Upgrade & Secure Your Future with DevOps, SRE, DevSecOps, MLOps!
We spend hours scrolling social media and waste money on things we forget, but won’t spend 30 minutes a day earning certifications that can change our lives.
Master in DevOps, SRE, DevSecOps & MLOps by DevOps School!
Learn from Guru Rajesh Kumar and double your salary in just one year.
Introduction
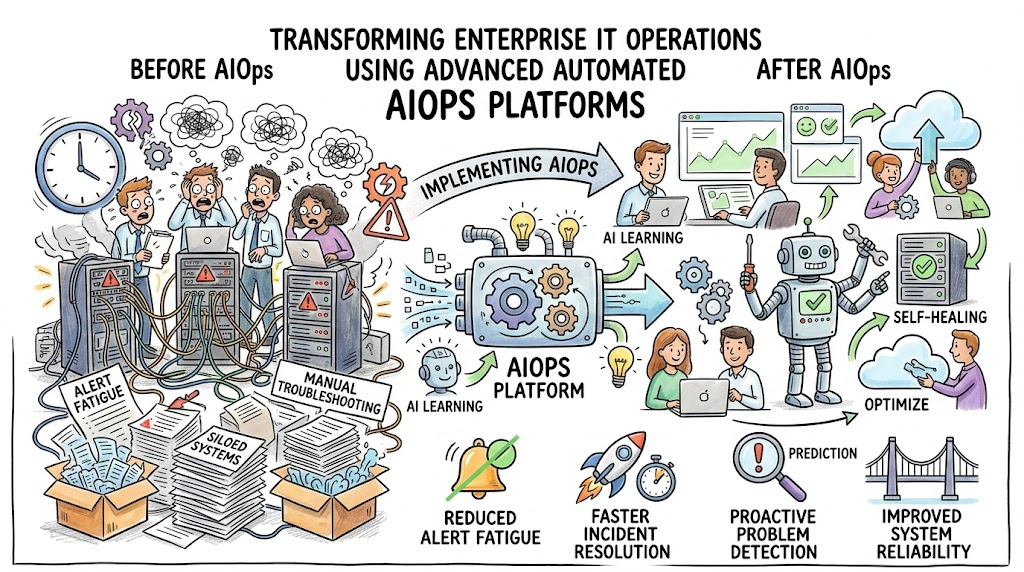
As digital landscapes expand, traditional management methods simply cannot keep pace with the sheer volume of data generated by multi-cloud environments and microservices. This is where Artificial Intelligence for IT Operations comes into play. By merging big data, machine learning, and automation, this modern approach transforms how organizations maintain their digital infrastructure. Enterprises are rapidly adopting AI-driven IT operations to transition from reactive firefighting to proactive management. Instead of waiting for a system to crash, engineering teams can now anticipate and resolve bottlenecks before they impact end users. In this comprehensive guide, you will learn the exact phases, components, and best practices required to successfully transition your infrastructure management into an intelligent, self-healing system. If you are ready to eliminate operational noise and future-proof your digital infrastructure, exploring the specialized resources at TheAIOps.com will provide the foundational insights and strategies needed to kickstart your corporate transformation journey.
Understanding AIOps in Enterprise IT
What is AIOps?
At its core, AIOps stands for Artificial Intelligence for IT Operations. It is the practice of using machine learning, natural language processing, and advanced analytics to automate the optimization of IT workflows.
Think of it as an intelligent layer that sits on top of your entire digital ecosystem. It continuously ingests logs, metrics, traces, and events to understand the baseline health of your systems, allowing humans to focus on strategic tasks rather than manual troubleshooting.
Evolution of Enterprise IT Operations
Decades ago, IT operations relied on static, siloed systems. Administrators manually checked physical servers, reviewed basic error logs, and fixed hardware failures as they occurred.
As virtualization and internet technologies advanced, monitoring tools emerged to send basic alerts when thresholds were breached. Today, the shift toward cloud computing, containerization, and continuous delivery has made infrastructure too dynamic for manual oversight, driving the evolution toward automated, algorithmic system management.
The Growing Complexity of Modern Infrastructure
Modern corporate networks are massive webs of interconnected components. A single customer transaction might journey through a mobile application, pass through multiple public and private cloud providers, communicate with microservices, and fetch data from legacy databases.
This distributed architecture creates an overwhelming volume of operational data. Because these components change constantly through automated deployments, understanding how a change in one microservice affects another becomes nearly impossible without intelligent assistance.
Why Traditional Monitoring Approaches Fail
Traditional monitoring tools operate on rigid, rule-based thresholds. For example, an administrator might configure a system to trigger an alert if CPU usage exceeds 85 percent.
However, this approach fails in dynamic cloud environments. A brief spike in CPU usage might be completely normal during a midday processing cycle, yet it still triggers an unnecessary alert. Traditional tools tell you when something is broken, but they fail to correlate data across different layers to tell you why it broke, leading to fragmented visibility.
Core Components of AIOps Platforms
Big Data and Event Correlation
An effective platform acts as a massive data sponge. It ingests both structured and unstructured data from across the enterprise, including performance metrics, system logs, network traffic patterns, and ticketing histories.
Once this data is centralized, the platform uses event correlation to group related events together. Instead of sending fifty separate alerts for fifty different affected components, the platform recognizes they are all tied to a single root incident, presenting them as a single actionable case.
Machine Learning and Predictive Analytics
Machine learning algorithms are the brain of the operation. Unlike humans, these mathematical models can analyze millions of data points simultaneously to establish a baseline of “normal” behavior.
Once the baseline is established, predictive analytics can identify subtle anomalies that precede a system failure. For instance, a banking system using predictive analytics can identify minor memory leaks and performance degradation hours before customer transactions are actually blocked.
Monitoring and Observability
While monitoring tells you that a system is malfunctioning, observability helps you understand its internal state by analyzing its outputs.
An advanced platform enhances observability by combining three critical data types, often called the pillars of observability: metrics, logs, and traces. By analyzing these elements together, the platform provides deep visibility into complex software environments, mapping out exactly how data flows through various application components.
Automation and Orchestration
Real insight is only valuable if it leads to swift action. The automation and orchestration component bridges the gap between discovering a problem and fixing it.
When an issue is identified, the platform can trigger automated scripts or orchestrate workflows across different software tools. This ensures that routine issues are resolved instantly without human intervention, drastically reducing the overall time to resolution.
Root Cause Analysis Engines
When a major incident occurs, finding the source can feel like searching for a needle in a digital haystack. Root cause analysis engines automatically trace the ripple effects of an issue back to its origin.
By analyzing topology maps and historical dependency paths, the engine can pinpoint the exact change, such as a misconfigured network switch or a faulty code deployment, that started the chain reaction.
Key Steps for Implementing AIOps in Enterprise IT Operations
Step 1 — Assess Existing IT Infrastructure
Before deploying any intelligent software, you must evaluate your current technological footprint. Document all your current monitoring tools, cloud assets, legacy servers, and data repositories.
Identify where your data lives and where visibility gaps exist. For example, a global e-commerce company must map out every system involved in their checkout pipeline to ensure their new analytics platform can access data from every single touchpoint.
Step 2 — Centralize Operational Data
To train machine learning models effectively, you need to break down data silos. Collect your logs, metrics, configuration changes, and incident tickets into a centralized data lake.
This unified repository ensures that the underlying AI algorithms have a holistic view of the organization. Without this centralization, your analytical models will remain blind to cross-departmental infrastructure dependencies.
Step 3 — Implement Observability and Monitoring
With data sources connected, deploy comprehensive observability frameworks across your applications and infrastructure. Ensure that your systems are generating high-quality telemetry data.
Imagine an enterprise IT team receiving thousands of alerts daily and struggling to identify the actual root cause. By establishing robust observability at this stage, you clean up the baseline data, ensuring the upcoming AI layer receives clear signals rather than meaningless background noise.
Step 4 — Introduce AI and Machine Learning Models
Now, introduce the analytical models to your centralized data. Start by letting the algorithms observe your daily operations for a few weeks to learn behavioral patterns and historical baselines.
Gradually activate anomaly detection algorithms to flag unusual behavior. During this phase, engineering teams should fine-tune the models, validating correct detections and flagging false positives to improve algorithmic accuracy over time.
Step 5 — Automate Incident Response Workflows
Once the platform accurately identifies issues, begin connecting it to automated remediation workflows. Start small with low-risk, repetitive operational tasks.
Operational Scenario: If a non-critical application server runs out of disk space due to temporary log accumulation, configure the platform to automatically run a cleanup script to clear the cache, rather than waking up an on-call engineer in the middle of the night.
Step 6 — Continuously Optimize Operational Processes
Implementation is an ongoing cycle of refinement, not a one-time project. Regularly review performance reports generated by the platform to identify recurring infrastructure weaknesses.
Use these long-term insights to redesign unstable systems, adjust automated workflows, and update operational playbooks, ensuring your IT ecosystem grows more resilient every day.
Benefits of Implementing AIOps
Faster Incident Detection
Traditional setups rely on human eyes noticing a dashboard change or a user submitting a complaint ticket. An AI-driven approach scans telemetry data in real-time, detecting micro-anomalies long before they trigger a hard threshold breach. This cuts detection times down from hours to mere seconds.
Reduced Alert Fatigue
By correlating hundreds of related events into a single, unified incident ticket, platforms significantly reduce the daily volume of notifications sent to engineers. Teams can finally escape the endless cycle of meaningless pings and focus their full energy on resolving genuine, high-priority system threats.
Predictive Problem Resolution
Instead of simply reacting to outages, businesses can use predictive capabilities to stop incidents before they manifest. If an algorithm detects that a storage array is degrading at an accelerating pace, it can automatically schedule a maintenance window or migrate data to a healthy drive before any data corruption occurs.
Improved System Reliability
Consistent uptime is crucial for enterprise survival. Because intelligent platforms constantly monitor, predict, and remediate performance issues, overall system availability skyrockets. This proactive care directly translates to fewer major outages and more stable digital services.
Better Resource Utilization
Cloud environments often suffer from over-provisioning, where companies pay for extra server capacity they rarely use just to handle unexpected traffic spikes. AIOps platforms analyze usage patterns over time, automatically scaling cloud resources up during peak hours and down during quiet periods to optimize operational costs.
Enhanced Customer Experience
When corporate backend systems run smoothly, customers enjoy seamless digital interactions. Whether it is a mobile banking transaction processing instantly or a retail website loading without delay, automated backend optimization directly protects customer satisfaction and brand loyalty.
Operational Scalability for Hybrid and Cloud Environments
As enterprises expand across hybrid and multi-cloud environments, human teams cannot scale proportionally to manage the new infrastructure footprint. An automated operations layer acts as a force multiplier, allowing small engineering teams to effectively oversee vast, highly complex multi-cloud ecosystems.
Real-World Use Cases of AIOps
AIOps in Cloud Infrastructure
In massive cloud deployments, tracking virtual machines, serverless functions, and microservices is incredibly complex. For instance, AIOps platforms can automatically correlate infrastructure logs, metrics, and events to reduce troubleshooting time across cloud platforms. If a specific cloud node fails, the platform can automatically reroute traffic and launch a replacement instance without human intervention.
AIOps for Financial Services
Banks and financial institutions handle billions of time-sensitive transactions daily. A global financial firm can use intelligent operations platforms to monitor transaction pipelines, ensuring that latency spikes are detected and neutralized immediately, preserving compliance metrics and preventing costly transaction drops.
AIOps in E-Commerce Platforms
During major online sales events, e-commerce infrastructure experiences massive traffic surges.
As shown above, a retail platform can use automated monitoring to detect micro-latencies in the checkout funnel, instantly scaling database instances to prevent abandoned shopping carts and lost revenue.
AIOps for Telecom Networks
Telecom providers manage vast physical networks spanning thousands of cell towers and routers. By applying predictive analytics to hardware telemetry, telecom operators can anticipate component wear and tear, deploying field technicians to service equipment before local voice and data networks experience an outage.
AIOps in Healthcare IT Systems
In modern medical facilities, patient data systems must remain online around the clock. Healthcare networks utilize intelligent operations frameworks to monitor electronic health record databases and connected medical devices, ensuring clinical staff always have uninterrupted access to critical patient life-support data.
Common Challenges During AIOps Implementation
Poor Data Quality
Machine learning models are only as good as the data they consume. If an enterprise feeds its platform fragmented logs, missing metrics, or inconsistent timestamps, the algorithm will generate inaccurate insights, proving the old adage: garbage in, garbage out.
Siloed Monitoring Systems
Many large corporations feature separate teams for networking, databases, and applications, with each department using its own separate monitoring software. Breaking down these operational silos and convincing teams to share their data streams into a single platform can be a major organizational hurdle.
Resistance to Automation
Staff members are sometimes hesitant to hand over operational control to automated systems, fearing that an algorithm might make a catastrophic mistake or make their job redundant. Overcoming this cultural barrier requires clear communication, training, and a gradual approach to automation.
Integration Complexity
Connecting an advanced analytics platform with old, legacy mainframe systems can be technically challenging. Legacy software often lacks modern data export capabilities, requiring customized scripts or specialized middleware to bridge the technological gap.
Lack of Skilled Professionals
Because this field sits at the intersection of data science, cloud architecture, and traditional IT systems management, finding professionals who understand both machine learning concepts and operational infrastructure can be difficult and expensive.
Managing False Positives and Alert Noise
During the initial deployment phase, machine learning models are still learning what constitutes normal behavior. If the models are not tuned properly, they may misinterpret minor anomalies as major crises, creating an initial wave of false positives that can frustrate engineering teams.
Best Practices for Successful AIOps Adoption
Start with Clear Operational Goals
Do not deploy artificial intelligence simply for the sake of using a modern buzzword. Define specific, measurable business goals, such as reducing mean time to repair by twenty percent, or automating half of your password reset tickets within the first six months.
Focus on Observability First
Before letting machine learning algorithms loose on your environment, ensure your underlying infrastructure is fully visible. Clean up your logs, standardize your metric collection, and fix broken data paths. A solid data foundation is essential for analytical success.
Build Cross-Functional Collaboration
Form a dedicated team that includes cloud engineers, data scientists, database administrators, and security specialists. This cross-functional group ensures that the implementation benefits the entire organization rather than just a single IT department.
Continuously Train AI Models
Business environments change constantly due to software updates and changing user habits. Treat your machine learning models as living entities. Regularly feed them fresh operational data and update their training parameters to ensure they adapt to your evolving business landscape.
Prioritize Automation Gradually
Build trust in automation by starting with low-risk, repetitive tasks. Allow the system to suggest fixes to human operators first. Once those recommendations prove consistently accurate over several weeks, grant the platform permission to execute those remediations automatically.
Monitor Outcomes and Improve Continuously
Regularly evaluate your implementation metrics against your initial business goals. Analyze which automated workflows are succeeding, which alerts are still creating noise, and where data visibility is lacking, using those insights to continuously refine the platform.
Essential Tools and Technologies in AIOps
Monitoring and Observability Platforms
These tools serve as the sensory nervous system of your enterprise, collecting and organizing raw telemetry data from applications, cloud environments, and physical servers. They provide the comprehensive datasets that advanced analytical engines need to perform deep root cause analysis.
Incident Management Systems
Once an issue is detected, these platforms orchestrate communication and log corporate workflows. They track tickets from creation to closure, alerting relevant teams, maintaining incident histories, and managing on-call engineer schedules during critical system events.
Automation and Orchestration Tools
These specialized engines execute the technical solutions required to fix problems. When an analytics platform identifies a solution, it instructs orchestration tools to deploy code updates, restart services, clear disk space, or adjust cloud network configurations automatically.
AI and Analytics Engines
The analytical core of the system utilizes advanced machine learning frameworks to parse massive volumes of telemetry data. These specialized engines perform the complex mathematical calculations required for anomaly detection, future event forecasting, and pattern recognition.
Cloud and Hybrid Infrastructure Platforms
Modern infrastructure platforms provide the underlying computing environments where automated operations thrive. They feature programmable interfaces that allow intelligent operations software to adjust computing resources, spin up new environments, and reconfigure networks on the fly.
AIOps vs Traditional IT Operations
| Feature | Traditional IT Operations | AIOps-Driven IT Operations |
| Data Analysis | Manual, siloed review of separate dashboards. | Automated, centralized correlation across all layers. |
| Problem Solving | Reactive firefighting after systems crash. | Proactive and predictive remediation before failure. |
| Alert Management | High alert noise and severe alert fatigue. | Consolidated, context-rich single incident tickets. |
| Automation Level | Manual scripts triggered by human operators. | End-to-end intelligent orchestration and self-healing. |
| Cloud Scalability | Limited scalability due to human constraints. | Infinite adaptability to complex multi-cloud setups. |
Career Opportunities in AIOps
Skills Required for AIOps Engineers
To thrive in this evolving landscape, professionals must develop a unique hybrid skillset. You need a strong understanding of traditional systems administration, combined with proficiency in scripting languages like Python or Go. Additionally, familiarity with cloud platforms, container tools like Kubernetes, and basic data science concepts is highly valuable.
Popular Job Roles
The rise of automated operations has created several exciting, high-paying career paths within enterprise IT, including:
- AIOps Systems Engineer: Specializes in deploying and maintaining the platform infrastructure.
- Observability Specialist: Focuses on configuring data pipelines, metrics, and tracing telemetry.
- Site Reliability Engineer (SRE): Uses automation to ensure large-scale systems remain available and reliable.
- Automation Architect: Designs the cross-tool workflows that allow systems to self-heal automatically.
Certifications and Learning Paths
Professionals looking to advance should pursue certifications focused on cloud architecture, big data analytics, and modern devops methodologies. Earning credentials from major public cloud vendors, along with specialized certifications in data science and automated configuration management, will make you highly competitive in the job market.
Learning Resources from TheAIOps.com
Staying ahead of infrastructure trends requires access to high-quality educational material. Industry professionals can utilize the comprehensive guides, expert architectural breakdowns, and platform tutorials available at TheAIOps.com to sharpen their automation skills and master the nuances of deploying machine learning models within enterprise infrastructure.
Future of Enterprise IT Operations with AIOps
Self-Healing Infrastructure
The ultimate destination of modern operations is fully self-healing infrastructure. In this future state, human engineers will rarely step in to fix routine errors. The digital environment will autonomously detect its own weaknesses, patch its own bugs, and reconfigure its own layout to survive massive hardware failures seamlessly.
Intelligent Automation
Future automation frameworks will move beyond basic pre-written scripts. Advanced platforms will synthesize unique, context-aware solutions on the fly, writing their own remediation code safely in isolated sandboxes before applying it to fix novel system bugs in real-time.
AI-Driven Root Cause Analysis
Root cause determination will become instantaneous. Future analytical layers will understand software source code as deeply as human developers do, allowing them to pinpoint the exact line of faulty code responsible for a global system slow-down the very second the latency begins.
Predictive Operations
Tomorrow’s enterprise IT will operate entirely in the future tense. Management platforms will run continuous simulations of network traffic, user behavior, and software performance, predicting operational issues weeks in advance and adjusting systems proactively to avoid any real-world disruption.
Autonomous Cloud Management
As multi-cloud ecosystems grow increasingly vast, autonomous cloud management will take over resource allocation entirely. Intelligent agents will continuously move data and computing workloads across different global cloud providers in real-time to capitalize on the best financial rates, processing speeds, and security compliance.
FAQ Section
- What is the difference between DevOps and AIOps?
DevOps focuses on breaking down organizational walls between software development and IT operations teams to deliver code updates faster and more reliably. AIOps enhances this methodology by providing artificial intelligence and machine learning insights that help those teams automate and optimize system performance across production environments.
2. How does AIOps help reduce alert fatigue for IT teams?
It acts as an intelligent filter by ingesting thousands of raw system notifications and analyzing their timestamps, origins, and descriptions. It correlates related alerts tied to the same underlying problem into a single, comprehensive incident ticket, eliminating repetitive background noise.
3. Can AIOps platforms replace human IT operations engineers?
No, it is designed to empower human engineers, not replace them. By automating repetitive troubleshooting tasks and filtering alert noise, the platform frees technology professionals from tedious firefighting, allowing them to focus on strategic design, security architecture, and system innovation.
4. What types of data does an AIOps platform collect?
The platform ingests a wide variety of data streams from across the enterprise ecosystem. This includes system performance metrics, raw text logs, application trace paths, network traffic data, hardware configuration records, and historical human helpdesk ticketing data.
5. How long does it take to see results from an AIOps implementation?
Initial benefits, such as basic data centralization and event correlation, can often be seen within a few weeks of deployment. However, full predictive analytics and reliable automation workflows typically require a few months of continuous data collection to properly train the machine learning models.
6. Is AIOps suitable for small and medium-sized enterprises?
While large corporations with massive, complex multi-cloud networks realize the greatest return on investment, medium-sized businesses with growing digital infrastructures can also benefit significantly by adopting foundational monitoring practices early to scale efficiently without overloading their IT staff.
Conclusion
Transitioning to automated operations represents a monumental leap forward for modern corporate technology management. By addressing real-world operational bottlenecks like alert noise and siloed monitoring visibility, organizations can successfully shift from chaotic, reactive firefighting to a streamlined state of predictive system management. Successfully implementing this framework requires a structured approach: assessing your existing assets, centralizing data streams, establishing deep system observability, and introducing machine learning models gradually before turning on automated remediation.