Upgrade & Secure Your Future with DevOps, SRE, DevSecOps, MLOps!
We spend hours scrolling social media and waste money on things we forget, but won’t spend 30 minutes a day earning certifications that can change our lives.
Master in DevOps, SRE, DevSecOps & MLOps by DevOps School!
Learn from Guru Rajesh Kumar and double your salary in just one year.
Introduction
Modern enterprise IT environments have grown incredibly complex. With the shift to hybrid clouds, microservices, and distributed architectures, infrastructure teams are overwhelmed by data. Traditional monitoring tools often fail to keep up, leading to severe alert fatigue and missed incidents. This is where intelligent IT operations platforms come into play.
By leveraging machine learning and big data, these systems transform raw telemetry into actionable insights. Organizations are rapidly adopting these solutions to cut through the noise and maintain system uptime. For those exploring the landscape, resources like TheAIOps provide crucial insights into how these technologies function. Understanding the nuances of these tools is the first step toward building a resilient, automated operational strategy.
What Are AIOps Platforms?
AIOps platforms—Artificial Intelligence for IT Operations—are software systems that combine big data and machine learning to automate IT operations processes. They ingest data from diverse sources like logs, metrics, traces, and events to identify patterns.
Unlike traditional monitoring that relies on static thresholds, AIOps platforms continuously learn the baseline behavior of your applications. They bridge the gap between massive data streams and human-readable insights. Enterprises adopt them to transition from reactive troubleshooting to proactive management.
Why AIOps Platforms Matter in Modern Enterprises
As systems scale, manual oversight becomes impossible. AIOps platforms matter because they offer:
- Faster Incident Detection: AI algorithms identify anomalies in real-time, often before users notice issues.
- Intelligent Alert Management: Systems aggregate hundreds of alerts into a single incident, drastically reducing noise.
- Predictive Analytics: By identifying trends, these tools help teams address capacity issues or potential failures before they escalate.
- Automation: They trigger self-healing workflows, such as restarting services or clearing caches, without human intervention.
Core Features of Modern AIOps Platforms
Event Correlation
Platforms analyze disparate events across the stack and group them if they originate from the same root cause. This prevents engineers from having to investigate individual symptoms that are actually part of one larger outage.
Anomaly Detection
Machine learning models observe normal performance patterns and instantly flag deviations, even if they stay within traditional “safe” thresholds. This is vital for catching subtle memory leaks or slow degradation.
Root Cause Analysis
These tools trace the sequence of events leading to a failure, allowing engineers to pinpoint the exact service or configuration that caused the outage. It reduces the time spent on manual investigation.
Predictive Monitoring
By analyzing historical data, platforms forecast future performance bottlenecks, enabling proactive infrastructure scaling. For example, predicting a storage capacity breach before it happens during a holiday sale.
Automation Workflows
When a specific anomaly is detected, the platform triggers a predefined runbook or script to resolve the issue automatically. This significantly reduces manual labor and downtime.
Incident Intelligence
Platforms enrich incidents with context, such as service ownership, recent code changes, and infrastructure topology, ensuring the right person is alerted with the right information.
Observability Dashboards
They provide a unified “single pane of glass” view, combining logs, metrics, and traces into dashboards that are readable for both technical and business stakeholders.
AI-driven Alert Prioritization
Rather than treating all alerts as equal, the system ranks them based on business impact. Critical failures of a user-facing checkout service are prioritized over a background logging service warning.
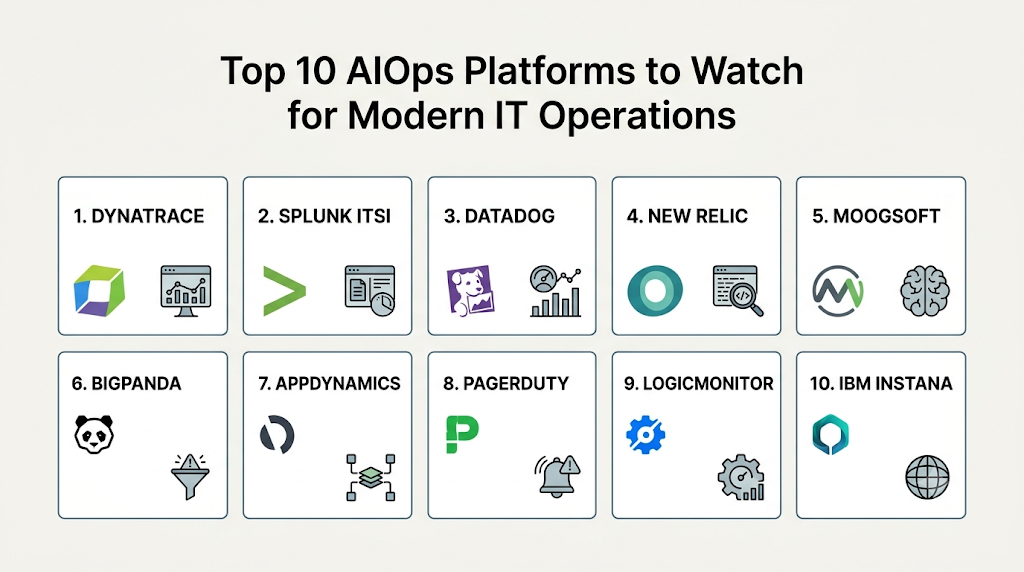
Top 10 AIOps Platforms to Watch
1. Dynatrace
A powerhouse in full-stack observability. It excels at automatic discovery and AI-driven root cause analysis, making it ideal for large-scale cloud environments.
2. Splunk ITSI
Deeply integrated with log analytics, it is perfect for enterprises that need to correlate operational data with security and business metrics.
3. Datadog
Highly popular for DevOps teams. It offers seamless integration across cloud-native platforms, providing a unified view of metrics, traces, and logs.
4. New Relic
Strong on application performance monitoring (APM). Its platform is highly flexible, serving well-suited for developers who need deep code-level insights.
5. Moogsoft
Specializes in noise reduction. It is a go-to solution for large enterprises struggling with massive volumes of fragmented monitoring data.
6. BigPanda
Focuses heavily on event correlation and automation. It excels at integrating with legacy monitoring stacks to provide a modern “single pane of glass.”
7. AppDynamics
Excellent for business-transaction-centric monitoring. It helps organizations understand how IT performance directly impacts user experience and revenue.
8. PagerDuty
While known for incident response, its AIOps capabilities in intelligent alert grouping and workflow automation are industry-leading for SRE teams.
9. LogicMonitor
A cloud-based SaaS platform that shines in hybrid infrastructure monitoring. It is generally easier to deploy for teams needing quick visibility.
10. IBM Instana
Provides automated, real-time observability. Its strength lies in its ability to discover and map complex, dynamic microservices architectures automatically.
AIOps Workflow Explained
The workflow typically follows a clear path:
- Data Collection: Gathering telemetry from logs, metrics, and network devices.
- Aggregation: Normalizing diverse data into a unified, clean dataset.
- Pattern Recognition: AI detects relationships between events across the infrastructure.
- Prioritization: Ranking issues based on business impact.
- Remediation: Automating the fix or routing to the correct human responder.
AIOps Architecture & Observability
AIOps architectures generally consist of three main layers:
- Ingestion Layer: Connectors to various tools, cloud APIs, and application logs.
- Analytics Layer: Where the “Brain” resides, utilizing ML for anomaly detection and pattern matching.
- Automation Layer: Interfaces with infrastructure APIs to execute remediations (e.g., Kubernetes scaling, VM reboots).
Roles and Responsibilities in AIOps Platforms
- AIOps Engineer: Focuses on configuring AI models, fine-tuning thresholds, and managing the health of the monitoring platform.
- Observability Engineer: Manages the instrumentation and pipelines that provide the raw data.
- SRE: Uses the insights from the platform to improve system reliability and automate manual “toil.”
Beginner Roadmap for Learning AIOps Platforms
- Foundations: Master Linux, basic networking, and cloud fundamentals (AWS/Azure).
- Monitoring Basics: Understand how traditional metrics are collected (Prometheus, Zabbix).
- Observability: Learn the differences between logs, metrics, and distributed traces.
- Automation: Become proficient in Python or Bash for basic scripting.
- AIOps Specialization: Pick a platform (e.g., Datadog or Dynatrace) and follow their guided training paths.
Certifications & Learning Resources
Certifications validate your ability to manage complex platforms. Platforms like Dynatrace or Datadog offer robust training portals, while general concepts are well-covered at TheAIOps.
| Certification | Level | Best For | Skills Covered |
| Associate Observability | Beginner | Students | Basics of Logs/Metrics |
| Platform Specialist | Intermediate | Engineers | Tool Configuration |
| AIOps Architect | Advanced | Strategists | System Integration |
Real-World Use Cases of AIOps Platforms
- Enterprise IT: Consolidating monitoring for on-premises and hybrid cloud.
- SaaS Companies: Detecting performance drops that impact customer subscription retention.
- Banking: Monitoring transactional integrity and detecting fraud patterns via network anomalies.
- E-commerce: Preventing revenue loss by auto-scaling infrastructure during flash sales.
Benefits of AIOps Platforms
- Faster Resolution: Compressed incident timelines via automated root cause detection.
- Visibility: A holistic view of the entire technical stack.
- Efficiency: Automating repetitive manual tasks frees up engineers for innovation.
- Predictive Power: Addressing potential issues before they become outages.
Common Challenges in AIOps Platform Adoption
- Data Silos: Different departments using different tools. Solution: Centralize data into a unified lake.
- Data Quality: “Garbage in, garbage out.” Solution: Clean and normalize data sources first.
- Skill Gaps: Lack of staff trained in ML-based tools. Solution: Invest in structured training programs.
- Integration: Difficulty connecting to legacy hardware. Solution: Use modern API gateways.
Common Beginner Mistakes
- Learning too many tools: Pick one and learn it deeply.
- Ignoring fundamentals: Don’t skip learning networking or basic Linux commands.
- Over-reliance on automation: Always keep human oversight as a safety guardrail.
- Skipping documentation: If you don’t document your monitoring rules, you won’t know why they trigger later.
Best Practices for Using AIOps Platforms
- Centralize Observability: Bring all teams to a single data platform.
- Reduce Noise: Ruthlessly tune your alerts so only actionable ones reach human eyes.
- Continuous Optimization: Regularly review your ML thresholds as your infrastructure evolves.
- Actionable Documentation: Keep your runbooks updated to match your automated workflows.
Future of AIOps Platforms
The future is “Self-Healing IT.” We are moving toward systems that not only detect an issue but resolve it autonomously, requiring human intervention only for architectural changes or major updates. Autonomous defense and intelligent capacity management are the next frontiers.
FAQs
1. What are AIOps platforms in simple words?
At their core, AIOps platforms are intelligent software layers that sit on top of your existing monitoring tools to act as a “brain” for your IT infrastructure. Instead of just showing you raw data, they ingest massive volumes of information from logs, metrics, and network traffic, using machine learning to filter out the noise.
2. How do AIOps platforms reduce alert fatigue?
These platforms combat alert fatigue primarily through deduplication, aggregation, and correlation. In a traditional setup, a single server failure might trigger hundreds of individual alerts, leaving engineers overwhelmed and struggling to find the real issue. AIOps platforms recognize that these diverse signals belong to the same underlying event and bundle them into a single, high-priority incident.
3. Which AIOps platform is best for enterprises?
There is no universal “best” choice because the ideal platform depends heavily on your existing technology stack and specific operational needs. For organizations focused on full-stack observability, tools like Dynatrace and Datadog are often considered top-tier. Those deeply integrated into log-heavy environments might find Splunk ITSI to be more effective, while enterprises struggling specifically with massive volumes of fragmented data often turn to Moogsoft or BigPanda for their noise reduction capabilities.
4. Is AIOps difficult to learn?
For professionals with a background in system administration, DevOps, or Site Reliability Engineering, AIOps is a logical and manageable evolution of existing skills. While the internal machine learning and data processing models are complex, modern vendors have designed their platforms with intuitive, user-friendly interfaces.
5. What skills are required for AIOps careers?
To build a successful career in this field, you should cultivate a blend of three main areas: operational fundamentals, data literacy, and automation. You must be comfortable with Linux, networking, and cloud architecture (AWS, Azure, or GCP), while also understanding how to query and interpret logs, metrics, and traces. Furthermore, proficiency in scripting languages like Python or Bash is essential for building automated remediation workflows.
6. Are AIOps platforms useful for cloud-native/hybrid environments?
They are not just useful; they are essentially a requirement for modern infrastructure. In dynamic, microservices-based environments, traditional static monitoring tools fail because components change or scale too rapidly to track manually. AIOps platforms automatically discover new services and adjust their performance baselines in real-time.
7. What is the role of observability in AIOps?
Observability acts as the critical data foundation upon which AIOps operates. While traditional monitoring simply asks whether a system is up or down, observability provides the context by asking why the system is behaving a certain way.
8. Can a beginner learn enterprise monitoring tools?
Absolutely, and the barrier to entry is lower than ever before. Most leading platforms now offer “Sandbox” or “Developer” editions that allow individuals to practice using their tools without the cost of a full enterprise license. A beginner should start by deploying a simple monitoring agent on a personal virtual machine or a containerized environment.
9. Is AIOps a replacement for human DevOps or SRE teams?
It is important to emphasize that AIOps is an augmentative technology, not a replacement for human intellect. The platform handles the repetitive heavy lifting of data analysis, pattern recognition, and routine task automation, which significantly reduces the daily “toil” faced by IT teams. By removing these manual burdens, AIOps actually empowers engineers to focus on high-value work, such as designing better system architectures, improving security posture, and planning long-term infrastructure strategy. Ultimately, these platforms are tools designed to support and enhance human expertise.
10. What are the common challenges in AIOps adoption?
The most frequent hurdles during adoption are cultural and data-driven rather than purely technical. A common issue is the “garbage in, garbage out” problem, where poor-quality or messy logs lead to inaccurate AI insights, necessitating an upfront investment in data hygiene. Furthermore, teams may initially be skeptical of “black-box” decisions made by AI, and large organizations often suffer from data silos where departments refuse to share telemetry.
Conclusion
Implementing AIOps is not merely a technical upgrade; it is a fundamental shift toward building a resilient, self-optimizing IT environment. While the transition from manual, reactive firefighting to intelligent, automated operations may seem daunting, the benefits—such as drastically reduced alert fatigue, significantly lower MTTR, and the ability to proactively prevent downtime—far outweigh the initial learning curve. Remember, AIOps is not about replacing human expertise with machines; it is about augmenting your team’s capabilities so you can focus on innovation rather than repetitive manual toil. The most successful organizations start small, prioritize data quality, and build trust in AI-driven insights through targeted, measurable pilot projects. By fostering a culture of continuous learning and data-driven decision-making, you position your team to handle the growing complexities of modern cloud-native and hybrid architectures with confidence.