Upgrade & Secure Your Future with DevOps, SRE, DevSecOps, MLOps!
We spend hours scrolling social media and waste money on things we forget, but won’t spend 30 minutes a day earning certifications that can change our lives.
Master in DevOps, SRE, DevSecOps & MLOps by DevOps School!
Learn from Guru Rajesh Kumar and double your salary in just one year.
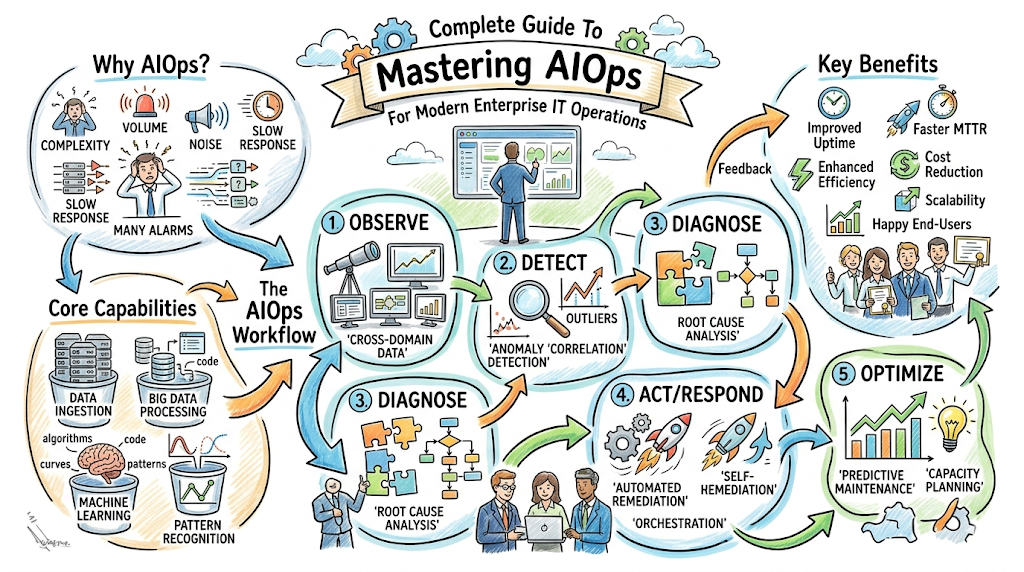
Introduction
Modern IT operations often struggle under the weight of excessive alerts and fragmented data, making it nearly impossible for teams to maintain stability manually. AIOps solves this by integrating artificial intelligence into the infrastructure, allowing systems to automatically filter noise and predict potential failures before they occur. By adopting these intelligent methodologies—which you can explore in detail through the resources at TheAIOps—organizations move away from reactive firefighting toward a more resilient, automated approach that ensures consistent service delivery in complex environments.
The Origin of IT Operations Challenges
Early Infrastructure Monitoring Limitations
In the early days, infrastructure was predictable. You had physical servers, a defined network, and static applications. Monitoring meant setting a simple threshold—if CPU usage hit 90 percent, send an email. This worked when infrastructure was small.
As systems grew, this approach failed. Networks became distributed, and applications moved into complex microservices. Static thresholds triggered thousands of false alarms, leading to what engineers call alert fatigue. Monitoring became a guessing game.
Transition from Manual Operations to Intelligent Automation
Operations teams realized they were drowning in data. The solution was not more people; it was better processing. The industry shifted toward automated systems that could filter out the noise.
Engineers began building pipelines that could ingest data from multiple sources and group related events. This was the birth of intelligent automation. Instead of responding to individual alerts, teams started managing patterns and incident clusters.
Enterprise Adoption Across Cloud and Hybrid Environments
Modern enterprises operate across multi-cloud environments. Keeping track of containers, serverless functions, and legacy databases manually is impossible. AIOps became a necessity for scalability.
Large organizations adopted these tools to maintain uptime requirements. By shifting to intelligent operations, they could manage global footprints with smaller, more efficient teams. This shift moved the focus from fixing problems to maintaining system health.
Defining Modern AIOps Architecture
The Core Components of AIOps Platforms
An AIOps platform relies on three main stages: ingestion, processing, and action. Telemetry pipelines collect logs and metrics from your entire stack. The processing engine uses machine learning to identify normal behavior versus anomalies.
Finally, the action layer triggers automated workflows. These systems work together to provide a single view of system health. It turns raw, disconnected data into a clean, prioritized list of tasks for engineers.
Daily Responsibilities of AIOps Engineers
An operations engineer working with AIOps spends time configuring data pipelines and training machine learning models. They identify which metrics are critical for business performance.
They also design automated remediation scripts. When the system detects a common failure, the engineer ensures that the script handles it without human intervention. The goal is to design a system that manages itself as much as possible.
Event Correlation vs. Root Cause Analysis
Correlation is about grouping related alerts together. If your database, web server, and load balancer all report errors at the same time, correlation groups them into one incident.
Root Cause Analysis, or RCA, takes it a step further. It identifies the actual culprit, such as a faulty configuration update, within that group. It saves hours of digging through logs, directing engineers straight to the fix.
The Predictive Operations Mindset
Predictive operations mean looking at data before a crash happens. By analyzing trends in disk space or memory usage, the system forecasts failures.
This culture changes how a team functions. Instead of being reactive, you become proactive. You resolve resource exhaustion or performance degradation during off-hours, ensuring the system remains stable for your users.
The 7 Core Principles of Introduction to AIOps and Its Impact on Modern IT
1. Intelligent Event Correlation
The system takes thousands of noisy signals and clusters them into distinct, manageable incidents. This prevents the “alert storm” that often cripples response teams.
2. Predictive Analytics and Anomaly Detection
Machine learning models learn what “normal” looks like for your specific application. When performance drifts, the system highlights the anomaly, even if it hasn’t crossed a hard threshold yet.
3. Automation of Repetitive IT Tasks
Many operational tasks are manual, such as restarting services or clearing caches. Automation platforms perform these actions automatically based on predefined logic.
4. Unified Observability Across Systems
Observability is more than monitoring. It involves having visibility across logs, traces, and metrics in one place. AIOps platforms act as the centralized brain for this data.
5. AI-Driven Incident Response
When an incident occurs, the system can automatically notify the right person, provide the relevant log context, and even suggest a fix. This reduces the time to resolution significantly.
6. Continuous Learning and Optimization
These systems improve with feedback. Every time a team resolves an issue, the machine learning model gets smarter, making future predictions more accurate.
7. Scalable Cloud-Native Operations
Managing Kubernetes clusters requires dynamic intelligence. These tools are built to handle the ephemeral nature of containers, tracking service health as pods spin up and down.
Key Operational Concepts You Must Know
AI vs. ML vs. AIOps — Explained Simply
- AI is the broad concept of machines performing tasks that usually require human intelligence.
- ML is a subset of AI where machines learn from data to make predictions or decisions.
- AIOps is the specific application of AI and ML to solve IT operational challenges.
Event Correlation — The Backbone of Modern AIOps
In simple terms, correlation is the act of connecting the dots. If you have five different alerts, correlation tells you they all belong to the same server crash. It prevents teams from chasing ghosts.
Alert Fatigue — The Silent Productivity Killer
Alert fatigue happens when engineers get so many notifications they start ignoring them. This leads to burnout and, eventually, missed critical issues. AIOps solves this by prioritizing only the noise that matters.
Incident Management & Automated RCA
When a service goes down, time is money. Automated RCA maps the dependencies of your services. It tells you that the web server is failing because the underlying database connection pool is full.
Capacity Forecasting
Instead of guessing when to add more servers, predictive algorithms analyze growth trends. They tell you exactly when you will run out of resources, allowing for graceful scaling.
The Four Pillars of Intelligent Observability
- Logs: The historical record of events.
- Metrics: Numeric data representing health over time.
- Traces: Information on how requests move through services.
- Events: Specific incidents that change state.
Traditional IT Operations vs. AIOps — What’s the Real Difference?
The Philosophy Difference
Traditional operations are reactive. You wait for an alert, investigate, and then fix. AIOps is proactive. You anticipate issues and resolve them before they impact the end user.
Roles & Responsibilities Compared
- Traditional: Manual troubleshooting, reading logs, ticket creation, reactive firefighting.
- AIOps: Managing data pipelines, building automation workflows, refining ML models, architecture design.
Can Traditional Monitoring and AIOps Work Together?
Absolutely. AIOps actually needs the data from your traditional monitoring tools to function. Think of your old monitoring tools as the eyes, and your AIOps platform as the brain.
Which Operational Model Should Organizations Adopt?
Small teams with simple stacks might handle manual operations fine. However, any enterprise managing complex cloud services should move toward an intelligent model to maintain competitive speeds.
Real-World Use Cases of Modern AIOps
Predictive Incident Detection in Enterprises
Retail platforms use AIOps to detect anomalies during sales events. If checkout speed drops even slightly, the system flags it before customers start abandoning carts.
AI-Powered Root Cause Analysis
In banking, complex transaction chains are hard to track. AIOps maps these dependencies, pinpointing whether a delay originates in the payment gateway or the internal ledger.
Managing Reliability Across Multi-Cloud Environments
Operations teams use centralized intelligence to gain a single pane of glass view, whether their services run on AWS, Azure, or local private clouds.
AIOps in Financial and Banking Platforms
Reliability in finance is non-negotiable. Using intelligent automation, these institutions can perform self-healing actions, ensuring zero-downtime during peak traffic.
Lightweight AIOps Strategies for Startups
Startups often start with basic log aggregation and alerting. By building these with an automation-first mindset, they avoid technical debt as they scale into larger enterprises.
Common Mistakes in AIOps Implementation
Mistake 1 — Treating AIOps as Just Another Monitoring Tool
Many companies buy the software and expect magic. AIOps is a cultural shift. You must change how your team works, not just what tools they open.
Mistake 2 — Ignoring Data Quality Issues
If your logs are messy or your metrics are inconsistent, the AI will provide poor insights. You must clean your data before relying on automated analysis.
Mistake 3 — Automating Broken Processes
If your manual process for fixing a server is flawed, automating it only makes the mistakes happen faster. Fix the workflow first, then automate.
Mistake 4 — Overlooking Human Collaboration
AI is there to help, not replace. Teams need to stay involved, reviewing the AI’s suggestions and ensuring the automated actions align with business goals.
Mistake 5 — Excessive Alert Configuration
Setting too many alerts is just as bad as setting none. Start with the most critical business services and expand your coverage as the team becomes comfortable.
Mistake 6 — Delaying AI Adoption in Cloud-Native Infrastructure
The longer you wait to adopt intelligent operations, the harder it becomes to manage your infrastructure as it grows. Start small, but start early.
Essential AIOps Tools & Technologies
Monitoring & Observability Platforms
Tools that aggregate telemetry data from your servers, networks, and cloud instances.
Incident Management Solutions
Systems that route alerts to the right teams and manage the lifecycle of an outage from start to finish.
Automation & Orchestration Platforms
Platforms that execute scripts or playbooks to restore service health without manual intervention.
Machine Learning & Analytics Engines
The core logic that processes the data and identifies patterns, anomalies, and potential issues.
Cloud & Kubernetes Monitoring
Specialized tooling designed to watch the health of containers, pods, and the underlying orchestrator.
Becoming an AIOps Professional — Career Roadmap
Essential Skills Every AIOps Engineer Needs
- Strong Linux system administration knowledge.
- Proficiency in scripting (Python or Go).
- Understanding of cloud architecture (AWS, Azure, GCP).
- Deep experience with observability tools and log management.
- Basic understanding of how machine learning models work.
Step-by-Step Professional Learning Path
- Master fundamental monitoring and Linux basics.
- Learn how to script and automate common tasks.
- Gain deep exposure to cloud-native technologies like Kubernetes.
- Study data analysis and how to work with large telemetry sets.
- Focus on the architectural side of incident management.
Certifications Worth Pursuing
Focus on certifications related to cloud infrastructure, specific observability platforms, and general DevOps practices. These demonstrate a foundational ability to handle complex systems.
Educational Resources with [TheAIOps]
TheAIOps provides targeted learning paths and certification guides designed to move you from a standard operator to an intelligent operations engineer. Explore their modules to sharpen your skills.
The Future of Intelligent IT Operations
AI-Driven Autonomous Infrastructure
We are moving toward systems that can fix themselves entirely. The goal is an environment where the infrastructure detects, diagnoses, and repairs its own bugs without any human contact.
Platform Engineering and Self-Service Operations
Operations teams are increasingly building internal portals. This allows developers to handle their own deployments and troubleshooting, guided by the guardrails built into the platform.
AIOps in Kubernetes and Cloud-Native Ecosystems
As organizations go deeper into cloud-native architectures, AIOps will become the only way to manage the sheer volume of telemetry generated by thousands of microservices.
Emerging Skills That Will Define Future Operations Teams
Future engineers will need to understand FinOps to manage costs, alongside traditional reliability and AI skills. Being able to explain the “why” behind an automated action will be a key differentiator.
FAQ Section
- What is the biggest challenge for beginners in this field?
The biggest hurdle is learning to manage the sheer volume of data. Beginners often feel overwhelmed by the number of tools and the complexity of cloud logs, but mastering one domain at a time makes the journey manageable. - How do I start building a career in this sector?
Start by solidifying your knowledge of infrastructure and automation. Once you understand how to manage systems manually, explore how to use code to automate those processes and leverage analytics to improve efficiency. - Is programming required for an operations role?
Yes, scripting is essential. You need to be able to write small programs in languages like Python to automate manual tasks and interact with the APIs provided by monitoring and automation platforms. - Are these certifications valuable for job hunters?
Certifications act as a stamp of credibility. They show employers that you have invested time in learning industry-standard practices, which is particularly useful when you are entering the operations field for the first time. - Does this career path offer good salary potential?
Engineers who can bridge the gap between AI and IT operations are in high demand. Because they directly influence system reliability and business uptime, these roles are among the most highly compensated in the IT industry. - How do I keep my skills relevant as the industry changes?
Technology moves fast, so focus on the fundamentals of architecture and data processing rather than just learning specific software. Concepts like observability and automation remain relevant regardless of which tool is currently trending.
Conclusion
Modern IT operations require more than just manual effort. To maintain reliability in complex environments, you must embrace intelligent data processing and automated remediation. AIOps provides the architecture and principles needed to transform from a reactive team into a proactive, resilient organization.
By focusing on intelligent event correlation, anomaly detection, and continuous learning, you can reduce alert fatigue and improve your system’s uptime. Start your journey into intelligent operations today and build a future-proof career with TheAIOps.