Upgrade & Secure Your Future with DevOps, SRE, DevSecOps, MLOps!
We spend hours scrolling social media and waste money on things we forget, but won’t spend 30 minutes a day earning certifications that can change our lives.
Master in DevOps, SRE, DevSecOps & MLOps by DevOps School!
Learn from Guru Rajesh Kumar and double your salary in just one year.
Introduction
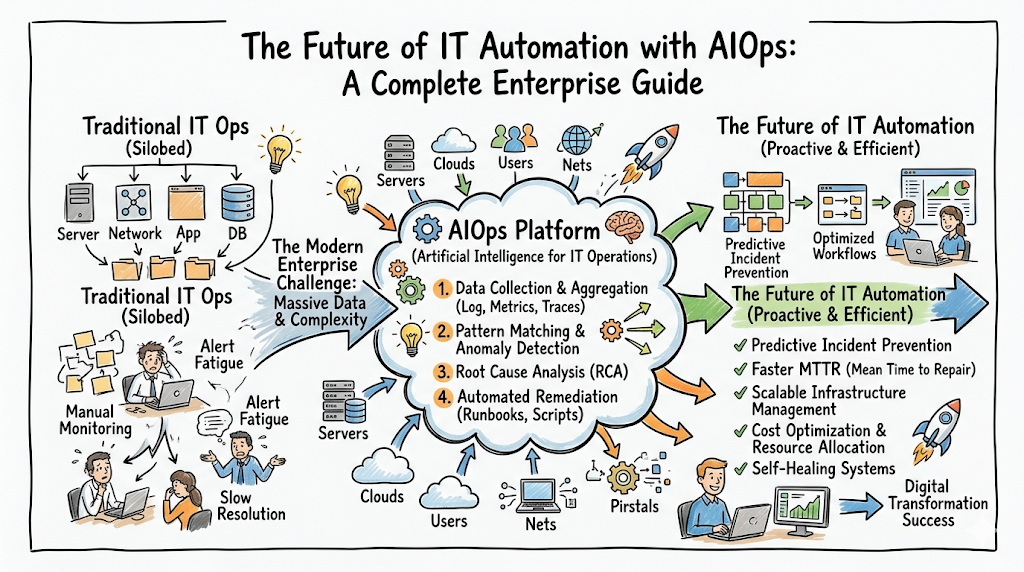
Modern enterprise technology environments have grown too massive and fast for traditional human management. A typical cloud-native infrastructure generates billions of data points daily across containers, microservices, hybrid clouds, and third-party APIs. In this hyper-complex landscape, traditional IT automation—which relies on static, human-written scripts to handle predictable tasks—is no longer enough. When an unexpected multi-service failure occurs, static scripts cannot determine why the system is failing or how to fix it. This operational bottleneck is exactly why global enterprises are rapidly shifting toward Artificial Intelligence for IT Operations, commonly known as AIOps..
For beginners, cloud engineers, and DevOps professionals, understanding this shift is the most valuable career move available today. The industry is moving away from basic infrastructure monitoring and toward comprehensive observability and autonomous operations. Learning how to manage, configure, and engineer these intelligent systems ensures you remain highly relevant in an automated market. To stay ahead of these industry shifts and access deep-dive engineering resources, professionals rely on educational platforms like TheAIOps, which provides comprehensive documentation and strategic insights into modern operational methodologies.
What Is AIOps in Modern IT Automation?
To understand the future of IT automation with AIOps, it helps to look at how infrastructure management has evolved over the decades.
[Phase 1: Manual Operations] ──> [Phase 2: Scripted Automation] ──> [Phase 3: AI-Driven AIOps]
- Runbooks & Checklists - Cron jobs & Bash scripts - Machine Learning models
- Human-driven triage - Hardcoded static thresholds - Automated remediation
- Slow & error-prone - Breaked by unexpected changes - Self-healing systems
Originally, operations teams relied on manual checklists and reactive runbooks. When a server ran out of disk space, an engineer logged in and cleared the cache files by hand.
Then came scripted automation. Engineers wrote Bash, Python, or Ansible scripts to handle these repetitive tasks. If a monitoring tool detected that disk utilization crossed a static threshold of 85%, it triggered a script to delete temporary files. While this was a major step forward, scripted automation is inherently rigid. It only knows how to handle scenarios that a human developer explicitly programmed. If disk space fills up because an application is stuck in an infinite print loop rather than accumulating normal log files, the static script fails, and human intervention is required once again.
AIOps bridges this gap by infusing machine learning into the automation cycle. Instead of relying on rigid, hardcoded rules, AIOps platforms ingest massive streams of numbers, logs, and traces from the entire technology stack. The platform establishes a dynamic baseline of what normal system behavior looks like. It understands that 90% CPU usage at 9:00 AM on a Friday might be perfectly normal due to weekly batch processing, while 90% CPU usage at 2:00 AM on a Sunday is an anomaly that requires attention.
This creates a foundational relationship between three core concepts:
- Observability: The practice of collecting and analyzing metrics, logs, and traces to understand the internal state of a system based on its external outputs.
- AIOps: The intelligence layer that analyzes this vast ocean of observability data to find patterns, detect anomalies, and correlate separate events.
- Automation: The execution layer that takes action based on the insights provided by the AIOps engine, such as restarting a service or provisioning extra compute capacity.
The core philosophy of autonomous IT management is to build systems that can see, think, and heal themselves. Rather than treating automation as a collection of disconnected tasks, modern enterprises treat it as a continuous, intelligent loop that keeps application environments stable, cost-effective, and fast without requiring constant human oversight.
Why AIOps Matters in the Future of IT Operations
The business and technical impacts of combining artificial intelligence with operational workflows are immense. As organizations scale up their cloud footprints, relying on legacy monitoring approaches leads to operational friction, engineering burnout, and lost revenue.
Faster Incident Response and Reduced Downtime
When a major enterprise application goes down, every minute costs money. In traditional environments, finding the root cause of an outage takes hours because engineers from different teams—databases, networks, applications, and security—must get on a triage call to review their respective logs. An AIOps platform analyzes data from all these layers simultaneously. It can pinpoint the exact microservice that caused a cascading failure across the cluster within seconds, dropping the Mean Time to Resolution (MTTR) from hours to minutes.
Intelligent Alert Management and Reduced Alert Fatigue
On-call engineers are frequently overwhelmed by thousands of low-priority monitoring alerts every day, a problem known as alert fatigue. When a core network switch drops momentarily, it can trigger secondary alerts across hundreds of connected virtual machines and applications, creating an intimidating wall of notifications. AIOps solves this by using event correlation. It groups those hundreds of individual alerts into a single, comprehensive operational incident, letting engineers focus on fixing the root cause rather than triaging repetitive notifications.
Predictive Monitoring and Automated Remediation
Traditional monitoring tools only tell you when a system has already broken. AIOps shifts the paradigm from reactive firefighting to predictive prevention. By analyzing multi-variable trends, machine learning algorithms can predict that a memory leak in a specific application container will cause a system crash within the next two hours. The platform can then automatically trigger a workflow to spin up a fresh instance of the container and gracefully terminate the degraded one before users ever notice a slowdown.
Core Concepts of AIOps Automation
Event Correlation
Event correlation is the process of taking thousands of individual, unstructured log messages and operational alerts from across an enterprise infrastructure and linking them together based on time, topology, and behavior. Instead of presenting an engineer with a chaotic list of isolated errors, the AI engine recognizes that a database latency alert, a web server error, and a user login failure are all part of the exact same underlying infrastructure issue.
Predictive Analytics
Predictive analytics uses historical performance data to forecast future system behavior. By applying time-series analysis and regression algorithms, the system maps out resource usage patterns. For example, it can look at seasonal traffic patterns over the past six months to accurately forecast exactly when an e-commerce platform will require additional cloud storage ahead of a major shopping event, preventing capacity-related outages entirely.
Anomaly Detection
Unlike static thresholds that trigger an alert whenever a metric crosses a fixed number, anomaly detection uses algorithmic baselines. It analyzes current metrics against historical patterns to identify true deviations from normal behavior. If an internal microservice suddenly experiences a minor drop in traffic that remains well within “normal” absolute parameters but is highly unusual for that specific hour of the day, the anomaly detection engine flags it immediately as a potential hidden issue.
Observability
Observability goes deeper than basic uptime monitoring by analyzing the detailed internal health of an application. It relies on the three pillars of operational data: Metrics (numerical data points over time), Logs (text records of discrete system events), and Traces (the complete end-to-end journey of a user request through various microservices). AIOps acts as the brain that makes sense of these three data streams at scale.
Automated Remediation
Automated remediation is the action arm of intelligent operations. Once the AI engine identifies an issue and confirms the root cause, it triggers predefined code workflows to resolve the problem without human intervention. This includes actions like expanding disk partitions, clearing stale application caches, renewing expired SSL certificates, or isolating compromised network ports.
Root Cause Analysis
When complex systems fail, the apparent symptom is rarely the actual source of the problem. Root cause analysis uses topology mapping and dependency graphs to trace a failure back to its origin. If a frontend website starts throwing 500 internal server errors, the system traces the dependencies back through the backend APIs to find that the true root cause was a locked table in a backend database cluster.
Self-Healing Infrastructure
Self-healing infrastructure is an operational state where code-driven systems detect, diagnose, and fix their own internal faults. By integrating configuration management tools with AIOps decision engines, infrastructure automatically realigns itself to a healthy state whenever it drifts, minimizing the need for manual system administration.
Intelligent Alerting
Intelligent alerting ensures that notifications are sent only when real, actionable problems occur. The platform filters out transient data spikes—like a momentary CPU jump that lasts for three seconds and resolves itself—and routes high-priority incidents directly to the specific team responsible for that exact layer of the infrastructure stack.
Workflow Automation
Workflow automation connects disparate IT systems together into unified operational paths. When an incident is detected, the workflow engine automatically opens a ticket in an IT service management platform, attaches the relevant logs and diagnostic data, notifies the on-call engineer via communication channels, and logs the eventual resolution for compliance audits.
Autonomous Operations
Autonomous operations represent the highest maturity tier of IT management. In this phase, the technology infrastructure requires minimal human supervision for day-to-day operations. The system continually optimizes its own performance, adjusts its cloud resource allocation based on real-time financial costs, and updates its defense posture against security anomalies entirely on its own.
AIOps Automation Architecture & Workflow
An effective AIOps deployment relies on a structured, multi-layered architecture designed to turn messy system data into automated operational actions. The workflow flows sequentially through several core layers:
[ Data Ingestion Layer ] ──> [ AI/ML Analytics Engine ] ──> [ Action & Remediation ]
- Metrics, Logs, Traces - Anomaly Detection - Scripted Workflows
- Network Packets, API Data - Event Correlation - Self-Healing Actions
- Configuration Topologies - Root Cause Analysis - ITSM Ticket Automation
1. Data Ingestion Layer
The foundation of the architecture is continuous data collection. This layer gathers information from every corner of the enterprise environment using lightweight software agents, API endpoints, and streaming network protocols. It ingests:
- Structured Data: Performance metrics like CPU utilization, memory consumption, and network throughput bandwidth.
- Unstructured Data: Application log files, system event journals, and database transaction logs.
- Relationship Mapping: Configuration Management Databases (CMDBs) and real-time cloud topology maps that show how components connect to one another.
2. AI/ML Analytics Engine
Once data is collected, it enters the analytics engine, where noise reduction takes place. Raw data is normalized and processed using advanced algorithms. The engine filters out repetitive data points, tracks normal performance baselines, and flags statistically significant deviations. It matches anomalies across separate layers of the tech stack using time-matching algorithms to determine if two separate errors are part of a single issue.
3. Event Intelligence and Root Cause Analysis
In this phase, the system builds an operational timeline of the incident. By analyzing the system topology map, the engine understands the structural dependencies between services. It traces the flow of errors backwards across the network to identify the exact component that failed first, isolating the root cause from the subsequent wave of secondary errors.
4. Automated Remediation and Optimization
After identifying the root cause, the platform selects the appropriate response based on established policies. If a known resolution workflow exists, the system executes it automatically via automation scripts or cloud orchestrators. If the issue is entirely new, the platform aggregates all relevant diagnostic data, opens an incident ticket, alerts the on-call team, and presents them with a list of recommended fixes based on past resolutions.
AIOps Automation Lifecycle
Managing an AI-driven operations ecosystem requires a continuous loop of data collection, analysis, execution, and refinement. The following lifecycle table illustrates how data moves from raw system outputs to intelligent optimization.
| Stage | Purpose | Technologies Used | Real-World Outcome |
| Data Collection | Gather raw performance data across the hybrid environment | Prometheus agents, OpenTelemetry, Fluentd, Winlogbeat | A continuous stream of metrics, logs, and trace data ready for parsing |
| Event Aggregation | Deduplicate raw events and filter out background system noise | Kafka streams, Logstash pipelines, Vector routers | A clean, structured dataset focused purely on meaningful system changes |
| Pattern Analysis | Establish dynamic performance baselines for all infrastructure | K-means clustering, time-series regression models | The system learns to differentiate normal spikes from actual performance degradations |
| Incident Detection | Identify true system anomalies and group related issues together | Topology graphs, correlation matrices, heuristic rules | Scattered errors are combined into a single, high-priority operational incident |
| Automated Remediation | Execute code-driven workflows to resolve the identified fault | Ansible automation playbooks, Terraform, AWS Systems Manager | System failures are resolved automatically in seconds without human pages |
| Optimization | Review long-term trends to adjust resource allocations safely | Cost analysis tools, capacity forecasting algorithms | Infrastructure automatically resizes itself to match actual demand profiles |
| Continuous Improvement | Update and train AI models using feedback from human operators | Reinforcement learning models, supervised training loops | The system grows smarter over time, reducing false positives significantly |
Popular AIOps & Automation Tools
Building a modern intelligent infrastructure requires combining several distinct categories of software tools. These platforms work together to collect data, analyze performance, and execute remediation workflows.
Monitoring & Observability Platforms
These tools focus on collecting large volumes of data from systems and visualizing it. They provide the raw data feeds that AIOps engines require to make operational decisions.
Automation & Incident Management Systems
These platforms act as the execution arm, routing notifications to engineers, opening tracking tickets, and executing remediation scripts across cloud nodes.
The following matrix compares the most common platforms utilized across modern enterprise systems:
| Tool | Purpose | Difficulty | Enterprise Usage |
| Dynatrace | Full-stack observability with an integrated deterministic AI engine | Medium to High | Heavily favored by large financial institutions and complex legacy infrastructures |
| Datadog | Unified cloud-native monitoring, log tracking, and security analysis | Medium | Popular with mid-market enterprises and cloud-native SaaS platforms |
| Splunk ITSI | Large-scale log analytics and business risk correlation engine | High | Used by global enterprises managing massive volumes of multi-datacenter logs |
| Prometheus | Open-source metric collection and basic system alerting engine | Medium | The industry standard for monitoring Kubernetes environments and containers |
| PagerDuty | Incident response routing and automated team alert management | Low to Medium | Used across industries to handle engineering on-call rotations and alerting |
| Ansible | Code-driven infrastructure configuration and remediation execution | Medium | Widely deployed to automate repetitive system updates and fix procedures |
Real-World Use Cases of AIOps Automation
Cloud Infrastructure & Auto-Scaling
In large public cloud environments, resource demand changes rapidly. Traditional auto-scaling rules rely on simple thresholds, like spinning up a new virtual machine when average CPU usage hits 80%. However, by the time the new server boots up and configures itself, the application might already be crashing under the traffic spike. An AIOps platform analyzes live traffic velocity and historical trends to predict upcoming spikes 15 minutes before they happen, provisioning resources proactively so performance remains entirely stable.
Banking Systems & High-Volume Transaction Processing
Core banking applications handle millions of transactions per second. A minor slowdown in database replication can stall point-of-sale terminals and mobile banking applications globally. AIOps tools continuously audit database query health and transaction queues. If a specific database node begins to fall behind due to a storage bottleneck, the platform flags the transaction anomaly, switches traffic over to a standby node, and initiates a performance trace on the degraded system without interrupting customer transactions.
Kubernetes Environments & Microservices
Kubernetes environments are highly dynamic, with containers spinning up and shutting down constantly. This constant change makes manual troubleshooting almost impossible. If a microservice container encounters an error loop due to an unhandled code exception, an AIOps engine detects the rising error rates, correlates them with a recent code deployment, automatically triggers a rollback to the previous stable software version, and routes the bug logs directly to the development team.
Benefits of AIOps-Driven IT Automation
Implementing an intelligent, automated operations strategy provides substantial advantages for both technical engineering teams and overall business performance.
- Significant Reductions in MTTR: By automating the root cause analysis phase, operations teams can identify and fix infrastructure faults within moments of discovery.
- Elimination of Pervasive Alert Fatigue: Grouping thousands of separate alerts into unified incidents means on-call engineers receive fewer, more meaningful notifications, reducing burnout.
- Transition to Proactive Risk Management: Catching performance degradations, memory leaks, and disk space depletion early lets teams fix issues during standard working hours before they cause customer-facing outages.
- Scalable Infrastructure Operations: Instead of hiring more system administrators as cloud footprints expand, existing engineering teams can manage thousands of servers using intelligent automation systems.
- Optimized Public Cloud Spending: AIOps platforms track resource utilization patterns over time to locate over-provisioned virtual machines, automatically downsizing idle infrastructure to minimize unnecessary cloud bills.
Challenges & Limitations
While the future of IT automation with AIOps is highly promising, organizations face several practical challenges when deploying these advanced platforms.
- Data Quality and Fragmented Silos: Machine learning models require clean, complete data to function correctly. If an enterprise has fragmented monitoring tools across different business units, the AI engine cannot build an accurate map of system dependencies.
- Managing High Rates of False Positives: If an analytics engine is configured too aggressively, it may mistake normal business growth spikes for critical system anomalies, generating unhelpful alerts and draining engineering time.
- Complex System Integration: Connecting modern AIOps platforms with older legacy mainframes and custom proprietary software require extensive custom development and engineering resources.
- The Specialized Engineering Skill Shortage: Operating these advanced environments requires engineers who understand both traditional system operations and modern data science principles, a combination that is hard to find in the hiring market.
Practical Solutions for Teams
To overcome these roadblocks, organizations should avoid trying to automate everything at once. Start with an observability-first approach. Focus on consolidating your monitoring data into a single, clean platform before turning on automated remediation features.
Begin by using AI purely for data analysis and noise reduction. Let the platform group alerts and find anomalies for your team while leaving actual system fixes in human hands. Once the AI models prove their accuracy over several months, you can gradually hand over control to automated remediation scripts for simple, well-understood tasks like clearing temp files or restarting non-critical services.
Career Opportunities in AIOps & IT Automation
The industry shift toward intelligent operations has created high demand for a new class of technology professionals. Companies are looking for engineers who can design and maintain the automated systems that keep applications online.
Core Industry Roles
- AIOps Engineer: Specializes in building and managing machine learning pipelines for infrastructure data, tuning anomaly detection algorithms, and integrating data streams.
- Observability Engineer: Focuses on setting up telemetry systems across software stacks, ensuring metrics, logs, and traces are collected reliably.
- Site Reliability Engineer (SRE): Uses software engineering principles to solve operational problems, focusing on application uptime, latency, and automated system recovery.
- Automation Architect: Designs the overarching frameworks that connect monitoring insights to automated infrastructure fixes across hybrid clouds.
Required Skills and Core Proficiencies
To build a sustainable career in this space, you need a balanced foundation across multiple technology domains:
- Systems Infrastructure: Deep comfort with Linux operating systems, systems administration, and core networking concepts.
- Programming: Proficiency in scripting languages, particularly Python or Go, to build custom data integrations and automation workflows.
- Cloud & Container Infrastructure: Hands-on experience with cloud platforms like AWS, Azure, or GCP alongside container platforms like Docker and Kubernetes.
- Data Management: A solid understanding of data pipelining, log routing, and time-series databases.
Beginner Roadmap for Learning AIOps Automation
If you are starting from scratch, breaking into the intelligent IT operations space requires a structured learning path. Do not try to learn complex machine learning algorithms first; focus instead on mastering the core system fundamentals that generate the operational data.
[Step 1: Linux & Net Fundamentals] ──> [Step 2: Core Monitoring Tools]
│
▼
[Step 4: Scripting & Automation] ──> [Step 3: Cloud & Container Ops]
│
▼
[Step 5: Observability & AIOps Platforms]
Step 1: Master Linux and Networking Fundamentals
Everything runs on Linux in the cloud. You need to understand how the operating system handles resources, processes, storage, and networking.
- What to learn: Command-line navigation, file system administration, process management, permissions, SSH, TCP/IP networking, and DNS resolution.
- Hands-on practice: Install a Linux distribution on a local virtual machine or a cheap cloud instance, and practice navigating entirely via the terminal.
Step 2: Understand Traditional Monitoring Concepts
Before you can apply artificial intelligence to system data, you must understand what that data actually represents and how traditional monitoring works.
- What to learn: System metrics (CPU, RAM, Disk, Network), log management, standard status codes, and basic alerting rules.
- Hands-on practice: Set up an open-source monitoring server to collect performance data from your local computer and configure alerts for resource spikes.
Step 3: Learn Cloud Infrastructure and Containerization
Modern AIOps platforms are built primarily to manage dynamic, cloud-native deployments that scale across container clusters.
- What to learn: Cloud concepts (compute nodes, networks, managed storage), Docker containerization, and Kubernetes cluster orchestration.
- Hands-on practice: Build a basic multi-service web application, package its components inside Docker containers, and deploy it to a local Kubernetes cluster.
Step 4: Pick Up Python Scripting and Workflow Automation
Automation requires code. You must learn how to write simple, reliable scripts that interface with software APIs to execute system actions.
- What to learn: Python programming syntax, working with data structures, interacting with REST APIs, and infrastructure configuration tools like Ansible.
- Hands-on practice: Write a short Python script that queries a web service API, checks its status, and sends a notification if the service returns an error.
Step 5: Dive Into Observability and Advanced AIOps Tools
With the system fundamentals in place, you can learn to manage full-stack observability pipelines and configure intelligent analytics tools.
- What to learn: The three pillars of telemetry data, log parsing architectures, anomaly detection configuration, and enterprise AIOps platform interfaces.
- Hands-on practice: Instrument your containerized application to output detailed telemetry data, route those metrics into a central analysis engine, and experiment with setting up baseline trends.
Certifications & Training
Validating your engineering skills through recognized training programs helps focus your learning and demonstrates your expertise to hiring teams. The following table highlights valuable paths for building your credentials in automation and observability.
| Certification | Level | Best For | Skills Covered |
| Linux Foundation Certified System Administrator (LFCS) | Beginner | Building a strong foundational knowledge of core Linux operating systems | System administration, storage management, basic terminal scripting |
| AWS Certified Cloud Practitioner / Solutions Architect | Beginner to Intermediate | Understanding public cloud environments and core infrastructure layout | Cloud design principles, managed networking, resource provisioning |
| Certified Kubernetes Administrator (CKA) | Intermediate | Mastering container operations and orchestrating applications | Cluster design, application troubleshooting, container networking |
| Datadog Certified Observability Engineer | Intermediate | Mastering modern cloud monitoring architectures and telemetry collection | Metric dashboarding, synthetic testing, log parsing, application tracing |
| Dynatrace Certified Associate | Intermediate to Advanced | Learning to operate deterministic enterprise AI engines in production | Root cause isolation, anomaly detection tuning, full-stack tracing |
Common Beginner Mistakes
- Ignoring Core Infrastructure Fundamentals: Many beginners try to use advanced AI monitoring platforms before learning how underlying servers, networks, and operating systems function. If you do not know what a TCP connection timeout means, an AI alert telling you about it will not help you fix the issue.
- Learning Specific Tools Instead of Core Concepts: Focusing entirely on learning the interface of one specific vendor tool makes your skills fragile. Focus instead on mastering underlying concepts like event correlation and telemetry collection, which apply across every software platform in the industry.
- Skipping Basic Monitoring Setup: Trying to jump straight into predictive automation and self-healing code workflows before mastering simple log collection and basic alert routing leads to unreliable, overly complex systems that are hard to troubleshoot.
- A Complete Lack of Hands-On Troubleshooting Practice: Reading manuals and watching tutorials will not make you an operations engineer. Real engineering skills are built by setting up local labs, deliberately breaking your systems, and using diagnostic data to find out why they failed.
Best Practices for AIOps Automation
To build a reliable, maintainable intelligent operations framework, keep these core engineering principles in mind:
- Adopt an Observability-First Mindset: Do not try to implement automated AI analysis until you have established clean, comprehensive data ingestion pipelines across your entire tech stack.
- Design for Modular, Controlled Automation: Build your automation workflows like building blocks. Start by creating small scripts that handle simple tasks safely, and combine them into more complex recovery workflows only after they prove stable.
- Incorporate Strict Security Practices Early: Ensure your monitoring agents and automation platforms run with the minimum system privileges necessary. Secure all telemetry data pipelines to prevent sensitive data leaks.
- Maintain Thorough Operational Documentation: Document your system architecture, data models, and automated workflows clearly. When an automated system modifies an active environment, it must log its actions completely for human audit.
- Commit to Continuous Optimization: Review your system metrics and model performance regularly. Tune your anomaly thresholds to match actual business growth patterns, keeping your alerting sharp and reducing false positives.
Future Trends in AIOps & IT Automation
As technology evolves, the future of IT automation with AIOps will become more integrated, intuitive, and capable. Several major trends are currently reshaping how enterprise infrastructure is managed:
- Integration of Generative AI and Operations: Modern platforms are blending traditional anomaly detection with generative language models. This allows operations engineers to query complex system states using natural language and receive conversational diagnostic summaries alongside suggested remediation scripts.
- The Rise of Dedicated AI Operations Copilots: Specialized assistants are becoming standard components of operational control centers. These assistants act as digital team members on triage calls, surfacing relevant historical incident records and compiling documentation in real time as an incident unfolds.
- True Evolution Toward Completely Autonomous Infrastructure: Systems are moving past simple reactive fixes and toward independent self-optimization. Future environments will continuously monitor their own application loads, cloud costs, and security risks, shifting traffic and adjusting configurations automatically to remain fast, safe, and cost-efficient without requiring manual tuning.
FAQs
1. What is AIOps automation?
AIOps automation combines big data, machine learning, and advanced analytics to automate IT operations workflows. It ingests large volumes of performance metrics, system logs, and network traces from across an enterprise environment to discover patterns, isolate anomalies, and automatically execute infrastructure fixes without requiring human manual labor.
2. How does AIOps improve IT operations?
AIOps improves operations by processing vast streams of infrastructure data faster and more accurately than human teams can. It filters out background system noise, groups separate alerts into unified incidents, reduces alert fatigue for engineers, and isolates the root causes of complex system outages automatically.
3. What is predictive monitoring?
Predictive monitoring is an operations approach that uses historical performance trends and machine learning algorithms to forecast future infrastructure health. Instead of waiting for a resource to fail, predictive systems identify early indicators—like a gradual memory leak—and alert engineers or trigger fixes hours before an actual outage occurs.
4. Can AIOps reduce downtime?
Yes, AIOps reduces system downtime by speeding up both the detection and resolution of technical faults. By analyzing data across all application layers simultaneously, it pinpoints root causes in seconds rather than hours, frequently triggering automated code scripts to resolve the issue before users experience a slowdown.
5. Which tools are used in AIOps?
An AIOps ecosystem utilizes several categories of tools. Data is collected using monitoring platforms like Prometheus, Datadog, or Dynatrace. Alerts are managed and routed using incident management tools like PagerDuty, while automated fixes are executed across systems using platforms like Ansible or cloud-native orchestrators.
6. Is coding required for AIOps?
Yes, a basic proficiency in coding is necessary for engineering roles in this field. Professionals write scripts—primarily in languages like Python or Go—to build custom data pipelines between systems, interact with infrastructure APIs, and construct automated recovery workflows.
7. Can beginners learn AIOps?
Yes, beginners can absolutely learn this discipline, provided they follow a structured roadmap. Start by mastering foundational IT concepts like Linux administration, core computer networking, and basic systems monitoring before moving on to cloud architectures, data analytics, and automated self-healing platforms.
8. What industries use AIOps automation?
AIOps automation is deployed across any sector that manages large-scale, critical digital infrastructure. Key adopters include global financial institutions, e-commerce platforms, telecommunication providers, healthcare networks, and large software-as-a-service (SaaS) companies where system downtime directly impacts revenue.
9. What is the difference between DevOps and AIOps?
DevOps is an operational philosophy focused on breaking down organizational silos between development and operations teams using continuous software delivery pipelines. AIOps is a technological approach that applies artificial intelligence and machine learning data pipelines to automate and optimize day-to-day infrastructure operations.
10. How does anomaly detection differ from static thresholds?
Static thresholds trigger an alert whenever a metric crosses a single hardcoded number, such as alerting whenever CPU usage hits 80%, regardless of context. Anomaly detection uses machine learning algorithms to establish a fluid baseline of normal behavior that accounts for time and seasonality, alerting only when data deviates from that patterns.
11. What are the three pillars of observability?
The three pillars of observability are metrics, logs, and traces. Metrics provide numerical counts of resource usage over time, logs provide text records of discrete events within systems, and traces map the continuous path of a user request as it travels through various backend microservices.
12. What is alert fatigue and how does AIOps fix it?
Alert fatigue occurs when on-call engineers are overwhelmed by hundreds of minor, low-priority monitoring notifications every day, causing them to miss critical errors. AIOps fixes this by grouping related alerts together into single incidents, filtering out background noise, and routing only actionable issues to humans.
13. What is Mean Time to Resolution (MTTR)?
Mean Time to Resolution is a metric that tracks the average time required to identify, troubleshoot, and fix a technical system failure from the moment it is discovered. AIOps aims to lower this number significantly by automating the data analysis and root cause discovery phases.
14. How does self-healing infrastructure work?
Self-healing infrastructure connects automated monitoring systems directly with code execution platforms. When the monitoring system detects a verified fault, it automatically triggers a predefined script—like restarting a frozen service or expanding an disk partition—correcting the issue without human intervention.
15. Why is data quality important for AIOps?
Machine learning models depend completely on the data they ingest. If infrastructure logs are messy, incomplete, or siloed across disconnected tools, the AIOps engine cannot build an accurate dependency graph of your environment, leading to incorrect root cause analyses and high false positive rates.
Final Thoughts
The future of IT automation with AIOps is transforming how companies build, scale, and maintain their software platforms. As cloud-native deployments grow larger and more complex, companies can no longer rely on manual operations and static scripts. The industry is moving fast toward autonomous, self-healing environments that manage, scale, and protect themselves.
For anyone pursuing a career in cloud engineering, DevOps, or system administration, learning these skills is an investment that pays off over the long term. Tools will always change and evolve, but mastering the core principles of telemetry data collection, event correlation, and automated system repair ensures your skills remain highly valuable across the industry.