manages this by analyzing the entire incident from a global perspective, grouping the separate alerts together, and rerouting user traffic to healthy cloud regions automatically to keep the application online.
Global E-Commerce Systems
During high-traffic holiday shopping events, e-commerce networks depend on complex systems spanning multiple clouds, using one platform for user checkout flows and another for inventory management. If an unexpected microservice failure causes checkout screens to hang, finding the bug manually during a high-pressure shopping rush is incredibly stressful. An AIOps platform monitors the complete transaction path in real time, isolates the issue to a misconfigured container limit on one of the platforms, and automatically adjusts the resource settings to restore smooth checkout operations.
Financial Services Cloud Resilience
Banking apps require continuous uptime to process transactions safely and maintain user trust. To ensure high availability, these organizations use multi-cloud designs that replicate data across completely independent cloud platforms. When an unexpected storage failure occurs on one provider, the AIOps engine instantly detects the drop in performance, verifies that the backup platform is fully synchronized, and switches user traffic over to the healthy cloud environment without any manual intervention.
DevOps Platform Engineering Teams
Modern platform engineering departments manage internal development platforms that provision thousands of temporary testing environments every day across AWS and GCP. Without smart automation, tracking down abandoned developer servers, forgotten testing databases, and orphaned storage disks becomes a tedious, time-consuming task. An AIOps platform solves this by scanning all active cloud accounts, flagging unutilized resources, and automatically cleaning up idle environments to keep cloud costs under control.
Benefits of AIOps in Multi-Cloud Management
| Strategic Benefit | Core Metric Impact | Real-World Operational Outcome |
| Unified Visibility | Eliminates 100% of portal switching. | Operations teams view AWS, Azure, and GCP metrics inside a single interface, breaking down data silos. |
| Reduced Operational Overhead | Reduces manual alerts by up to 90%. | Machine learning filters out repetitive alert noise, allowing engineers to focus on high-priority projects. |
| Faster Incident Resolution | Reduces MTTR significantly. | The system finds root causes automatically, replacing hours of manual log checking with instant, actionable fixes. |
| Better Resource Utilization | Lowers monthly cloud spending. | Continuous resource auditing ensures companies only pay for the cloud infrastructure they actually use. |
| Improved System Reliability | Minimizes high-priority outages. | Predictive tracking flags infrastructure issues early, letting teams fix bugs before they can impact end users. |
Challenges in Multi-Cloud AIOps Adoption
A major obstacle when implementing an AIOps multi-cloud management strategy is breaking through data silos between different cloud vendors. Public cloud providers design their logging and metrics systems to keep users inside their own ecosystems, using custom data structures that make cross-platform sharing difficult. Overcoming these built-in silos requires teams to spend extra effort creating unified data aggregation pipelines before the AI models can even begin processing metrics.
Integration complexity also creates difficulties during initial setup. Connecting a centralized AIOps engine to dozens of separate cloud accounts, container clusters, legacy databases, and security systems demands careful planning and configuration. If the data pipelines are not set up securely, the monitoring layer can introduce new performance bottlenecks or create maintenance headaches for the platform team.
Cloud Accounts + Container Clusters + Legacy Assets ──> [Integration Friction] ──> Setup Delays
Furthermore, organizations must balance their monitoring workflows with strict security and compliance constraints. Telemetry data frequently contains sensitive business information, including customer IP addresses, user metadata, or protected financial records. Shipping this data across different cloud environments to a centralized analytics system requires robust encryption and thorough compliance auditing to avoid data privacy violations.
At the same time, processing huge data volumes generated by modern, multi-cloud architectures places a heavy tax on computing resources. Analyzing millions of data points every second across global cloud networks requires significant processing power and can lead to expensive network egress charges if data is transferred carelessly. Finally, there is a prominent skills gap within many enterprise infrastructure teams, as managing an AIOps setup requires engineers to be skilled in both traditional system administration and advanced data analytics.
Best Practices for Implementation
To maximize the value of your AIOps multi-cloud management platform, your first step must be standardizing your observability pipelines. Avoid using custom collection tools for each individual application; instead, deploy open-source collection standards like OpenTelemetry across your entire software stack. This ensures all logs, metrics, and traces use consistent formats and metadata tags, no matter which cloud provider hosts the workload.
Next, focus on building and maintaining a unified data model across all engineering departments. Enforce strict naming rules for all infrastructure assets, including clear tags that identify application names, cost centers, and team ownership across AWS, Azure, and GCP. This structured labeling allows the machine learning models to map dependencies across different clouds accurately and surface reliable insights.
Unified Asset Labels (App Name, Cost Center, Owner) ──> Highly Accurate Machine Learning Mapping
You should also prioritize automating alert correlation as early as possible in your deployment timeline. Work closely with your engineering teams to identify your loudest, least helpful infrastructure notifications, and configure the AIOps engine to filter out that background chatter at the source. Eliminating this alert noise lets your teams focus their attention on complex incidents that threaten system uptime.
At the same time, align your AIOps workflows with your company’s broader cloud governance policies. Ensure that any automated actions triggered by the AI engine—like scaling up container groups or changing network routes—comply fully with your internal security and change management rules. Finally, make it a regular habit to tune your machine learning models using real-world feedback from actual incidents, adjusting system sensitivity over time to keep insights highly accurate.
Future of Multi-Cloud AIOps
The future of multi-cloud management is shifting rapidly toward fully autonomous cloud operations. We are quickly moving past the era where AI tools simply alert engineers to system issues; next-generation platforms will manage cloud ecosystems independently from start to finish. These intelligent platforms will provision infrastructure, adjust network paths, and fix software errors across different cloud networks without needing any manual approval from a human operator.
We will also see a deep integration between automated cloud spending control and real-time incident management, a practice known as AI-driven cost governance (FinOps + AIOps). Future management platforms will not just track performance metrics; they will analyze the real-time financial impact of architectural choices. The platform will automatically shift workloads between cloud providers in real time to capitalize on lower compute pricing while keeping performance optimized.
Live Cost + Performance Signals ──> [FinOps + AIOps Engine] ──> Automatic Workload Migration
This evolution will make self-healing cloud systems standard practice across the enterprise landscape. By combining predictive anomaly detection with automated code deployment tools, multi-cloud networks will independently fix their own internal bugs before they cause a noticeable drop in performance. If a cloud region encounters a hardware issue, the system will move application data to a healthy provider automatically, operating completely unseen by end users.
Finally, large language models will become a standard fixture inside modern cloud management offices, acting as intelligent cloud operations assistants. These advanced assistants will allow developers to monitor, configure, and troubleshoot global multi-cloud networks using natural, everyday language. Engineers can simply ask the assistant to analyze an infrastructure trend or verify a deployment state, making cloud management more accessible and faster than ever before.
Key Takeaways
- Exponential Complexity: Expanding across multiple public cloud networks creates deep visibility gaps and tool fragmentation that traditional monitoring cannot handle.
- Unified Control: An AIOps platform brings together disconnected multi-cloud telemetry data, providing a single, comprehensive view of your entire infrastructure.
- Smart Noise Filtering: Algorithmic event correlation eliminates alert storms, helping operations teams isolate root causes and fix bugs faster.
- Autonomous Scaling: The future of cloud management relies on automated, self-healing architectures that optimize performance and cloud costs in real time.
FAQ Section
1.What is multi-cloud management?
Multi-cloud management is the strategic combination of software utilities, operational workflows, and security governance frameworks used to deploy, track, and optimize software applications running across multiple public cloud infrastructure vendors like AWS, Azure, and GCP. It provides a structured approach to managing distributed cloud environments safely and efficiently.
2.How does AIOps help in multi-cloud environments?
An AIOps platform helps multi-cloud management by pulling disconnected logs, performance metrics, and distributed traces from various cloud networks into a single, unified observability dashboard. The platform uses machine learning models to filter out alert noise, connect related events across cloud platforms, and isolate the root causes of complex system errors automatically.
3.What are the challenges of multi-cloud systems?
The biggest challenges when running multi-cloud systems include tool fragmentation across different vendor dashboards, cross-cloud visibility blind spots, inconsistent log data formatting, unpredictable network egress charges, and the high operational complexity of tracking ephemeral resources manually.
4.What tools are used for AIOps in cloud operations?
AIOps architectures combine data collection systems like OpenTelemetry, scalable streaming platforms, machine learning processing components, and automated remediation systems. These tools work together to collect infrastructure data, find patterns, and trigger fixes across your entire cloud footprint.
5.Is AIOps necessary for AWS and Azure together?
Yes, deploying AIOps becomes highly necessary when running AWS and Azure together. Because both hyperscalers use completely different logging structures, monitoring portals, and alert rules, an AIOps layer is required to connect those data silos and give engineers a single, accurate view of cross-cloud dependencies.
6.How does AIOps improve cloud observability?
AIOps improves cloud observability by transforming raw telemetry data into actionable operational insights. Instead of simply collecting data and waiting for a human to analyze it, the AI engine studies system behaviors in real time, flags subtle performance anomalies, and explains exactly how a failure impacts the business.
7.What is cross-cloud event correlation?
Cross-cloud event correlation is the automated process where an AI engine analyzes separate alerts triggered simultaneously across different cloud networks and determines if they share a common root cause. This prevents on-call engineers from being overwhelmed by duplicate alerts, grouping symptoms together into a single actionable ticket.
8.Can AIOps reduce cloud costs?
Yes, AIOps platforms are highly effective at lowering cloud costs by integrating real-time resource monitoring with automated cost controls. The system scans all active cloud environments to find idle servers, point out over-provisioned databases, and provide smart rightsizing tips that cut spending without hurting application performance.
9.Is multi-cloud better than single cloud?
A multi-cloud strategy offers great advantages for large enterprises by preventing vendor lock-in, lowering downtime risks, and meeting strict global data privacy rules. However, it increases management complexity significantly, meaning organizations need to adopt strong automation tools like AIOps to make the multi-cloud setup truly successful.
10.How can beginners learn AIOps for cloud management?
Beginners looking to build a career in cloud automation should focus on mastering cloud-native architecture patterns, learning open data collection standards like OpenTelemetry, and understanding basic machine learning principles. Following educational guides and industry deep-dives on platforms like TheAIOps provides an excellent path to mastering these core operational skills.
Conclusion
Successfully running a modern multi-cloud infrastructure requires moving past the limits of traditional, manual monitoring workflows. While deploying systems across AWS, Azure, and GCP provides enterprises with unmatched flexibility and operational resilience, the resulting tool fragmentation and visibility gaps can quickly overwhelm human engineering teams. Trying to manage highly distributed, fast-changing workloads using disconnected cloud portals inevitably leads to extended downtime, alert storms, and climbing cloud costs. Integrating an AIOps multi-cloud management platform provides organizations with the centralized intelligence and automated power needed to tame this structural complexity.